| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
matplotlibのhist()メソッドの引数に関する説明として間違っているものを選べ
最適なビンの数を決める手法を指定することができる
ビンの数を変更することができる
積み上げヒストグラムを描画することができる
相対度数分布を表示することができる
解説
最適なビンの数を決める手法は用意されていません。さまざまな手法をつかって値を求めてからbinsに指定する必要があります。
問2
データエンジニアの業務について説明している以下の文章のうち、間違っているものを選べ
集計ミスがないかの確認をする
データサイエンティストや顧客とコミュニケーションを取る
データベース言語を用いてデータの抽出を行う
機械学習のアルゴリズムを深い領域で理解する
問3
写真のようなデータフレームdfがある。以下のコードと出力が一致しないコードとして正しいものを選べ
df[df["面積"]>380000]
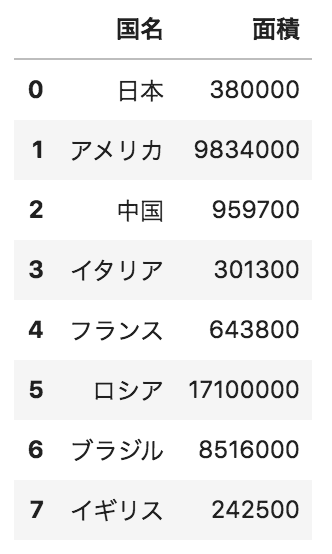
df.query(“面積>380000”)
df[df.iloc[:,1]>380000]
df.面積 > 380000
df[df.loc[:,”面積”]>380000]
問4
以下のような、日付に対して番号が格納されているデータフレームdfがある。このデータフレームの月ごとの番号の平均を出力するコードとして正しいものを選べ
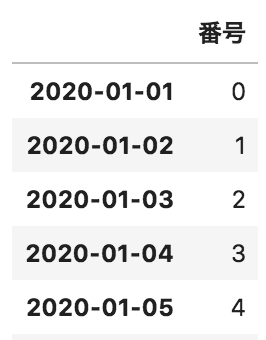
df.groupby(pd.Grouper(freq=”W”)).mean()
df.groupby(pd.Grouper(freq=”M”)).mean()
df.groupby(pd.Grouper(freq=”Y”)).mean()
df.groupby(freq=”M”).mean()
問5
以下のようなデータフレームdfがある。このデータフレームから国名カラムのみのデータフレームを抽出する際のコードとして正しくないものを選べ
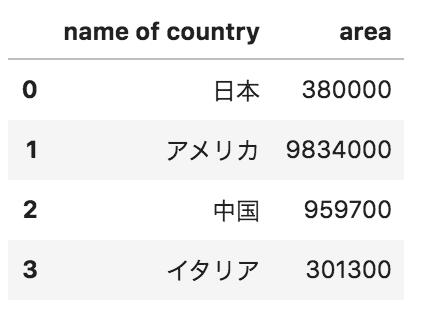
df.loc[:,[“name of country”]]
df.iloc[[0],:]
df.filter([“name of country”])
df[[“name of country”]]
問6
以下のようなデータがある。このようなデータ型をなんと呼ぶか、正しいものを選べ
{“数学”: 95, “国語”: 65, “英語”: 75}
リスト
タプル
真偽値(ブーリアン)
辞書(ディクショナリ)
問7
matplotlibについて説明している以下の文章のうち、間違っているものを選べ
plotメソッドではedgecolor引数を指定することで、グラフの枠線の色を指定することができる
color引数では、文字列の他に、HTMLやCSS3で定義された色名を指定することができる
散布図で指定することができるマーカーの種類は30種以上ある
plot()メソッドでは線の太さを変更することはできない
問8
以下のコードを実行した場合のBとCに格納されているデータの組み合わせとして、正しいものを選べ。選択肢は(B, C)の順に記載されている。
import numpy as np
A = np.eye(3)
B = np.count_nonzero(A)
C = np.sum(A)
(array([3]), array([3]))
(3, 3)
(True, 6)
(True, 3)
問9
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
性別ごとの人数を棒グラフで表示するためのコードとして正しいものを選べ
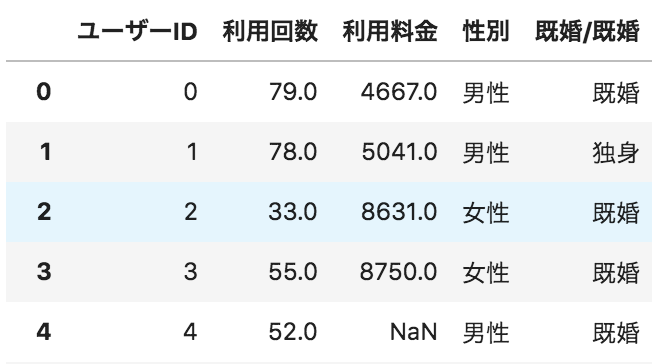
import matplotlib.pyplot as plt
df["性別"].value_counts().plot.bar()
plt.show()
①
import matplotlib.pyplot as plt
df["性別"].plot.bar()
plt.show()
②
import matplotlib.pyplot as plt
plt.bar(df["性別"].value_counts())
plt.show()
③
import matplotlib.pyplot as plt
df["性別"].value_counts().bar()
plt.show()
④
①
②
③
④
問10
Jupyter Notebookについて説明している以下の文章のうち、正しいものを選べ
単一行でセルを実行できることもあり、セル内で関数を作成することは良くない
単一のコードを実行できることもあり、後から見直した時のために、セルとセルの間には適度に、コメントを残すべきである
ノートブックが複数に別れていると面倒なので、ノートブックは長くても1つに納める方が良い
使っていないノートブックは自動でシャットダウンされるので、いくつでもノートブックを開くことは問題ない
問11
決定木の不純度の指標として、間違っているものを以下の中から選べ
情報利得
ジニ不純度
エントロピー
分類誤差
問12
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([0, 1, 2, 3, 4, 5])
B = np.array([6, 7, 8])
A2 = A.reshape(2, 3)
B2 = B[np.newaxis,:]
np.vstack([A2,B2])
array([[0, 1, 6], [2, 3, 7], [4, 5, 8]])
array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
array([[0, 3, 6], [1, 4, 7], [2, 5, 8]])
array([[0, 2, 4], [1, 3, 5], [6, 7, 8]])
問13
ある変数xの標準偏差が1、ある変数yの標準偏差が2、この2つのxとyの共分散が2であるとき、この2変数のピアソンの相関係数として正しいものを選べ。
0.25
2
0.5
1
問14
データサイエンティストの役割について説明している以下の文章のうち、正しいものを選べ
技術の進歩が速い分野なので、論文などを読んで最新技術をキャッチアップする必要がある
Pythonで実装できるモデルを扱うことが多く、R言語を知っておく必要はない
業務中に自分でPCを修理する場合もあるので、コンピューターの内部構造や動作原理などを知っておく必要がある
データ分析さえできればよく、顧客の立場になり、その分析結果をどう使えるかまでを考えて分析する必要はない
問15
以下のようなデータフレームdfがある。このデータフレームから、B列の値が3000以上のデータフレームを抽出するコードとして正しいものを選べ。
import pandas as pd
df = pd.DataFrame({"A":[10,200,3000,40000],
"B":[1000,2000,3000,4000]})
df[[“B”]>=3000]
df[“B”]>=3000
df[df[“B”]>=3000]
df[df[“B”]>=3000][“B”]
問16
平均 50, 標準偏差 10 の正規分布に従う乱数を1,000個生成したデータがある。この1000個のデータのヒストグラムとして正しいものを選べ
①
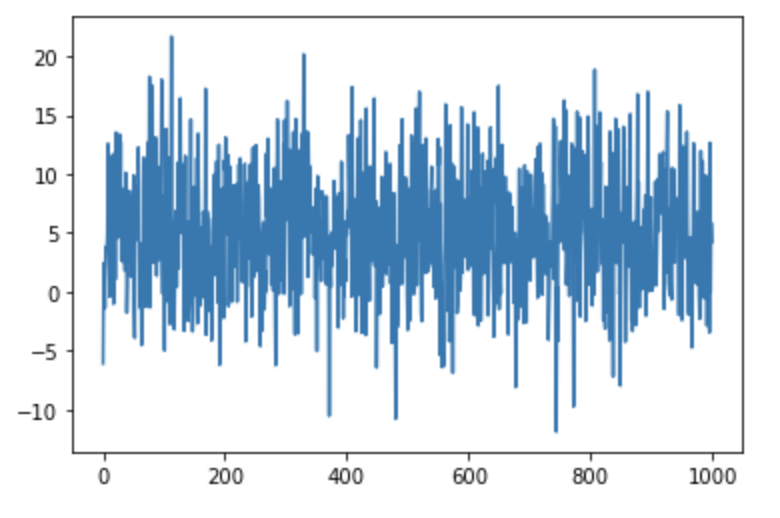
②
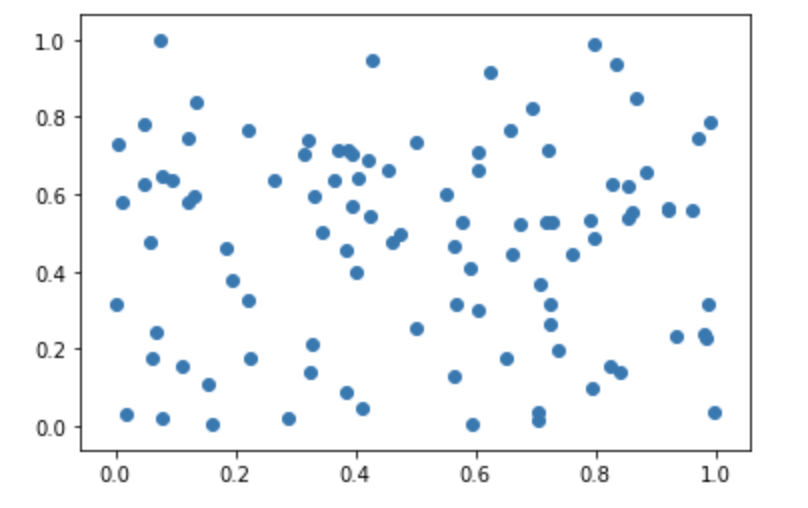
③
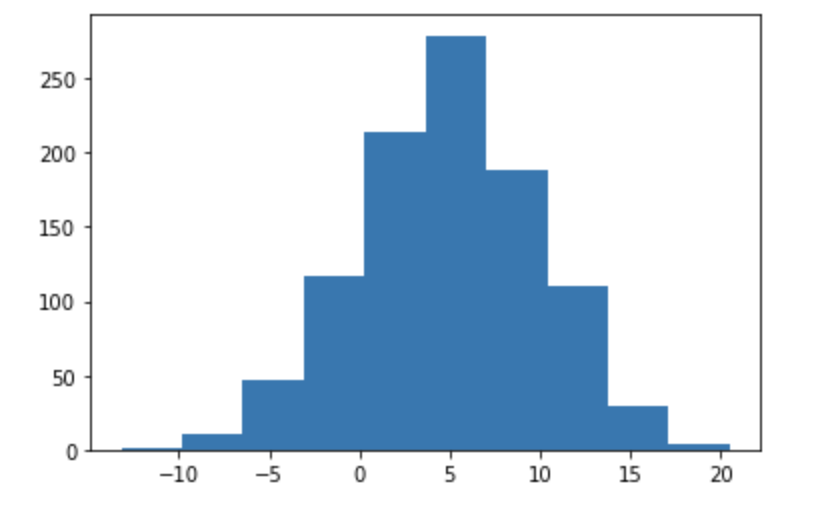
④
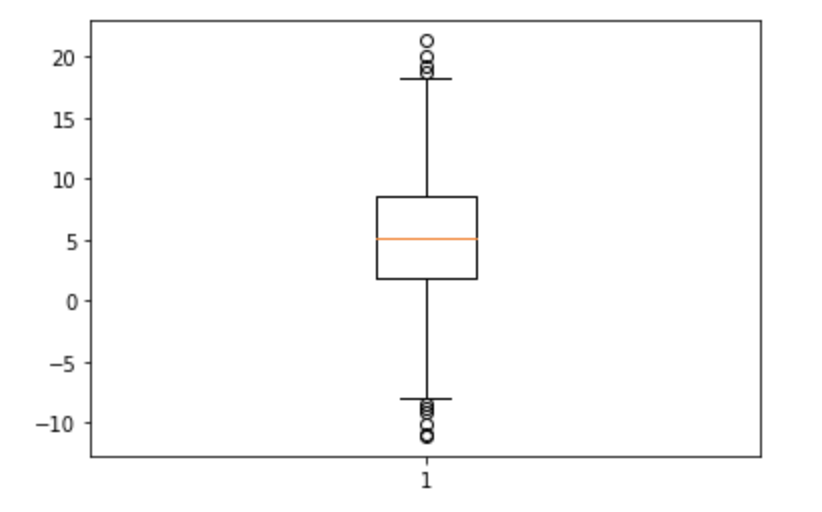
①
②
③
④
問17
以下のコードを実行した際に、Aについて述べているものとして、間違っているものを選べ
import numpy as np
A = np.random.rand(10,1)
Aの配列の形状は(10,1)である。
Aに格納されている値は全て、標準正規分布に従う乱数である。
中心が10、標準偏差が1に従う正規分布から生成された乱数が格納されている
Aに格納されている値は0以上1未満の浮動小数点数である。
問18
決定木について説明している以下の文章のうち、正しいものを選べ
情報利得の大きい順に特徴量が使用され、木が作られる
木が下に行けば行くほど、特徴量の情報利得は大きい
各葉においてデータを分割する際の閾値はあらかじめモデル作成者が決める必要がある
欠損値は除外するか、何かしらの値で埋めておく必要がある
問19
以下のコードの出力として正しいものを選べ
import pandas as pd
df = pd.DataFrame({"A":[1,2,3,4,5], "B":[6,7,8,9,10]})
df["A"]>3

①

②

③

④
`
①
②
③
④
問20
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.full((2,2),1)
B = np.zeros((2,2))
np.concatenate([A, B], axis=0)
array([[1., 1.], [1., 1.], [0., 0.], [0., 0.]])
array([[1., 1., 0., 0.], [1., 1., 0., 0.]])
array([[1., 0.], [1., 0.], [1., 0.], [1., 0.]])
実行不可(エラーが出る)
問21
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 0]])
B = np.array([1, 0])
A @ B
array([1])
array([[1]])
array([[1, 1]])
array([[1, 1], [1, 1]])
問22
データサイエンティストの役割について説明している以下の文章のうち、正しいものを選べ
データ分析さえできればよく、顧客の立場になり、その分析結果をどう使えるかまでを考えて分析する必要はない
技術の進歩が速い分野なので、論文などを読んで最新技術をキャッチアップする必要がある
Pythonで実装できるモデルを扱うことが多く、R言語を知っておく必要はない
業務中に自分でPCを修理する場合もあるので、コンピューターの内部構造や動作原理などを知っておく必要がある
問23
データサイエンティストやデータエンジニアが使用するツールについて説明している以下の文章のうち、正しいものを選べ
scikit-learnやNumPy、pandasの役割について理解しておく必要はない
たとえデータが小さくても、自分のPCでデータ分析を実施してはならない
anacondaなどの環境構築を行うためのツールは、分析の再現性という観点から実務では使ってはならない
Pythonを用いて前処理や集計をする必然性はなく、Excelを用いて実施してもよい
問24
以下のコードを実行した後に、np.hstack((a,b))を実行した場合の出力と同じにするにはどれを実行すれば良いか?正しいものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = np.array([[100],[100]])
np.concatenate([a,b],axis=0)
np.concatenate([a,b],axis=1)
np.vtack([a,b])
np.append(a,b)
問25
以下のコードを実行した場合に、出力されるグラフとして正しいものを選べ(ランダムのデータを使っているので形状は変わってもよい)
fig, ax = plt.subplots()
x1 = [x for x in range(1,4)]
y1 = [1,2,3]
x2 = [x for x in range(1,6)]
y2 = [np.random.randint(10) for x in range(5)]
ax.bar(x1, y1, label="y1")
ax.plot(x2, y2, label="y2")
ax.legend()
plt.show()
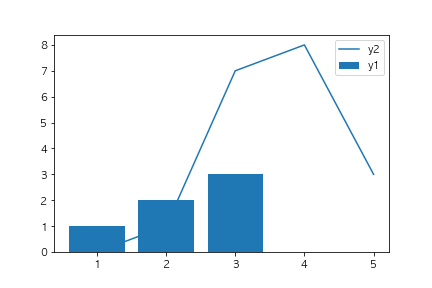
①
②
③
④
①
②
③
④
問26
以下のようなデータフレームdfがある。このデータフレームのカラム名を変更する際のコードとして正しいものを以下の中から選べ
df.rename(columns={“name of country”:”国名”, “area”:”面積”})
df.rename(index={“国名”:”name of country”, “面積”:”area”})
df.rename(column={“国名”:”name of country”, “面積”:”area”})
df.columns({“国名”:”name of country”, “面積”:”area”})
問27
以下の主成分分析を実施するコードのXXXに当てはまるものとして正しいものを選べ
※選択肢中に登場するdfは主成分分析を施す元データを意味する
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = XXX
fig, ax = plt.subplots()
ax.scatter(X_pca[:, 0], X_pca[:, 1])
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_xlim(-1.1, 1.1)
ax.set_ylim(-1.1, 1.1)
plt.show()
pca.fit_transform(df)
pca.transform(df)
pca.predict(df)
pca.fit(df)
問28
以下のような、日付に対して番号が格納されているデータフレームdfがある。このデータフレームを水曜日までの1週間単位の番号の合計を出力するコードとして正しいものを選べ
df.groupby(pd.Grouper(freq=”W-WED”)).count()
df.groupby(pd.Grouper(freq=”M-WED”)).sum()
df.groupby(pd.Grouper(freq=”W-WED”)).mean()
df.groupby(pd.Grouper(freq=”W-WED”)).sum()
問29
機械学習を用いたデータ分析について説明している文章のうち、正しいものを選べ
モデルの学習を実施したあとは、適切な検証データ、適切な指標を用いてモデルの精度の良し悪しを判断する必要がある
モデルの学習を実施さえすれば、十分な精度が保証されており、すぐに予測モデルを運用することができる
モデルの良し悪しを決めるための評価指標を適切に選ばなくても機械学習アルゴリズムで使っていれば問題ない
特徴量の選択は、適当に決めても精度に大きな影響はないため、特徴量エンジニアリングに時間を割くべきではな
問30
以下のコードのXXXXの部分に当てはまるものとして正しいものを選べ
try:
with open('sample.txt', encoding='utf-8') as f:
txt = f.read()
f.close()
print(txt)
XXXX FileNotFoundError as err:
print("ファイルが存在しないため、読み込めませんでした。")
XXXX Exception as other:
print("ファイルが読み込めませんでした。")
exception
exceptional
except
reject
問31
機械学習モデルについて説明している以下の文章のうち間違っているものを選べ
機械学習モデルでは、何かを分類するタスクしか解くことができない
ラベルではなく数値そのものを予測する問題を回帰問題という
データが大量に存在する場合にモデルを構築する際は、学習データ、検証データ、テストデータの3つに分割するのが理想である
異なる検証データで結果を比較するために、交差検証を実施することもある
問32
datetimeモジュールについて説明している以下の文章のうち、誤っているものを選べ
取得する日付や日時のタイムゾーンを指定することができる
now()を使用することで、今日の日付を取得することができる
日数の差分を算出するなど、日付同士の演算をすることができない。
日時(datatime型)→文字列の変換はできるが、文字列→日時(datatime型)の変換はできない
問33
matplotlibのhist()メソッドの返り値として取得できる情報として正しいものを選べ
(各ビンの度数、各ビンの範囲、パッチオブジェクトが格納されている配列)の3つの返り値を持つ
各ビンの範囲と各ビンの度数が格納されているディクショナリとして1つの返り値を持つ
(各ビンの度数、各ビンの範囲)の2つの返り値を持つ
(各ビンの度数、各ビンの範囲, 最頻値)の3つの返り値を持つ
問34
以下のコードを実行すると、変数A, B, C, Dには1つだけ異なるデータが格納される(4つのうち3つは同じデータが格納される)。格納されているデータが他の変数と異なる変数を選べ。
import numpy as np
A = np.full(10, 10.0)
B = np.array([10])*10
C = np.zeros(10)+10
D = np.ones(10)*10
C
B
A
D
問35
pandasのデータフレームの上から5行目までを表示させるメソッドとして、正しいものを選べ。
tail()
head()
view()
show()
問36
以下のコードを実行すると、写真のようなグラフが描画される。グラフの判例をグラフ内の右下に表示させる場合のax.legend()の引数として正しいものを選べ
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.plot([1,2,3], [1,4,9], label="$y=x^2$")
ax.legend(loc="best")
plt.show()
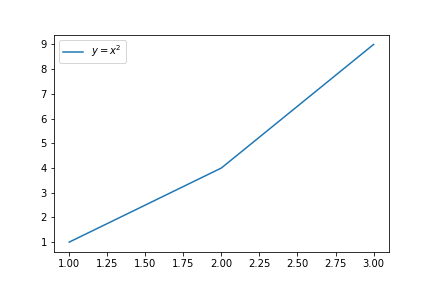
ax.legend(loc=”lower right”)
ax.legend(loc=”upper right”)
ax.legend(loc=”right”)
ax.legend(loc=”default”)
問37
機械学習を用いたデータ分析において、データを入手してからモデルの学習を実施するまでの処理手順として、正しいものを選べ
データ入手→アルゴリズム選択→データ加工→データ可視化→モデルの学習
データ入手→アルゴリズム選択→データ加工→データ可視化→モデルの学習
データ入手→データ可視化→アルゴリズム選択→データ加工→モデルの学習
データ入手→データ加工→データ可視化→アルゴリズム選択→モデルの学習
問38
特徴量の正規化について説明している以下の文章のうち、間違っているものを選べ
特徴量の最大値が1、最小値が0となるように変換をする、最大最小正規化が存在する
特徴量のオーダーが大きく異なる場合は正規化を実施する必要はない
データの分布が標準正規分布に従うように変換する、分散正規化が存在する
scikit-learnには正規化を行うためのモジュールが存在する
問39
以下のコードを実行した場合にBに格納されているものとして正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.ravel()
A[0,:]=0
array([1, 2, 3, 4, 5, 6])
array([0, 2, 3, 0, 5, 6])
array([[1, 2, 3, 4, 5, 6]])
array([0, 0, 0, 4, 5, 6])
問40
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.flatten()
A[1,:]=0
B[-1]
array([0, 0, 0])
6
array([6])
array([4, 5, 6])