| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
ROC曲線の横軸と縦軸が意味するものとして正しい組み合わせを以下の中から選べ
(横軸, 縦軸)= (偽陽性率, 真陽性率)
(横軸, 縦軸)= (真陽性率, 偽陽性率)
(横軸, 縦軸)= (適合率, 再現率)
(横軸, 縦軸)= (再現率, 適合率)
解説
ROC曲線では、横軸に偽陽性率、縦軸に真陽性率をプロットします。
問2
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームにその日の株価の増減値(終値-始値)に応じて、ランクを付与するコードの実装として正しいものを選べ
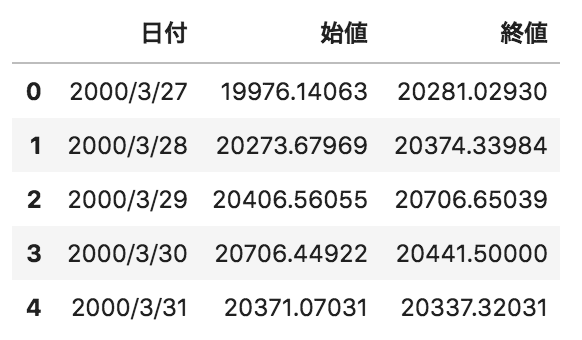
①
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df["増減値"].apply(add_rank)
②
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df.add_rank(df["増減値"])
③
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply(add_rank(df["終値"] - df["始値"]))
④
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply().add_rank(df["終値"] - df["始値"])
①
②
③
④
問3
scikit-learnで学習した決定木を可視化する際に使用するライブラリとして正しいものを以下の中から選べ
pydotplus
seaborn
gnuplot
ggplot
問4
Matplotlibの記述について間違っているものを選べ
1つの描画オブジェクトの中に、複数のグラフを表示させることはできない
グラフの判例を描画するだけでなく、その表示位置やフォント、文字サイズも変更することができる。
描画したグラフをpngファイルなどで保存することができる。
Matplotlibのコードには2種類あり、MATLABのように書くスタイルとオブジェクト指向に則ったスタイルがあるM
問5
matplotlibで散布図を表示させるためのメソッドとして正しいものを選べ。
scatter()
plot()
hist()
vilolinplot()
問6
以下のグラフのxに関して微分した際の値として正しいものを選べ。グラフのCは任意定数を意味する

発散
0
1
問7
以下のコードの後に、np.dot(a, b)を実行した場合の出力と同じにならないものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = a.copy()
a = a.reshape(3,2)
np.multiply(a,b)
np.matmul(a,b)
a @ b
a.dot(b)
問8
scikit-learnで実装されているk-means法について説明している以下の文章のうち間違っているものを選べ
クラスターの重心位置の更新計算は、指定した回数分だけ行われる
教師なし学習であるため、教師ラベルは必要ない
initの引数に”random”を指定すると、最初のクラスター点をデータの中からランダムに選ぶため、初期値依存性がある
クラスターの個数は、使用者が指定する必要がある
問9
以下のようなpandasデータフレームdfがある。Dateカラムをこのデータフレームのインデックスにする場合のコードとして正しいものを選べ
df[“Date”].set_index()
df.reset_index(“Date”)
df.set_index(“Date”)
df.index(“Date”)
問10
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.flatten()
A[1,:]=0
B = B.reshape(6,1)
B[-1]
0
array([6])
array([0])
6
問11
機械学習を用いたデータ分析について説明している文章のうち、正しいものを選べ
モデルの学習を実施したあとは、適切な検証データ、適切な指標を用いてモデルの精度の良し悪しを判断する必要がある
モデルの学習を実施さえすれば、十分な精度が保証されており、すぐに予測モデルを運用することができる
モデルの良し悪しを決めるための評価指標を適切に選ばなくても機械学習アルゴリズムで使っていれば問題ない
特徴量の選択は、適当に決めても精度に大きな影響はないため、特徴量エンジニアリングに時間を割くべきではな
問12
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[0, 1, 2, 3, 4]])
B = np.full((1, 5), 2)
np.sum(A>=B)
3
10
9
4
問13
以下のコードを実行した際に出力されるグラフとして正しいものを選べ
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({"国名":["日本","アメリカ","イタリア","フランス", "ロシア", "ブラジル", "イギリス"], "人口/万人":[12700, 32800, 6000, 6700, 14500, 20900, 6600]})
df = df.sort_values("人口/万人")
plt.rcParams["font.family"] = "AppleGothic"
plt.bar(df["国名"], df["人口/万人"])
plt.ylabel("人口(万人)")
plt.show()
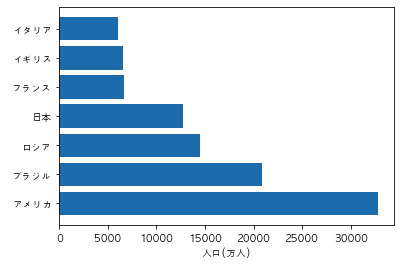
①
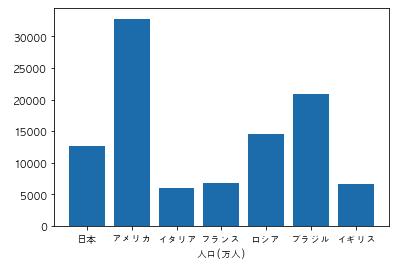
②
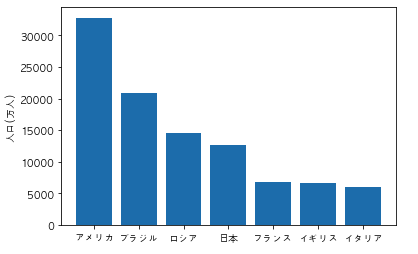
③
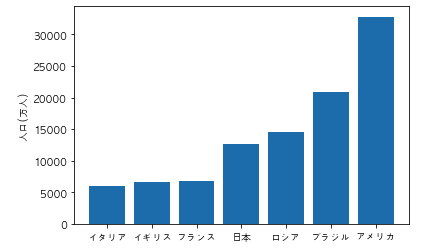
④
①
②
③
④
問14
データサイエンティストの役割について説明している以下の文章のうち、正しいものを選べ
データ分析さえできればよく、顧客の立場になり、その分析結果をどう使えるかまでを考えて分析する必要はない
技術の進歩が速い分野なので、論文などを読んで最新技術をキャッチアップする必要がある
Pythonで実装できるモデルを扱うことが多く、R言語を知っておく必要はない
業務中に自分でPCを修理する場合もあるので、コンピューターの内部構造や動作原理などを知っておく必要がある
問15
以下のような各日付に対して、利用回数と利用料金が格納されたデータフレームdfがある。このdfの欠損値をカラムごとの平均値で埋める処理として正しいものを選べ
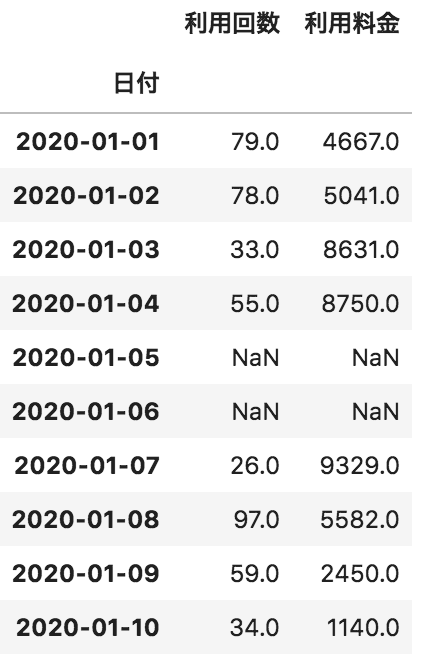
df.fillna(0)
df.dropna(0)
df.fillna(df.mean())
df.fillna(df.sum())
問16
三角関数でないものを以下の選択肢から選べ
cosx
sinhx
tanx
sinx
問17
データサイエンティストやデータエンジニアが使用するツールについて説明している以下の文章のうち、正しいものを選べ
scikit-learnやNumPy、pandasの役割について理解しておく必要はない
たとえデータが小さくても、自分のPCでデータ分析を実施してはならない
anacondaなどの環境構築を行うためのツールは、分析の再現性という観点から実務では使ってはならない
Pythonを用いて前処理や集計をする必然性はなく、Excelを用いて実施してもよい
問18
以下のような日付ごとのサービス利用回数が格納されたデータフレームdfがある。
日付ごとの利用回数の推移を可視化するためのコードとして正しいものを選べ
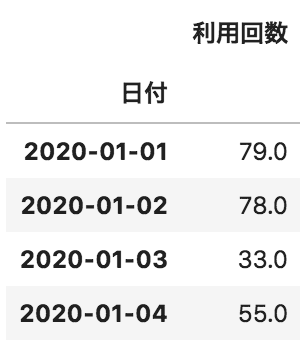
import matplotlib.pyplot as plt
df["利用回数"].plot()
plt.show()
①
import matplotlib.pyplot as plt
df["利用回数"].plot(index="日付")
plt.show()
②
import matplotlib.pyplot as plt
plt.plot(df["利用回数"], df.index)
plt.show()
③
import matplotlib.pyplot as plt
df["利用回数"].scatter()
plt.show()
④
①
②
③
④
問19
欠損値の対処方法として、間違っているものを選べ
One-hotエンコーディングを行う
その特徴量の統計的な代表値などで埋める
欠損値があるデータを用いない
欠損がある場合でも動作する機械学習アルゴリズムを選定する
問20
線形回帰の損失関数に対して、Ridge回帰とLasso回帰が追加している正則化項の組み合わせとして正しいものを選べ
(Ridge回帰, Lasso回帰)= (L2正則化項, L1正則化項)
(Ridge回帰, Lasso回帰)= (L1正則化項, L2正則化項)
(Ridge回帰, Lasso回帰)= (L1正則化項, L3正則化項)
(Ridge回帰, Lasso回帰)= (L3正則化項, L1正則化項)
問21
以下のようなデータがある。このようなデータ型をなんと呼ぶか、正しいものを選べ
{“数学”: 95, “国語”: 65, “英語”: 75}
リスト
タプル
真偽値(ブーリアン)
辞書(ディクショナリ)
問22
以下のようなデータが格納されたexample.csvというファイルをpandasデータフレームとして読み込むためのコードとして正しいものを選べ。
国名,面積
日本,380000
アメリカ,9834000
中国,959700
イタリア,301300
import pandas as pd
df = pd.read_csv("example.csv")
①
import pandas as pd
df = pd.read_excel("example.csv")
②
import pandas as pd
df = pd.read_pickle("example.csv")
③
import pandas as pd
df = pd.load_csv("example.csv")
④
①
②
③
④
問23
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
問24
Pythonについて説明している以下の文章のうち間違っているものを選べ
Pythonで変数を使用する際には、必ず変数の型を最初に定義する必要がある
Pythonはオブジェクト指向のプログラミング言語である
機械学習ライブラリにscikit-learnがある
Pythonの予約語の数は他のプログラミング言語と比較して少ない
問25
以下のコードを実行した場合にxxに格納されるデータとして正しいものを選べ。
import numpy as np
m = np.arange(4)
n = np.arange(4)
xx, yy = np.meshgrid(m,n)
array([[0, 1, 2, 3], [0, 1, 2, 3], [0, 1, 2, 3], [0, 1, 2, 3]])
array([[0, 1, 2, 3], [0, 1, 2, 3]])
array([0, 1, 2, 3])
array([0, 1, 4, 9])
問26
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 1],[1, 1]])
B = np.array([1, 1])
np.dot(A, B)
array([[1, 1], [1, 1]])
array([[2, 2]])
array([2, 2])
実行不可(エラーが出る)
問27
matplotlibのpieメソッドを用いて円グラフのある要素だけずらして表示する場合に指定する引数として正しいものを選べ
explode
startangle
radius
counterclock
問28
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.ravel()
A[0,:]=0
B.reshape(3,2)
array([[1, 2, 3], [4, 5, 6]])
array([[0, 2], [3, 0], [5, 6]])
array([[0, 0], [0, 4], [5, 6]])
array([[1, 2], [3, 4], [5, 6]])
問29
勾配ブースティングの手法として正しくないものを選べ
ニューラルネットワーク
LightGBM
Xgboost
Catboost
問30
pipを用いてXXXXというパッケージをアンインストールする場合に使用するコマンドとして正しいものを選べ
pip remove XXXX
pip uninstall XXXX
pip detach XXXX
pip demount XXXX
問31
モデルの評価指標について説明している以下の文章のうち、正しいものを選べ
適合率と再現率にはトレードオフの関係がある
分類問題の際に使用する評価指標は精度(accuracy)のみである
回帰問題の評価指標にはF値を算出することが多い
scikit-learnには適合率、再現率、F値を算出するためのモジュールが存在しなく、自分で混同行列から算出する必要がある
問32
添付写真のようなpandasデータフレームから、以下のデータが格納されたcsvファイル(example.csv)を出力するためのコードとして正しいものを選べ
name of country,area
日本,380000
アメリカ,9834000
中国,959700
イタリア,301300
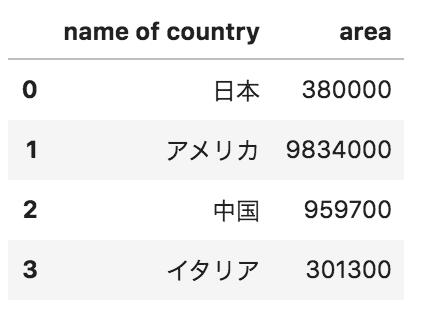
df.to_csv(“example.csv”)
df.output_csv(“example.csv”, index=False)
df.to_excel(“example.csv”, index=True)
df.to_csv(“example.csv”, index=False)
問33
以下のコードを実行した際に出力されるグラフとして正しいものを選べ
import matplotlib.pyplot as plt
import math
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
y_list2 = list(map(lambda x: x**3+x**2, x_list))
y_list3 = list(map(lambda x: (math.e)**x, x_list))
plt.plot(x_list, y_list, label="x**2")
plt.plot(x_list, y_list2, label="x**3+x**2")
plt.plot(x_list, y_list3, label="exp(x)")
plt.legend()
plt.show()
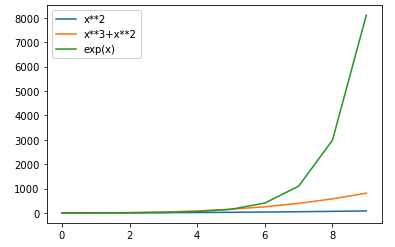
①
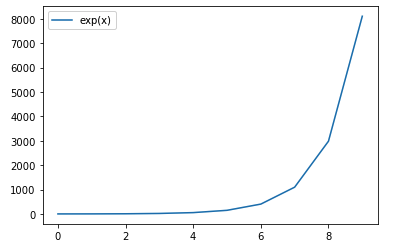
②
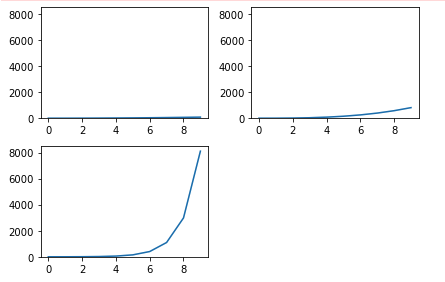
③
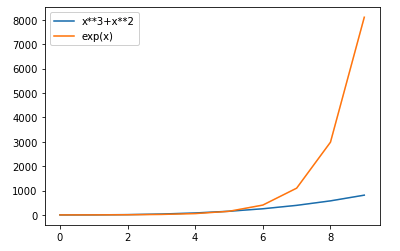
④
①
②
③
④
問34
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.eye(4)
first, second = np.vsplit(A, [3])
second.T
array([[0., 0., 0., 1.]])
array([[0., 0., 1., 0.], [0., 0., 0., 1.]])
array([[0., 0.], [0., 0.], [1., 0.], [0., 1.]])
array([[0.], [0.], [0.], [1.]])
問35
AUCはROC曲線から算出されるが、具体的にはROC曲線の何を算出したものか。以下の中から正しいものを選べ
ROC曲線の面積
ROC曲線の縦軸の最大値
ROC曲線の横軸の最大値
ROC曲線の勾配(微分)
問36
配列の形状が(2,10)であり、各要素が平均2、標準偏差5の正規分布に従う乱数を生成するコマンドとして正しいものを選べ。
np.random.normal[2,5,size=(2,10)]
np.random.random(2,5,size=(2,10))
np.random.normal(2,5,size=(2,10))
np.random.rand(2,5,size=(2,10))
問37
matplotlibでテキストをグラフ内に描画するメソッドについて説明している以下の文章のうち間違っているものを選べ
add_text()メソッドを用いる
メソッドの引数でグラフ内のどの位置に表示するかを座標で指定することができる
メソッドの引数で描画するテキストのサイズを指定することができる
text()メソッドを使用する
問38
サポートベクターマシンについて説明している以下の文章のうち正しいものを選べ
scikit-learnで使用する場合、カーネルはガウスカーネル以外にも指定することができる
内部で欠損値を処理するアルゴリズムが実装されているため、欠損値はNULL値のままでよい
線形分離可能な問題にのみ適用できる
マージンの距離を最小にするように最適化するアルゴリズムである
問39
Matplotlibの記述について正しいものを選べ
デフォルトで日本語フォントに対応しているため、日本語を表示させるための設定をする必要はない
今でも定期的にバージョンのアップデートなどがされており、世界中のデータ分析者に使われている
開発者は日本人である
2次元プロットだけでなく、3次元プロットにも対応している
問40
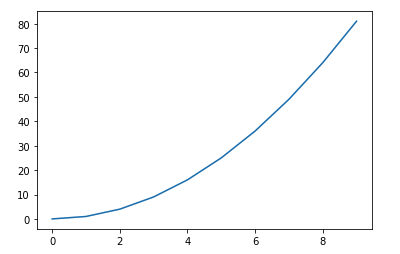
以下のコードを実行すると、写真のようなグラフが描画される
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list)
plt.show()
グラフの線の色を赤色に変更したい場合のコードとして、正しいものを選べ
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list, color = "red")
plt.show()
①
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list)
plt.show(color = "red")
②
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list, ls="--")
plt.show()
③
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list, style="red")
plt.show()
④
①
②
③
④