| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
pipを用いてXXXXというパッケージをアンインストールする場合に使用するコマンドとして正しいものを選べ
pip remove XXXX
pip uninstall XXXX
pip detach XXXX
pip demount XXXX
問2
以下のような、日付ごとの利用状況が格納されたデータフレームdfがある。
日付をインデックスではなく、新たなカラムとして作成するためのコードとして正しいものを選べ
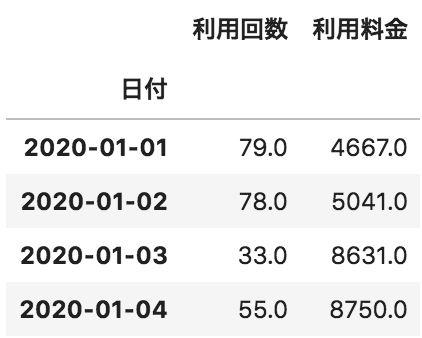
df.reset_index()
①
df.resetindex()
②
df["日付"].set_index()
③
df["日付"].reset_index()
④
①
②
③
④
問3
以下のような日付ごとの利用回数と利用料金が格納されたpandasデータフレームdfがある。このデータフレームdfの中から利用回数が最大のレコードを抽出するコードとして正しいものを選べ
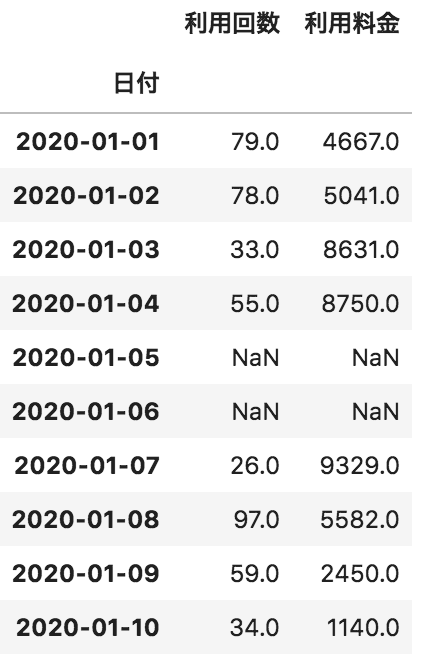
df[df[“利用回数”].max()]
df[df[“利用回数”]==df[“利用回数”].min()]
df[“利用回数”].max()
df[df[“利用回数”]==df[“利用回数”].max()]
解説
以下のコードを実行すると
1 |
df["利用回数"] == df["利用回数"].max() |
0 True
1 False
2 False
利用回数が最大のものと一致しているかどうかの真偽値のSeriesを返します。
その結果をもとのデータフレームを絞り込むために使うとTrueの箇所に対応したデータを取得できます。今回の場合は最大値に一致するデータです。
問4
データサイエンティストの役割について説明している以下の文章のうち、正しいものを選べ
データ分析さえできればよく、顧客の立場になり、その分析結果をどう使えるかまでを考えて分析する必要はない
技術の進歩が速い分野なので、論文などを読んで最新技術をキャッチアップする必要がある
Pythonで実装できるモデルを扱うことが多く、R言語を知っておく必要はない
業務中に自分でPCを修理する場合もあるので、コンピューターの内部構造や動作原理などを知っておく必要がある
問5
以下のような、日付に対して番号が格納されているデータフレームdfがある。このデータフレームを水曜日までの1週間単位の番号の合計を出力するコードとして正しいものを選べ
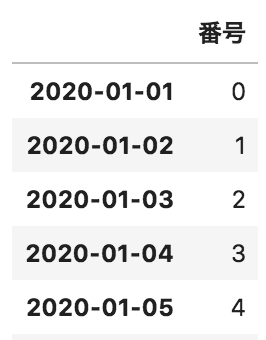
df.groupby(pd.Grouper(freq=”W-WED”)).count()
df.groupby(pd.Grouper(freq=”M-WED”)).sum()
df.groupby(pd.Grouper(freq=”W-WED”)).mean()
df.groupby(pd.Grouper(freq=”W-WED”)).sum()
問6
以下のコードを実行すると、変数A, B, C, Dには1つだけ異なるデータが格納される(4つのうち3つは同じデータが格納される)。格納されているデータが他の変数と異なる変数を選べ。
import numpy as np
A = np.full(10, 10.0)
B = np.array([10])*10
C = np.zeros(10)+10
D = np.ones(10)*10
C
B
A
D
問7
機械学習アルゴリズムにおける、ハイパーパラメーターの説明として正しいものを以下の中から選べ
学習時にアルゴリズムで決定されず、モデル構築者が指定する必要があるパラメーター
学習時に機械学習アルゴリズムにより最適化される値
モデルの評価指標に使用されるパラメーター
モデルの損失関数に使用されるパラメーター
問8
以下のコードを実行した際の出力として、正しいものを選べ
import numpy as np
a = np.array([0,1,10,100])
c = a.flatten()
c[0] = 1000
a == c
array([False, True, True, True])
array([True, True, True, True])
array([False, True, True, False])
FALSE
問9
以下の説明文のうち、線形回帰の中で微分が使用される理由として正しいものを選べ
損失関数と呼ばれる関数を最小にするパラメーターを求める際に必要だから
損失関数と呼ばれる関数が描く面積を求める際に必要だから
仮定関数を決める際に必要だから
予測結果の妥当性を検証する際に必要だから
問10
import pandas as pd
df = pd.DataFrame({"国名":["日本","アメリカ","中国","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"面積":[380000, 9834000, 959700, 301300, 643800, 17100000, 8516000, 242500],
"人口/万人":[12700, 32800, 139300, 6000, 6700, 14500, 20900, 6600]})
上記コードを実行すると、以下のようなデータフレームが作成される。このデータフレームから中国のみのデータフレームを抜き出す処理として正しいものを選べ
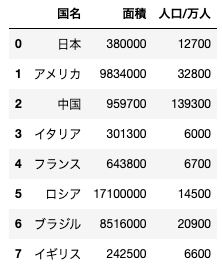
df.sort_values(“人口/万人”, ascending=True).iloc[-1,:]
df[df[“国名”]!=”中国”]
df[df.index==2]
df[“国名”]==”中国”
問11
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
問12
決定木について説明している以下の文章のうち、正しいものを選べ
情報利得の大きい順に特徴量が使用され、木が作られる
木が下に行けば行くほど、特徴量の情報利得は大きい
各葉においてデータを分割する際の閾値はあらかじめモデル作成者が決める必要がある
欠損値は除外するか、何かしらの値で埋めておく必要がある
問13
csvファイルをpandasで読み込む場合に、読み込むカラムを指定する方法として正しいものを選べ
※選択肢中の’data.csv’ は読み込む元データが格納されたcsvファイルとする
pd.read_csv(‘data.csv’, usecols=[カラム名])
pd.read_csv(‘data.csv’, index_col=[カラム名])
pd.read_csv(‘data.csv’, use_cols=[カラム名])
pd.read_csv(‘data.csv’, cols=[カラム名])
問14
データエンジニアに求められる能力として必須ではないものを選べ
論文の読解能力
SQLなどのデータベース言語を扱う能力
前処理や特徴量エンジニアリングのための扱っているデータの専門知識
データ分析の要件を理解すること
問15
以下のコードの出力として、正しいものを選べ
A = [1,2,3]
sum_num = 0
for num in A:
sum_num += num
print(sum_num)
0
sum_num
3
6
問16
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.arange(10)
A.reshape(5,2)
array([[0, 1], [2, 3], [4, 5], [6, 7], [8, 9]])
array([[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
array([[10, 10], [10, 10], [10, 10], [10, 10], [10, 10]])
array([[10, 10, 10, 10, 10], [10, 10, 10, 10, 10]])
問17
以下のコードを実行した際の出力として正しいものを選べ
import copy
A = [1,2,3]
B = A.copy()
A.append(4)
B
[1,2,3,4]
[1,2,3]
[[1,2,3],[1,2,3]]
[ ]
問18
以下の文章のうちグリッドサーチの説明として正しいものを選べ
指定したパラメーターの全ての組み合わせを試す手法。組み合わせの総数分モデルの学習を行うので、探索が終わるのに時間がかかる
各パラメーターにおいて指定した分布から無作為に探索値を抽出するので、分布の仮定が間違っていると最適なチューニング結果にならない
パラメーター探索の仮定で、ベイズ推論を行なっているため計算に時間がかかる
どのパラメーターを探索するかはアルゴリズムが自動で選んでくれる
問19
データエンジニアの役割について説明している以下の文章のうち、間違っているものを選べ
データベースの扱いは、サーバーサイドエンジニア が知っていればよく、SQLなどのデータベースを扱う言語をデータ分析者が知っておく必要はない
機械学習だけでなく、深層学習についても知っておく必要がある
データ数が100サンプルのデータを扱うこともありえる
クラウドサービスを用いてデータハンドリングを行う場合、金銭的、時間的コストを考えてコードを実装する必要がある
問20
データサイエンティストの役割について説明している以下の文章のうち、正しいものを選べ
技術の進歩が速い分野なので、論文などを読んで最新技術をキャッチアップする必要がある
Pythonで実装できるモデルを扱うことが多く、R言語を知っておく必要はない
業務中に自分でPCを修理する場合もあるので、コンピューターの内部構造や動作原理などを知っておく必要がある
データ分析さえできればよく、顧客の立場になり、その分析結果をどう使えるかまでを考えて分析する必要はない
問21
Anacondaで特定のライブラリ(XXXX)のバージョンを更新する際に使用するコマンドとして正しいものを選べ。
conda update XXXX
conda upgrade XXXX
conda install XXXX
conda build XXXX
問22
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
問23
pip freeze コマンドの説明として正しいものを選べ
インストールされているパッケージの一覧を出力する
pipのバージョンを最新にする
実行中のpipコマンドを強制終了するコマンド
現在のpipのバージョンを出力するコマンド
問24
以下のコードを実行した後に、np.hstack((a,b))を実行した場合の出力と同じにするにはどれを実行すれば良いか?正しいものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = np.array([[100],[100]])
np.concatenate([a,b],axis=0)
np.concatenate([a,b],axis=1)
np.vtack([a,b])
np.append(a,b)
問25
確率密度関数と確率の関係として正しいものを以下の中から選べ。
確率は確率密度関数の勾配である。
確率は確率密度関数の面積である。
確率は確率密度関数の幅の広さである。
確率は確率密度関数の最大値である。
問26
A+Bが計算できない組み合わせとして、正しいものを以下の中から選べ。
A = np.array([[0,1,2]]) B = np.ones((3,1))
A = np.array([[0,1,2]]) B = np.ones((3,2))
A = np.array([[0,1,2]]) B = np.ones((1,3))
A = np.array([[0,1,2]]) B = np.ones((2,3))
問27
以下のようなデータフレームdfがある。このデータフレームのカラム名を変更する際のコードとして正しいものを以下の中から選べ
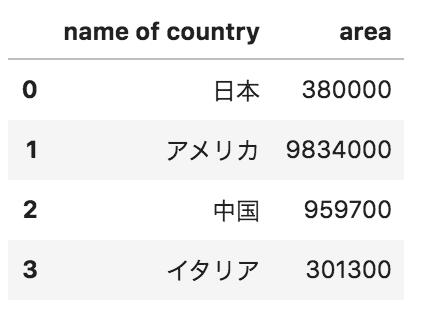
df.rename(columns={“name of country”:”国名”, “area”:”面積”})
df.rename(index={“国名”:”name of country”, “面積”:”area”})
df.rename(column={“国名”:”name of country”, “面積”:”area”})
df.columns({“国名”:”name of country”, “面積”:”area”})
問28
以下の文章のうち次元削減手法として適切でないものを選べ
k-means法
主成分分析(PCA)
線形判別分析(LDA)
t-SNE
問29
A = (1,2,3) B = (4,5,6)の2つの座標がある。座標AB間のユークリッド距離として正しいものを選べ
27
9
3
問30
Jupyter Notebookで用いられるマジックコマンドについて説明している以下の文章のうち、間違っているものを選べ
%timeitはセルに書かれた一行のプログラムに対して実行時間を、複数回施行して計測するコマンドである
%%timeitは1つのセルに対して実行時間を、複数回施行して計測するコマンドである
%matplotlib tk はコードセル直下にグラフを出力するためのコマンドである
%lsmagicはマジックコマンドの一覧を表示するコマンドである
問31
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームにその日の株価の増減値(終値-始値)を算出したカラムを追加するコードとして間違っているものを選べ
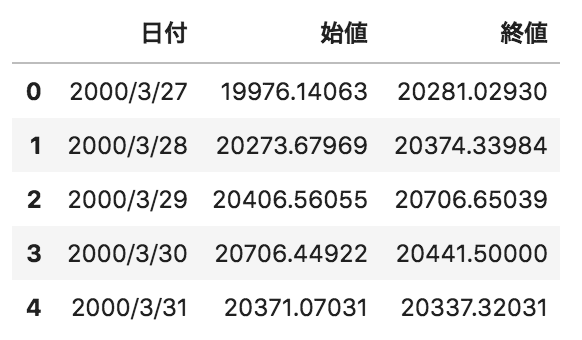
df.loc[:,”増減値”] = df.loc[:,”終値”] – df.loc[:,”始値”]
df.loc[:,”増減値”] = df.iloc[:,2] – df.iloc[:,1]
df[“増減値”] = df[“終値”] – df[“始値”]
df.loc[:,”増減値”] = df.loc[[“終値”]-[“始値”]]
問32
以下の関数のxに関する微分として正しいものを選べ
1
問33
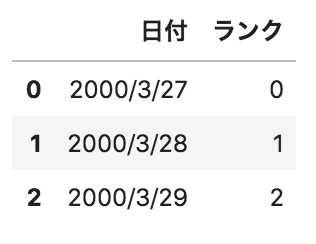
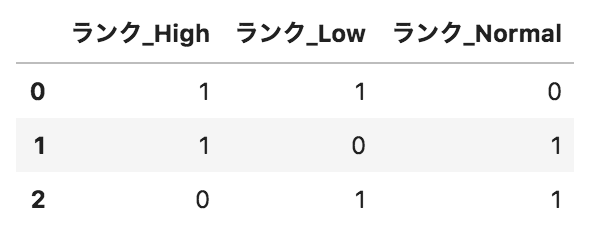
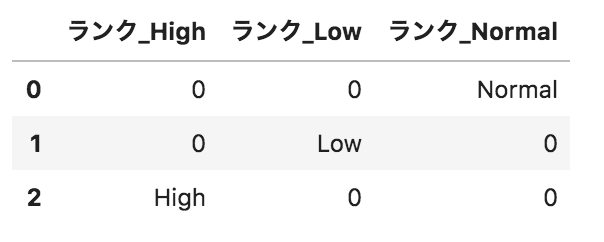
以下のようなpandasデータフレームdfがある。このデータフレームに対して、
pd.get_dummies(df.loc[:,"ランク"],prefix="ランク")
を実行した場合の出力として正しいものを選べ。
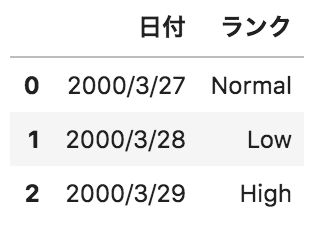
選択肢
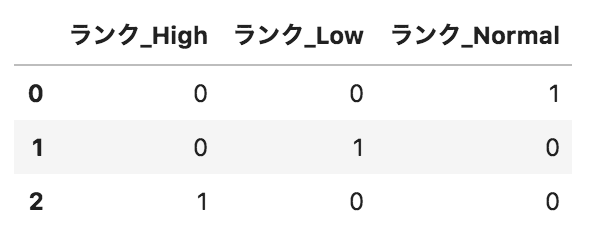
①
②
③
④
①
②
③
④
問34
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
横軸に利用回数、縦軸に利用料金の散布図を描画するためのコードとして正しいものを選べ
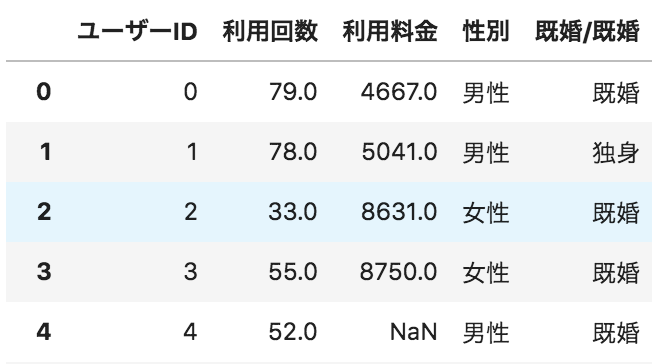
①
import matplotlib.pyplot as plt
plt.scatter(df["利用回数"],df["利用料金"])
plt.show()
②
import matplotlib.pyplot as plt
plt.scatter(df["利用料金"],df["利用回数"])
plt.show()
③
import matplotlib.pyplot as plt
plt.plot(df["利用回数"],df["利用料金"])
plt.show()
④
import matplotlib.pyplot as plt
df["利用回数"].scatter(df["利用料金"])
plt.show()
①
②
③
④
問35
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
問36
ポアソン分布について述べている以下の文章のうち、正しいものを選べ
ポアソン分布におけるパラメーターは、平均値と標準偏差である。
交通事故の発生回数の予測、機械部品の故障予測など、稀に生じる事象についてモデル化したい場合に用いられる、離散型の確率分布である。
二項分布における試行回数と平均値が∞に発散する場合の極限を計算することで、ポアソン分布の確率密度関数は得られる
確率変数の実現値が連続変数である連続型確率分布である。
問37
機械学習モデルの精度改善をする場合の措置として間違っているものを選べ
評価指標を変更する
学習データ量を増やす
ハイパーパラメーターのチューニング
特徴量の選定
問38
以下のような出力をするコードとして正しいものを選べ
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08',
'2020-01-09', '2020-01-10', '2020-01-11', '2020-01-12',
'2020-01-13', '2020-01-14', '2020-01-15', '2020-01-16',
'2020-01-17', '2020-01-18', '2020-01-19', '2020-01-20',
'2020-01-21', '2020-01-22', '2020-01-23', '2020-01-24',
'2020-01-25', '2020-01-26', '2020-01-27', '2020-01-28',
'2020-01-29', '2020-01-30', '2020-01-31'],
dtype='datetime64[ns]', freq='D')
pd.date(start=”2020-01-01”, end=”2020-1-31”)
pd.date_range(start=”2020-01-01”, end=”2020-1-31”)
pd.date_range([“2020-01-01”, “2020-1-31”])
pd.range(start=”2020-01-01”, end=”2020-1-31”)
問39
以下のグラフは各ユーザーの支払い請求額をx軸、チップをy軸とした散布図である。この散布図の説明として正しいものを選べ
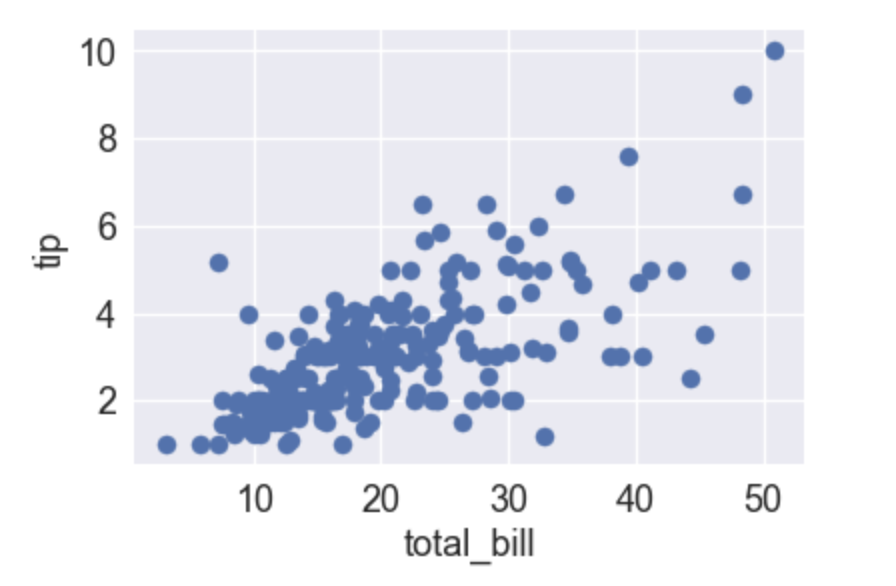
支払い請求額は30~40が最も多いことがわかる
チップが10付近の所に1つデータがあるが、これは外れ値である
支払い請求額とチップには概ね負の相関がある
支払い請求額とチップには概ね正の相関がある
問40
s = ‘DIVE INTO CODE’ という文字列が格納された変数に対する処理の説明として間違っているものを選べ
s.lower()を実行すると、”dive into code”という文字列が返ってくる
s.split()を実行すると、[‘DIVE’, ‘INTO’, ‘CODE’]というリストが返ってくる
s.strip()を実行すると、”DIVEINTOCODE”という文字列が返ってくる
s.replace(‘CODE’, ‘Python’)を実行すると、’DIVE INTO Python’という文字列が返ってくる