問1
確率密度関数と確率の関係として正しいものを以下の中から選べ。
確率は確率密度関数の勾配である。
確率は確率密度関数の面積である。
確率は確率密度関数の幅の広さである。
確率は確率密度関数の最大値である。
解説
確率密度の面積が確率です。
問2
matplotlibのhist()メソッドの返り値として取得できる情報として正しいものを選べ
(各ビンの度数、各ビンの範囲、パッチオブジェクトが格納されている配列)の3つの返り値を持つ
各ビンの範囲と各ビンの度数が格納されているディクショナリとして1つの返り値を持つ
(各ビンの度数、各ビンの範囲)の2つの返り値を持つ
(各ビンの度数、各ビンの範囲, 最頻値)の3つの返り値を持つ
解説
各ビンの度数、各ビンの範囲、パッチオブジェクトが格納されている配列を返します。
問3
以下のような各日付に対して、利用回数と利用料金が格納されたデータフレームdfがある。このdfの欠損値を0で埋める処理として正しいものを選べ
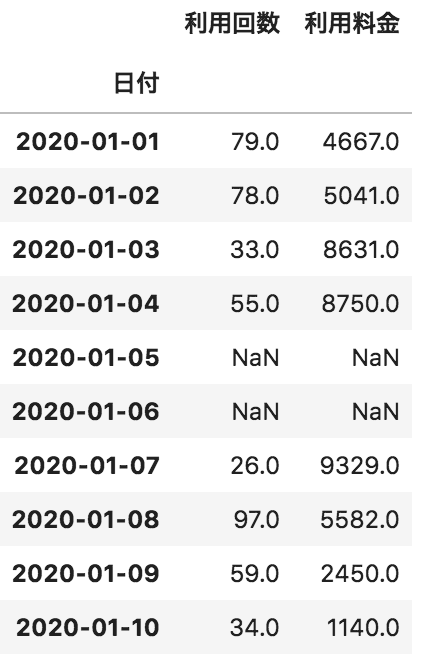
df.fillna()
df.fillna(method=”ffill”)
df.dropna(0)
df.fillna(0)
解説
fillnaメソッドを使うと欠損値(Na/NaN)の値を埋めることができます。問題文では平均値で埋めるとあるので引数に0を適用します。
問4
Matplotlibを用いて、1つの描画オブジェクト中に表示された2つのグラフに対して、タイトルを指定するコードとして正しいものを選べ
import matplotlib.pyplot as plt
fig, axes = plt.subplots(ncols=2)
axes[0].set_title("graph left")
axes[1].set_title("graph right")
fig.suptitle("fig title")
plt.show()
①
import matplotlib.pyplot as plt
fig, axes = plt.subplots(ncols=2)
axes[0].title("graph left")
axes[1].title("graph right")
fig.title("fig title")
plt.show()
②
import matplotlib.pyplot as plt
fig, axes = plt.subplots(ncols=2)
axes.title(["graph left", "graph right"] )
fig.title("fig title")
plt.show()
③
import matplotlib.pyplot as plt
fig, axes = plt.subplots(ncols=2)
axes.subtitle(["graph left", "graph right"])
fig.title("fig title")
plt.show()
④
①
②
③
④
解説
サブプロット領域(Aexs)に対してタイトルを付ける set_title メソッドを使用している選択肢が正解です。
問5
matplotlibで散布図を表示させるためのメソッドとして正しいものを選べ。
scatter()
plot()
hist()
vilolinplot()
解説
散布図はscatterメソッドを使用することで描画できます。
問6
1×2×3×4×5と同じ意味を表す数式として正しいものを選べ
解説
問7
以下の説明文のうち、線形回帰の中で微分が使用される理由として正しいものを選べ
損失関数と呼ばれる関数を最小にするパラメーターを求める際に必要だから
損失関数と呼ばれる関数が描く面積を求める際に必要だから
仮定関数を決める際に必要だから
予測結果の妥当性を検証する際に必要だから
解説
選択肢が回答になります。もう少し踏み込むと勾配降下法という手法を用いるため、微分が使用されます。
問8
pandasのデータフレームの上から5行目までを表示させるメソッドとして、正しいものを選べ。
tail()
head()
view()
show()
解説
pandas のデータフレームの上から5行目までを表示させるメソッドは head() メソッドです。ちなみに末尾5行目を表示させるのは tail() メソッドです。
問9
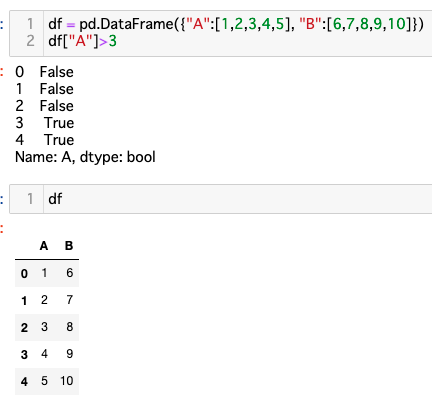
以下のコードの出力として正しいものを選べ
import pandas as pd
df = pd.DataFrame({"A":[1,2,3,4,5], "B":[6,7,8,9,10]})
df["A"]>3

①

②

③

④
`
①
②
③
④
解説
df[“A”]はA列のみを抽出しています。そこに不等号ので3より大きいかを判定していますので正解の画像になります。
問10
以下のコードを実行した際に出力されるグラフとして正しいものを選べ
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({"国名":["日本","アメリカ","イタリア","フランス", "ロシア", "ブラジル", "イギリス"], "人口/万人":[12700, 32800, 6000, 6700, 14500, 20900, 6600]})
df = df.sort_values("人口/万人")
plt.rcParams["font.family"] = "AppleGothic"
plt.bar(df["国名"], df["人口/万人"])
plt.ylabel("人口(万人)")
plt.show()
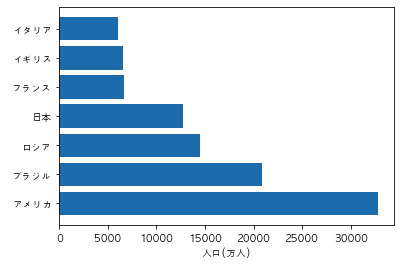
①
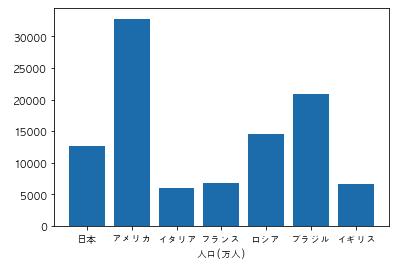
②
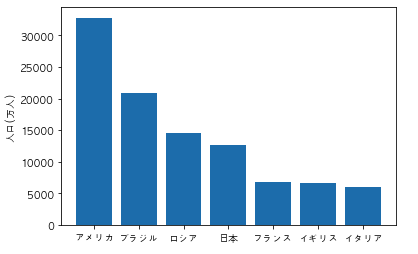
③
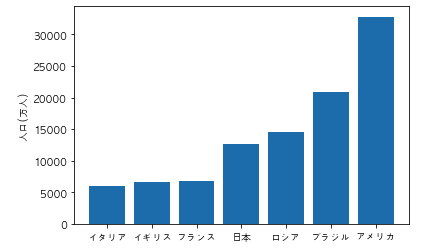
④
①
②
③
④
解説
コードからグラフをイメージ出来るかの問題です。まず bar メソッドは縦の棒グラフです。そしてsort_values()メソッドを使ってデータをソートしています。パラメータの指定はないのでデフォルトで昇順(今のデータより次のデータが大きい、昇っていく順)になっています。
問11
配列の形状が(2,10)であり、各要素が平均2、標準偏差5の正規分布に従う乱数を生成するコマンドとして正しいものを選べ。
np.random.normal[2,5,size=(2,10)]
np.random.random(2,5,size=(2,10))
np.random.normal(2,5,size=(2,10))
np.random.rand(2,5,size=(2,10))
解説
NumPyのrandomモジュールの問題です。randomモジュールのnormalメソッドは任意の平均と標準偏差を用いて正規分布に従う乱数を生成出来ます。
問12
scikit-learnのDesicionTreeClassifierモジュールを使用する場合に引数として指定できないものを選べ
木の数
木の深さ
葉の数
不純度の指標
解説
一つの木から枝をはやしていくので木の数は設定できません。
問13
以下のコードの出力として正しいものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = np.array([[100],[100]])
c = np.concatenate([a,b],axis=1)
c = c.reshape(4,2)
np.dot(c, b)
array([[100, 101, 110, 200], [100, 101, 110, 200]])
array([[ 0, 100, 1000], [ 0, 100, 1000], [10000, 10000, 10000]])
array([[10000, 10200, 12000]])
array([[ 100], [11000], [ 100], [11000]])
解説
NumPyの行列操作の問題です。上から読むと、行列a(2行, 3列)と行列b(2, 1)を定義します。cはaとbをaxis=1、つまり列(水平)方向で結合し、c(2, 4)となります。その後reshapeメソッドを用い4行2列に変換しています。np.dot(c, b)で行列積の計算をします。c(4, 2)@b(2, 1)ですので内側が2であってますので計算可能で、外側の数値がサイズになりますので、最後の行で出力するサイズは(4,1)になります。中身の数値はc@bの結果です。出力の一行目は(0100)+(1100)=100、2行目は(10100)+(100100)=11000というような出力になります。
問14
階層的クラスタリングの結果の解釈に用いられる樹形図の説明として正しいものを選べ
データ数が多いと表示が困難であるため、一部だけ取り出して可視化するなどの工夫が必要である
樹形図の縦軸はクラスター内誤差平方和(SSE)である
次元削減をして特徴量を2変数にしてから、可視化しなければならない
最短距離法を用いた場合には、樹形図による可視化はできない
解説
データ数が多いと表示が困難であるため、一部だけ取り出して可視化するなどの工夫が必要であるが正解です。特に説明したい部分だけをピックアップする方が分析する側の負担も減らせます。下記はクラスタリングの図のサンプルです。
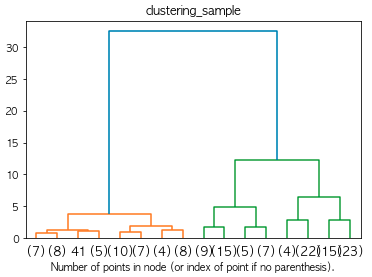
問15
AUCはROC曲線から算出されるが、具体的にはROC曲線の何を算出したものか。以下の中から正しいものを選べ
ROC曲線の面積
ROC曲線の縦軸の最大値
ROC曲線の横軸の最大値
ROC曲線の勾配(微分)
解説
ROC曲線の面積を計算したものがAUCです。
1に近いほど予測精度が高く1から離れるほど予測精度が低くなります。
問16
以下のコードを実行した際の出力として、正しいものを選べ
import numpy as np
a = np.array([0,1,10,100])
c = a.flatten()
c[0] = 1000
a == c
array([False, True, True, True])
array([True, True, True, True])
array([False, True, True, False])
FALSE
解説
浅いコピーと深いコピーの問題です。この問題では深いコピーである flattenメソッドを使用しているのでcの変更はAに影響しません。
問17
ポアソン分布について述べている以下の文章のうち、正しいものを選べ
ポアソン分布におけるパラメーターは、平均値と標準偏差である。
交通事故の発生回数の予測、機械部品の故障予測など、稀に生じる事象についてモデル化したい場合に用いられる、離散型の確率分布である。
二項分布における試行回数と平均値が∞に発散する場合の極限を計算することで、ポアソン分布の確率密度関数は得られる
確率変数の実現値が連続変数である連続型確率分布である。
解説
統計学および確率論においてポアソン分布(英: Poisson distribution)とは、ある時間間隔で発生する事象の回数を表す離散確率分布である。
出典元 「ポアソン分布」(2021年12月27日17時00分 UTC版) 『ウィキペディア(Wikipedia)』
問18
np.random.randint(1,11)を繰り返し実行した場合の平均値は、繰り返し回数が多ければ多いほど、ある値に近づいていく。ある値として正しいものを以下の中から選べ。
1
11
3.5
5.5
解説
NumPyのramdomモジュールのrandintメソッドの問題です。引数に1と11を用いています。これは1以上11未満の整数乱数を生成します。したがって繰り返すほど5.5に近づいていきます。
問19
以下のコードを実行した場合にxxに格納されるデータとして正しいものを選べ。
import numpy as np
m = np.arange(4)
n = np.arange(4)
xx, yy = np.meshgrid(m,n)
array([[0, 1, 2, 3], [0, 1, 2, 3], [0, 1, 2, 3], [0, 1, 2, 3]])
array([[0, 1, 2, 3], [0, 1, 2, 3]])
array([0, 1, 2, 3])
array([0, 1, 4, 9])
解説
meshgridの問題です。meshgridは引数を元に格子座標を生成します。補足としてyyはarray([[0, 0, 0, 0], [1, 1, 1, 1], [2, 2, 2, 2], [3, 3, 3, 3]])になります。
問20
ROC曲線の横軸と縦軸が意味するものとして正しい組み合わせを以下の中から選べ
(横軸, 縦軸)= (偽陽性率, 真陽性率)
(横軸, 縦軸)= (真陽性率, 偽陽性率)
(横軸, 縦軸)= (適合率, 再現率)
(横軸, 縦軸)= (再現率, 適合率)
解説
ROC曲線では、横軸に偽陽性率、縦軸に真陽性率をプロットします。
問21
scikit-learnのサポートベクターマシンのハイパーパラメーターのCについて説明している以下の文章のうち正しいものを選べ
Cの値が小さいほど、マージンは大きくなる
Cの値が大きいほど、マージンは大きくなる
C=Trueにすると、非線形の分類問題も境界線を求めることができるようになる
特徴量の数が大きいほど、Cの値も大きくする必要がある
解説
正則化項であるパラメータCは個々のデータポイントの重要度で、Cを無限大に大きくしていくとマージンは小さくなります。Cはデータポイントの重要度で、Cが大きいとデータポイントが決定境界に与える影響も大きくなります。決定境界とデータポイントまでの距離であるマージンはCが大きくなるに伴い小さくなります。
問22
pip freeze コマンドの説明として正しいものを選べ
インストールされているパッケージの一覧を出力する
pipのバージョンを最新にする
実行中のpipコマンドを強制終了するコマンド
現在のpipのバージョンを出力するコマンド
解説
インストールされたパッケージを要件形式で出力します。結果をオプションでファイルに出力することも出来ます。
出典元 「pip」(2021年12月23日11時00分 UTC版) 『pip freeze — pip 9.1.0.dev0 ドキュメント』
問23
以下の文章のうちOne-hotエンコーディングの説明として正しいものを選べ
各カテゴリーラベルごとのカラムが新たに生成されるため、特徴量の数は増える
各カテゴリーを1,2,3…と数値に変換する処理である
カラムごとに0~1の範囲に収まるようにデータを変換する処理である
各カテゴリーを列として展開し、該当する値の列は1、それ以外の列は-1が入力される
解説
特定の変数の種類分特徴量が増えます。以下のようなデータがある場合に
1 2 3 |
name favorite_food 'taro' apple 'jiro' orange |
このように変換されて特徴量である列の数が増えます。
1 2 3 |
name apple orange 'taro' 1 0 'jiro' 0 1 |
問24
以下のグラフは各ユーザーの支払い請求額をx軸、チップをy軸とした散布図である。この散布図の説明として正しいものを選べ
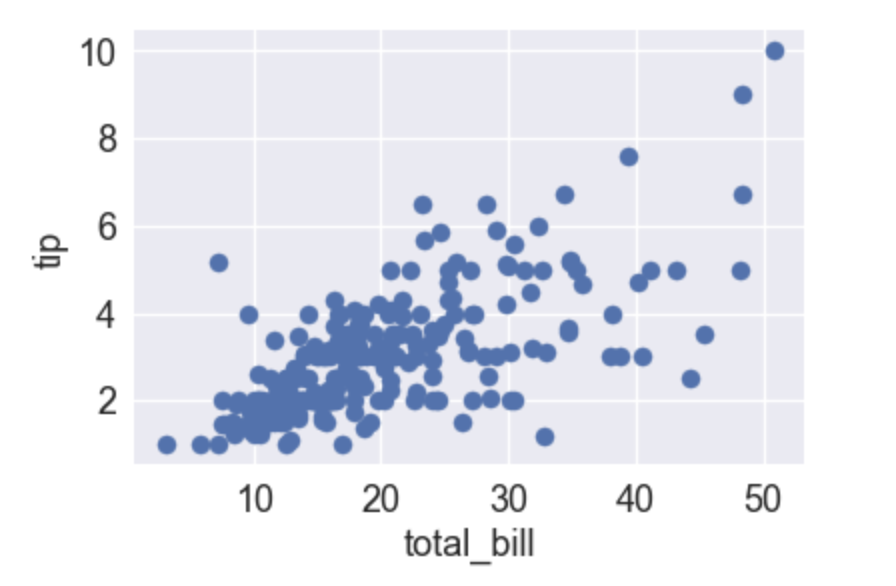
支払い請求額は30~40が最も多いことがわかる
チップが10付近の所に1つデータがあるが、これは外れ値である
支払い請求額とチップには概ね負の相関がある
支払い請求額とチップには概ね正の相関がある
解説
データ分析の知識を問われてる問題です。相関という言葉は、2つのデータについて片方の変化がもう片方に影響を与える関係がある場合に相関がある、という言い方をします。この場合、片方が上がれば片方も上がるので生の相関がある、という言い方が出来ます。
問25
特徴量の次元削減について説明している以下の文章のうち、正しいものを選べ
なるべくデータの情報を落とさずに、少ない特徴量でデータを表現するために用いられる
次元削減の手法には非線形変換を行う手法のみ存在する
scikit-learnで実装されている主成分分析を使用する際、次元数をいくつまで削減するかを指定することはできない
数学的には、内部で積分計算を行なっている
解説
主成分分析(PCA:Principal Component Analysis)の問題です。これによって次元削減を行います。目的はデータの要約をすることです。つまりデータの重要な部分だけを残して、重要ではない部分を削るということをします。
問26
以下のようなデータフレームdfがある。このデータフレームから、A列とB列の値が3000のデータフレームを抽出するコードとして正しいものを選べ。
import pandas as pd
df = pd.DataFrame({"A":[10,200,3000,40000],
"B":[1000,2000,3000,4000]})
df[(df[“A”]==3000)or(df[“B”]==3000)]
df[([“A”]==3000)&([“B”]==3000)]
df[(df[“A”]==3000)&(df[“B”]==3000)]
df[df[“A”, “B”]==3000]
解説
データフレームからデータを抽出する問題です。大きな流れはデータフレームからデータを抽出して再度データフレームに入れます。後、演算子に注意しましょう。
問27
決定木の不純度の指標として、間違っているものを以下の中から選べ
情報利得
ジニ不純度
エントロピー
分類誤差
解説
不純度とは分類されたクラスに余計なものが含まれる割合のことです。
その割合を求める指標として
- ジニ不純度
- エントロピー
- 分類誤差
などがあります。
問28
matplotlibでテキストをグラフ内に描画するメソッドについて説明している以下の文章のうち間違っているものを選べ
add_text()メソッドを用いる
メソッドの引数でグラフ内のどの位置に表示するかを座標で指定することができる
メソッドの引数で描画するテキストのサイズを指定することができる
text()メソッドを使用する
解説
グラフ内にテキストを描画するメソッドはtextメソッドが正しいです
問29
Pythonについて説明している以下の文章のうち間違っているものを選べ
Pythonで変数を使用する際には、必ず変数の型を最初に定義する必要がある
Pythonはオブジェクト指向のプログラミング言語である
機械学習ライブラリにscikit-learnがある
Pythonの予約語の数は他のプログラミング言語と比較して少ない
解説
変数に格納するオブジェクトの型定義をしなくても変数の定義が可能なので、必ず変数の型を最初に定義する必要があるとは言えません。
最新のPython3.10では、変数を定義する際には型の定義をする型の絞り込み機能が追加されました。
これによりライブラリの追加などをせず、変数定義の際に型の指定ができるようになりました。
問30
以下の関数f(x, y)のyに関する偏微分として正しいものを選べ
解説
数学の問題です。yについての偏微分という問題ですが、微分を行うと累乗の数値が乗算として前にだされ、累乗の数値は-1されます。xは微分対象ではありませんのでそのまま残ります。ちなみに微分対象の式に定数の加算や減算があった場合、偏微分の過程で消されますので他の問題の場合は留意しておきましょう。
問31
機械学習を用いたデータ分析において、データを入手してからモデルの学習を実施するまでの処理手順として、正しいものを選べ
データ入手→アルゴリズム選択→データ加工→データ可視化→モデルの学習
データ入手→アルゴリズム選択→データ加工→データ可視化→モデルの学習
データ入手→データ可視化→アルゴリズム選択→データ加工→モデルの学習
データ入手→データ加工→データ可視化→アルゴリズム選択→モデルの学習
解説
機械学習を用いてデータ分析をするには、まずはデータ分析をするデータを入手しましょう。次に、データを分析しやすくするために加工します。つまり、前処理と呼ばれる部分です。次にデータをより知ったり、数値では気付けなかった事が分かるように可視化をします。続いて機械学習をするアルゴリズムを選択します。アルゴリズムを決めたらデータを用いて学習する、という流れになります。
問32
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([0, 1, 2, 3, 4, 5])
B = np.array([6, 7, 8])
A2 = A.reshape(2, 3)
B2 = B[np.newaxis,:]
np.vstack([A2,B2])
array([[0, 1, 6], [2, 3, 7], [4, 5, 8]])
array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
array([[0, 3, 6], [1, 4, 7], [2, 5, 8]])
array([[0, 2, 4], [1, 3, 5], [6, 7, 8]])
解説
vstackで列方向で結合しています。ただ、その前にAはreshapeで2行3列の2次元配列に変換されているので、Bもnewaxisを使って2次元の配列に変換している流れになります。
問33
以下のようなpandasデータフレームdfがある。Dateカラムをこのデータフレームのインデックスにする場合のコードとして正しいものを選べ
df[“Date”].set_index()
df.reset_index(“Date”)
df.set_index(“Date”)
df.index(“Date”)
解説
問34
データサイエンティストやデータエンジニアが使用するツールについて説明している以下の文章のうち、正しいものを選べ
scikit-learnやNumPy、pandasの役割について理解しておく必要はない
たとえデータが小さくても、自分のPCでデータ分析を実施してはならない
anacondaなどの環境構築を行うためのツールは、分析の再現性という観点から実務では使ってはならない
Pythonを用いて前処理や集計をする必然性はなく、Excelを用いて実施してもよい
解説
前処理は欠損値を消したりする処理のことです。集計は特定の値の和ということです。これらをする場合はPythonで実施する必要はありません。Excelに限らず実現出来るのであれば他の方法でも実施して良いです。
問35
以下のコードのXXXに当てはまるものとして正しいものを選べ
#必要なモジュールのimport
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
boston = load_boston()
x, y = boston.data, boston.target
# 学習データとテストデータに分割
XXX
# 線形回帰をインスタンス化
lr = LinearRegression()
lr.fit(x_train, y_train)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
x_train, x_test, y_train, y_test = train_test_split(x, test_size=0.3)
x_train, x_test, y_train, y_test = lr.predict(x)
x_train, x_test = train_test_split(x, y, test_size=0.3)
解説
学習データとテストデータに分割ということからtrain_test_splitメソッドを使う選択肢が正しいとわかります。
問36
Jupyter Notebookについて説明している以下の文章のうち、間違っているものを選べ
Pythonだけでなく、Rも扱える
セルにコードを書き込むことで、単一行のコードもインタラクティブに実行できる。
macOS , windowsOS, ubuntuOSのどのOSでも使用できる
Jupyter Notebookには拡張機能がなく、カスタマイズすることができない
解説
Juputer Notebookには利用者が便利に操作出来るような拡張機能があり、自由にカスタマイズすることが出来ます。
問37
次の計算結果として正しいものを選べ
log2+log5
log10
log7
log25
log3
解説
底が同じ対数同士の加算は乗算をします。ちなみにこの問題では底が書かれていませんが、eが底になります。底がeの場合は省略可能だからです。
問38
データサイエンティストの役割について説明している以下の文章のうち、正しいものを選べ
技術の進歩が速い分野なので、論文などを読んで最新技術をキャッチアップする必要がある
Pythonで実装できるモデルを扱うことが多く、R言語を知っておく必要はない
業務中に自分でPCを修理する場合もあるので、コンピューターの内部構造や動作原理などを知っておく必要がある
データ分析さえできればよく、顧客の立場になり、その分析結果をどう使えるかまでを考えて分析する必要はない
解説
データサイエンティストはその役割として少しでも精度の高い技術を使う必要があります。そのため回答の選択肢のように常に最先端の技術を知る必要があります。方法として論文を読み込む必要があり、その範囲は学会で正式に発表されていないものも対象になりえます。
問39
以下のコードを実行した場合に、出力されるグラフとして正しいものを選べ(ランダムのデータを使っているので形状は変わってもよい)
fig, ax = plt.subplots()
x1 = [x for x in range(1,4)]
y1 = [1,2,3]
x2 = [x for x in range(1,6)]
y2 = [np.random.randint(10) for x in range(5)]
ax.bar(x1, y1, label="y1")
ax.plot(x2, y2, label="y2")
ax.legend()
plt.show()
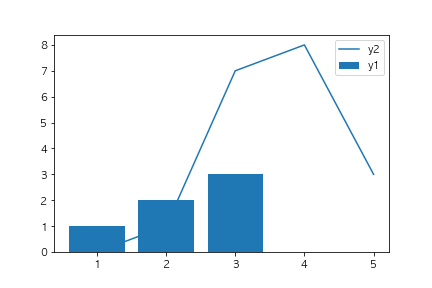
①
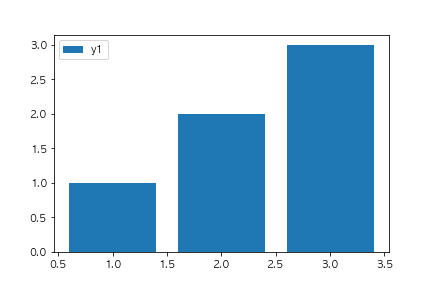
②
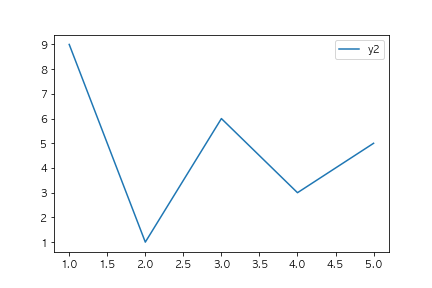
③
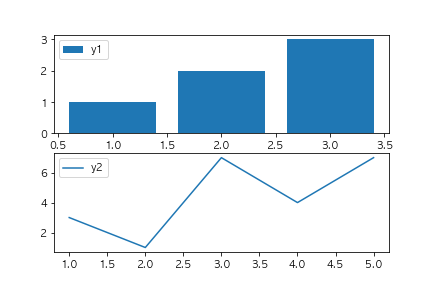
④
①
②
③
④
解説
barとplotメソッドを使っているため棒グラフと線グラフが表示されている選択肢に絞り込まれます。
またadd_subplotを使用していないことから①の選択肢が正しいことがわかります。
問40
Matplotlibの記述について正しいものを選べ
デフォルトで日本語フォントに対応しているため、日本語を表示させるための設定をする必要はない
今でも定期的にバージョンのアップデートなどがされており、世界中のデータ分析者に使われている
開発者は日本人である
2次元プロットだけでなく、3次元プロットにも対応している
解説
Matplotlibはグラフを描画するライブラリーです。
「デフォルトで日本語フォントに対応しているため、日本語を表示させるための設定をする必要はない」デフォルトは日本語ではありません。日本語設定をする必要があります。
「開発者は日本人である」違います。
「2次元プロットだけでなく、3次元プロットにも対応している」エビデンスによりますが、状況に応じて3次元で描画する場合もあります。