| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
以下のコードの出力として正しいものを選べ
import pandas as pd
df_1 = pd.DataFrame({'a': [10, 100], 'b': [10, 20], 'c': [10, 1]})
df_2 = pd.DataFrame({'a': [10, 100], 'b': [10, 20], 'c': [10, 1]})
pd.concat([df_1, df_2], axis=0).reset_index(drop = True)
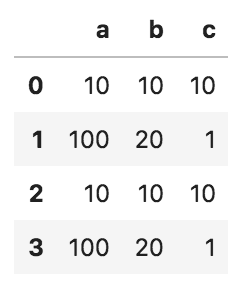
①
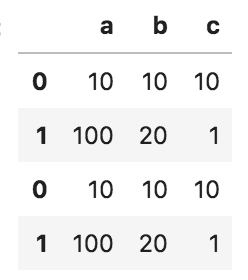
②
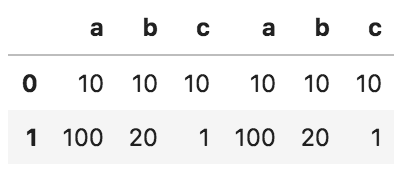
③
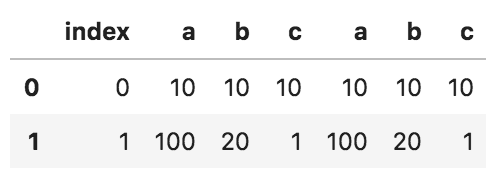
④
①
②
③
④
問2
matplitlibのpieメソッドを用いて円グラフを影をつけて表示させる場合の、pieメソッド内で指定する引数として正しいものを選べ
shadow=True
counterclock=True
explode=True
frame=True
問3
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.full((2,2),1)
B = np.zeros((2,2))
np.concatenate([A, B], axis=0)
array([[1., 1.], [1., 1.], [0., 0.], [0., 0.]])
array([[1., 1., 0., 0.], [1., 1., 0., 0.]])
array([[1., 0.], [1., 0.], [1., 0.], [1., 0.]])
実行不可(エラーが出る)
問4
以下のような、日付ごとの利用状況が格納されたデータフレームdfがある。
日付をインデックスではなく、新たなカラムとして作成するためのコードとして正しいものを選べ
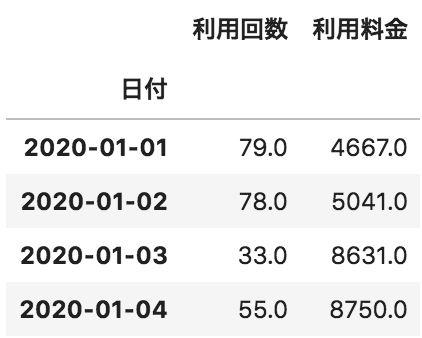
df.reset_index()
①
df.resetindex()
②
df["日付"].set_index()
③
df["日付"].reset_index()
④
①
②
③
④
解説
現在のインデックスを新たなカラム(列)にするには reset_index() を使います。これを使うとインデックスは連番になります。
問5
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
性別ごとの人数を棒グラフで表示するためのコードとして正しいものを選べ
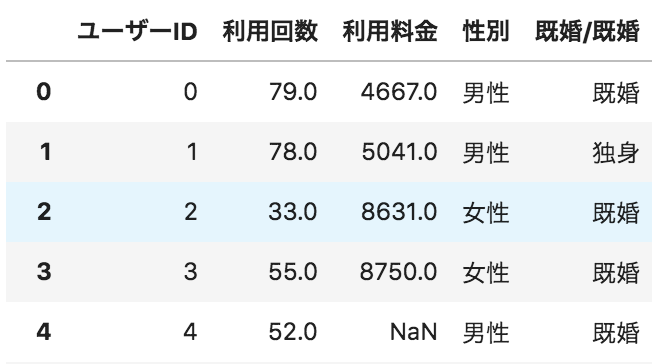
import matplotlib.pyplot as plt
df["性別"].value_counts().plot.bar()
plt.show()
①
import matplotlib.pyplot as plt
df["性別"].plot.bar()
plt.show()
②
import matplotlib.pyplot as plt
plt.bar(df["性別"].value_counts())
plt.show()
③
import matplotlib.pyplot as plt
df["性別"].value_counts().bar()
plt.show()
④
①
②
③
④
問6
scikit-learnのDesicionTreeClassifierモジュールを使用する場合に引数として指定できないものを選べ
木の数
木の深さ
葉の数
不純度の指標
問7
set型のデータに関して説明している以下の文章のうち、正しいものを選べ
標準のデータ型にはなく、使う場合はモジュールをインポートする必要がある
重複しない要素を含み、集合演算をする場合に用いられる
イミュータブルなデータ型であり、要素の追加や削除はできない
データの各要素が、keyとvalueという2組みのデータから成り立ち、それぞれ取り出すことができる
問8
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[0, 1, 2, 3, 4]])
B = np.full((1, 5), 2)
np.sum(A>=B)
3
10
9
4
問9
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.flatten()
A[1,:]=0
B[-1]
array([0, 0, 0])
6
array([6])
array([4, 5, 6])
問10
以下のような各日付に対して、利用回数と利用料金が格納されたデータフレームdfがある。このdfの欠損値をカラムごとの平均値で埋める処理として正しいものを選べ
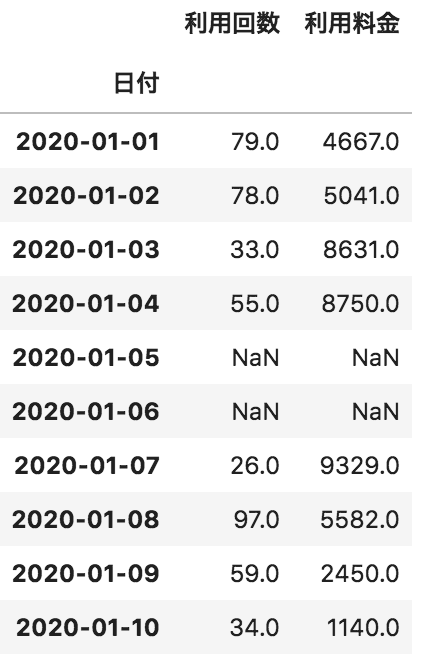
df.fillna(0)
df.dropna(0)
df.fillna(df.mean())
df.fillna(df.sum())
問11
reモジュールについて説明している以下の文章のうち、正しいものを選べ
デバッグ機能を利用するためのモジュールである
機械学習アルゴリズムを用いたモデルを構築する際に使用するモジュールである
微分や積分などの高度な数式演算を行うためのモジュールである
正規表現を扱うためのモジュールである
問12
特徴量の次元削減について説明している以下の文章のうち、正しいものを選べ
なるべくデータの情報を落とさずに、少ない特徴量でデータを表現するために用いられる
次元削減の手法には非線形変換を行う手法のみ存在する
scikit-learnで実装されている主成分分析を使用する際、次元数をいくつまで削減するかを指定することはできない
数学的には、内部で積分計算を行なっている
問13
datetimeモジュールについて説明している以下の文章のうち、誤っているものを選べ
取得する日付や日時のタイムゾーンを指定することができる
now()を使用することで、今日の日付を取得することができる
日数の差分を算出するなど、日付同士の演算をすることができない。
日時(datatime型)→文字列の変換はできるが、文字列→日時(datatime型)の変換はできない
問14
以下のコードを実行した場合にBに格納されているものとして正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.ravel()
A[0,:]=0
array([1, 2, 3, 4, 5, 6])
array([0, 2, 3, 0, 5, 6])
array([[1, 2, 3, 4, 5, 6]])
array([0, 0, 0, 4, 5, 6])
問15
以下のコードの出力として正しいものを選べ
A = [x for x in range(10)]
B = {x for x in range(20)}
if len(A)==10:
print("A")
elif len(A)==10&len(B)==20:
print("A,B")
else:
print("None")
A
A, B
None
A A, B
問16
以下の文章のうちF値の説明として正しいものを選べ
適合率と再現率の調和平均
正例と予測したデータのうち、実際に正例であるデータの割合
実際の正例のデータのうち正例と予測したデータの割合
予測の正負と実際のデータの正負が一致したデータの割合
問17
pandasのデータフレームの上から5行目までを表示させるメソッドとして、正しいものを選べ。
tail()
head()
view()
show()
問18
以下の文章のうちグリッドサーチの説明として正しいものを選べ
指定したパラメーターの全ての組み合わせを試す手法。組み合わせの総数分モデルの学習を行うので、探索が終わるのに時間がかかる
各パラメーターにおいて指定した分布から無作為に探索値を抽出するので、分布の仮定が間違っていると最適なチューニング結果にならない
パラメーター探索の仮定で、ベイズ推論を行なっているため計算に時間がかかる
どのパラメーターを探索するかはアルゴリズムが自動で選んでくれる
問19
R言語について説明している以下の文章のうち、正しいものを選べ
DeepLearningのフレーワークにはR用のパッケージは存在しない
Rで機械学習モデルを構築する場合、scikit-learnのR用パッケージをインストールしなければならない
R言語はグラフ描画をするためのパッケージが存在しない
RにはC++を使うためのパッケージが存在し、高速化をする際によく用いられる
問20
以下のような、日付に対して番号が格納されているデータフレームdfがある。このデータフレームを水曜日までの1週間単位の番号の合計を出力するコードとして正しいものを選べ
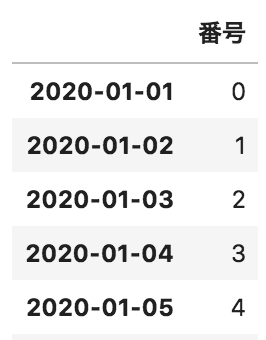
df.groupby(pd.Grouper(freq=”W-WED”)).count()
df.groupby(pd.Grouper(freq=”M-WED”)).sum()
df.groupby(pd.Grouper(freq=”W-WED”)).mean()
df.groupby(pd.Grouper(freq=”W-WED”)).sum()
問21
以下の関数のxに関する微分として正しいものを選べ
1
問22
NumPy配列の要素のデータ型を確認するためのコマンドとして正しいものを選べ。
dtype
dypes
astype
astypes
問23
線形回帰について説明している以下の文章のうち正しいものを選べ
特徴量が5個以上あるデータには用いることができない
過学習することがないので、検証データを用意する必要はない。
分類する予測モデルを構築する際に使用するアルゴリズムである
L1正則化やL2正則化を用いることで過学習を抑えることができる
問24
三角関数でないものを以下の選択肢から選べ
cosx
sinhx
tanx
sinx
問25
以下のようなデータフレームdfがある。このデータフレームのカラム名を変更する際のコードとして正しいものを以下の中から選べ
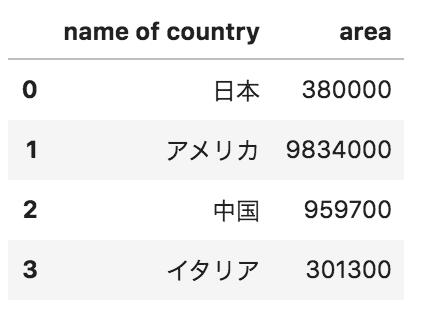
df.rename(columns={“name of country”:”国名”, “area”:”面積”})
df.rename(index={“国名”:”name of country”, “面積”:”area”})
df.rename(column={“国名”:”name of country”, “面積”:”area”})
df.columns({“国名”:”name of country”, “面積”:”area”})
問26
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 0]])
B = np.array([1, 0])
A @ B
array([1])
array([[1]])
array([[1, 1]])
array([[1, 1], [1, 1]])
問27
Pythonについて説明している以下の文章のうち間違っているものを選べ
Pythonで変数を使用する際には、必ず変数の型を最初に定義する必要がある
Pythonはオブジェクト指向のプログラミング言語である
機械学習ライブラリにscikit-learnがある
Pythonの予約語の数は他のプログラミング言語と比較して少ない
問28
A = (1,2,3) B = (4,5,6)の2つの座標がある。座標AB間のユークリッド距離として正しいものを選べ
27
9
3
問29
数値データが格納されたpandasデータフレームに対して、describeメソッドを用いて算出することができない統計量として正しいものを選べ
最大値
外れ値
平均値
データ件数
問30
勾配ブースティングの手法として正しくないものを選べ
ニューラルネットワーク
LightGBM
Xgboost
Catboost
問31
機械学習を用いたデータ分析について説明している文章のうち、正しいものを選べ
モデルの学習を実施したあとは、適切な検証データ、適切な指標を用いてモデルの精度の良し悪しを判断する必要がある
モデルの学習を実施さえすれば、十分な精度が保証されており、すぐに予測モデルを運用することができる
モデルの良し悪しを決めるための評価指標を適切に選ばなくても機械学習アルゴリズムで使っていれば問題ない
特徴量の選択は、適当に決めても精度に大きな影響はないため、特徴量エンジニアリングに時間を割くべきではな
問32
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
横軸に利用回数、縦軸に利用料金の散布図を描画するためのコードとして正しいものを選べ
①
import matplotlib.pyplot as plt
plt.scatter(df["利用回数"],df["利用料金"])
plt.show()
②
import matplotlib.pyplot as plt
plt.scatter(df["利用料金"],df["利用回数"])
plt.show()
③
import matplotlib.pyplot as plt
plt.plot(df["利用回数"],df["利用料金"])
plt.show()
④
import matplotlib.pyplot as plt
df["利用回数"].scatter(df["利用料金"])
plt.show()
①
②
③
④
問33
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームにその日の株価の増減値(終値-始値)に応じて、ランクを付与するコードの実装として正しいものを選べ
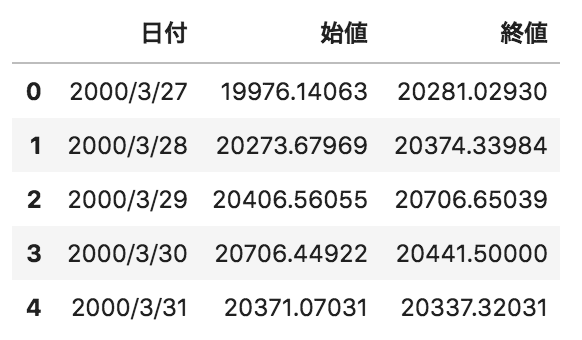
①
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df["増減値"].apply(add_rank)
②
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df.add_rank(df["増減値"])
③
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply(add_rank(df["終値"] - df["始値"]))
④
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply().add_rank(df["終値"] - df["始値"])
①
②
③
④
問34
以下のコードの出力として正しいものを選べ
fig, ax = plt.subplots()
x = [10, 20, 30]
label=[1 ,2, 3]
ax.pie(x, autopct="%1.1f%%", labels=label)
plt.show()
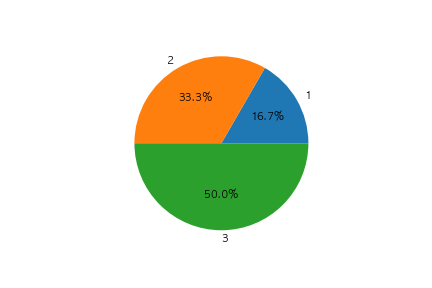
①

②
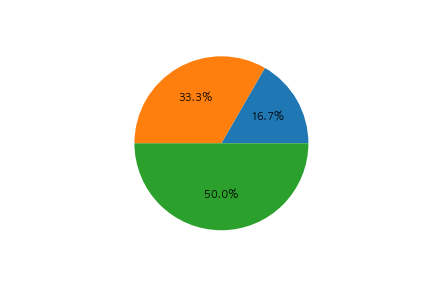
③
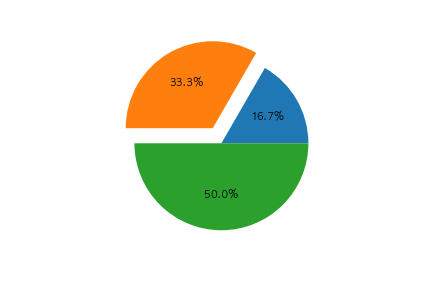
④
①
②
③
④
問35
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A[0,:]
A[0,:]=0
B
array([1, 2, 3])
array([0, 0, 0])
array([[1], [4]])
array([[0], [0]])
問36
np.random.randint(1,11)を繰り返し実行した場合の平均値は、繰り返し回数が多ければ多いほど、ある値に近づいていく。ある値として正しいものを以下の中から選べ。
1
11
3.5
5.5
問37
データエンジニアの業務について説明している以下の文章のうち、間違っているものを選べ
集計ミスがないかの確認をする
データサイエンティストや顧客とコミュニケーションを取る
データベース言語を用いてデータの抽出を行う
機械学習のアルゴリズムを深い領域で理解する
問38
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
サービス利用料金ごとの人数をヒストグラムで表示するためのコードとして正しいものを選べ
import matplotlib.pyplot as plt
df["利用料金"].hist()
plt.show()
①
import matplotlib.pyplot as plt
df["利用料金"].boxplot()
plt.show()
②
import matplotlib.pyplot as plt
df["利用料金"].value_counts().hist()
plt.show()
③
import matplotlib.pyplot as plt
plt.bar(df["利用回数"], df["ユーザーID"])
plt.show()
④
①
②
③
④
問39
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームにその日の株価の増減値(終値-始値)を算出したカラムを追加するコードとして間違っているものを選べ
df.loc[:,”増減値”] = df.loc[:,”終値”] – df.loc[:,”始値”]
df.loc[:,”増減値”] = df.iloc[:,2] – df.iloc[:,1]
df[“増減値”] = df[“終値”] – df[“始値”]
df.loc[:,”増減値”] = df.loc[[“終値”]-[“始値”]]
問40
回帰予測に関する以下の説明のうち、間違っているものを選べ
ロジスティック回帰で予測している値は、目的変数であるラベルそのものである
使用する特徴量の数が1つの場合の回帰を単回帰と呼ぶ
使用する特徴量が2つ以上の回帰を重回帰と呼ぶ
回帰に用いる損失関数にRMSE(最小2乗誤差)がある