問1
import pandas as pd
df = pd.DataFrame({"国名":["日本","アメリカ","中国","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"面積":[380000, 9834000, 959700, 301300, 643800, 17100000, 8516000, 242500],
"人口/万人":[12700, 32800, 139300, 6000, 6700, 14500, 20900, 6600]})
上記コードを実行すると、以下のようなデータフレームが作成される。このデータフレームから中国のみのデータフレームを抜き出す処理として正しいものを選べ
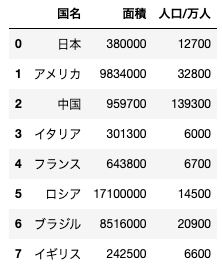
df.sort_values(“人口/万人”, ascending=True).iloc[-1,:]
df[df[“国名”]!=”中国”]
df[df.index==2]
df[“国名”]==”中国”
解説
データフレームから特定のデータを抽出する問題です。ここではデータフレームに対して、indexパラメータを指定してデータを特定しています。抽出したデータを再度データフレームにする必要があるので外側でもデータフレームにしています。
問2
以下のコードを実行した際に、Aについて述べているものとして、間違っているものを選べ
import numpy as np
A = np.random.rand(10,1)
Aの配列の形状は(10,1)である。
Aに格納されている値は全て、標準正規分布に従う乱数である。
中心が10、標準偏差が1に従う正規分布から生成された乱数が格納されている
Aに格納されている値は0以上1未満の浮動小数点数である。
解説
NumPyが提供するrandomモジュールは、乱数を扱う関数が提供されており、その中からrandom関数を呼び出しています。
今回のrand()関数は、0以上1未満の乱数数列を生成することができ、パラメータで配列の次元数を指定することができます。
np.random.rand(10, 1)を実行すると10行1列のデータが出力されますので、中心や標準偏差とは関係ありません。
問3
データサイエンティストとデータエンジニアの役割について説明している以下の文章のうち、正しいものを選べ
自分の取り組んだ前処理について、データサイエンティストが理解していればよく、データエンジニアが理解しておく必要はない
データエンジニアな機械学習の知識を知っている必要はない
企業や案件によっては、この2つの職種が厳密に分かれていない場合もあり、自分の役割を把握しながら、業務をすることが何よりも重要である
データサイエンティストはアルゴリズム構築や顧客へのレポーティングのみが仕事であり、プログラミングが書ける必要はない
解説
正解の選択肢の通りです。もちろん、データサイエンティストとデータエンジニアの役割を厳密に分けて採用している企業もあります。
問4
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([0, 1, 2, 3, 4, 5])
B = np.array([6, 7, 8])
A2 = A.reshape(2, 3)
B2 = B[np.newaxis,:]
np.vstack([A2,B2])
array([[0, 1, 6], [2, 3, 7], [4, 5, 8]])
array([[0, 1, 2], [3, 4, 5], [6, 7, 8]])
array([[0, 3, 6], [1, 4, 7], [2, 5, 8]])
array([[0, 2, 4], [1, 3, 5], [6, 7, 8]])
解説
vstackで列方向で結合しています。ただ、その前にAはreshapeで2行3列の2次元配列に変換されているので、Bもnewaxisを使って2次元の配列に変換している流れになります。
問5
データエンジニアの業務について説明している以下の文章のうち、間違っているものを選べ
集計ミスがないかの確認をする
データサイエンティストや顧客とコミュニケーションを取る
データベース言語を用いてデータの抽出を行う
機械学習のアルゴリズムを深い領域で理解する
解説
データエンジニアはデータ分析がしやすいようにデータを加工したり、企業の希望に合うようにデータを整頓する業務を担います。機械学習のアルゴリズムを理解し精度を上げる等の業務は機械学習エンジニアが担います。
問6
以下のような、日付に対して番号が格納されているデータフレームdfがある。このデータフレームを水曜日までの1週間単位の番号の合計を出力するコードとして正しいものを選べ
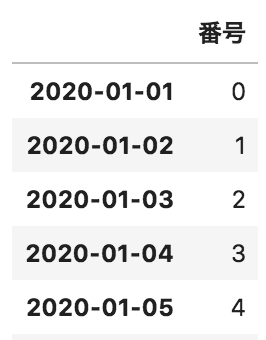
df.groupby(pd.Grouper(freq=”W-WED”)).count()
df.groupby(pd.Grouper(freq=”M-WED”)).sum()
df.groupby(pd.Grouper(freq=”W-WED”)).mean()
df.groupby(pd.Grouper(freq=”W-WED”)).sum()
解説
引数のfreqにはオフセットエイリアスと呼ばれる文字列をセットできます。(Wだと毎週の頻度でMだと毎月の頻度)
そして一部のオフセットエイリアスにはアンカー接尾辞をつかうことができます。(今回だと-WED)
対象のdfはindexが日付になっているので水曜日ごとにでグルーピングし合計を取得するsumメソッドを使い1週間毎の合計データを出力できます。
問7
データサイエンティストやデータエンジニアが使用するツールについて説明している以下の文章のうち、正しいものを選べ
scikit-learnやNumPy、pandasの役割について理解しておく必要はない
たとえデータが小さくても、自分のPCでデータ分析を実施してはならない
anacondaなどの環境構築を行うためのツールは、分析の再現性という観点から実務では使ってはならない
Pythonを用いて前処理や集計をする必然性はなく、Excelを用いて実施してもよい
解説
前処理は欠損値を消したりする処理のことです。集計は特定の値の和ということです。これらをする場合はPythonで実施する必要はありません。Excelに限らず実現出来るのであれば他の方法でも実施して良いです。
問8
以下のような各日付に対して、利用回数と利用料金が格納されたデータフレームdfがある。このdfの欠損値を0で埋める処理として正しいものを選べ
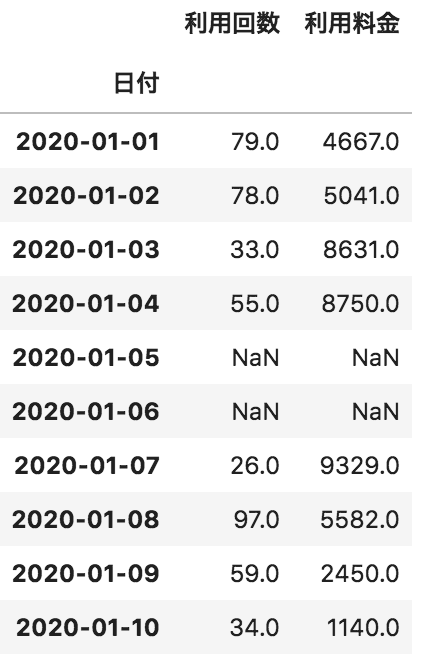
df.fillna()
df.fillna(method=”ffill”)
df.dropna(0)
df.fillna(0)
解説
fillnaメソッドを使うと欠損値(Na/NaN)の値を埋めることができます。問題文では平均値で埋めるとあるので引数に0を適用します。
問9
以下の文章のうちOne-hotエンコーディングの説明として正しいものを選べ
各カテゴリーラベルごとのカラムが新たに生成されるため、特徴量の数は増える
各カテゴリーを1,2,3…と数値に変換する処理である
カラムごとに0~1の範囲に収まるようにデータを変換する処理である
各カテゴリーを列として展開し、該当する値の列は1、それ以外の列は-1が入力される
解説
特定の変数の種類分特徴量が増えます。以下のようなデータがある場合に
1 2 3 |
name favorite_food 'taro' apple 'jiro' orange |
このように変換されて特徴量である列の数が増えます。
1 2 3 |
name apple orange 'taro' 1 0 'jiro' 0 1 |
問10
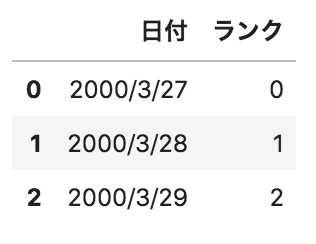
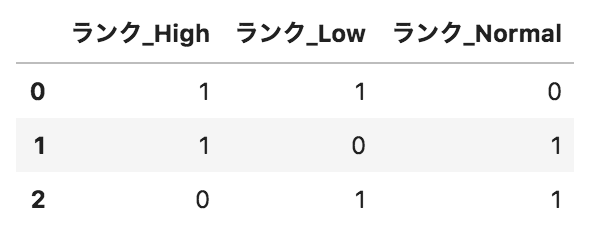
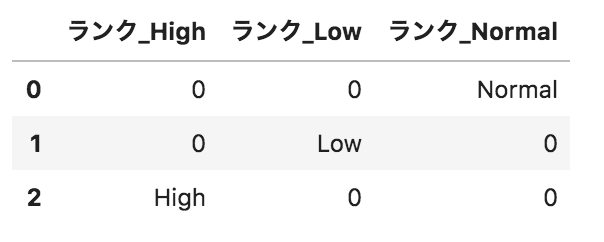
以下のようなpandasデータフレームdfがある。このデータフレームに対して、
pd.get_dummies(df.loc[:,"ランク"],prefix="ランク")
を実行した場合の出力として正しいものを選べ。
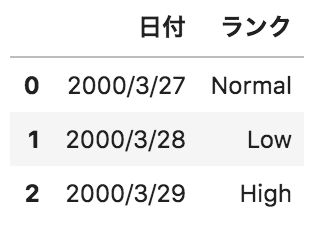
選択肢
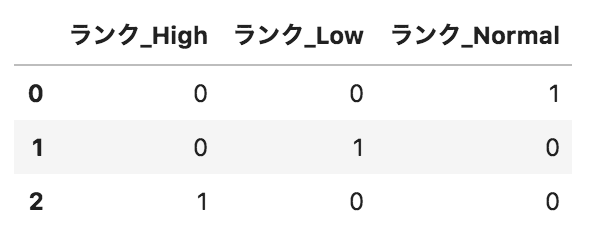
①
②
③
④
①
②
③
④
解説
get_dummiesメソッドでカテゴリデータを0または1に変換しています。
問11
ファイルの入出力の際に使用する、open関数について説明している以下の文章のうち、間違っているものを選べ
ファイルの入出力の際に使用する文字列のエンコーディングを指定できる
open関数が扱えるファイルの拡張子は、txtのみである
open関数を用いる際には、ファイルの閉じ忘れを防ぐために、with文を併用するとよい
書き込み用でファイルを開く場合には、modeの引数に’w’を指定するとよい
解説
open関数が扱えるファイルの拡張子は、txt以外も扱えます。
問12
matplotlibのpieメソッドを用いて円グラフのある要素だけずらして表示する場合に指定する引数として正しいものを選べ
explode
startangle
radius
counterclock
解説
explode引数にどのくらいの比率で切り出すかを示したリストを渡すことでグラフの表示を変更できます。
1 |
ax.pie(rate, explode=[0.4, 0, 0, 0, 0, 0]) |
問13
三角関数でないものを以下の選択肢から選べ
cosx
sinhx
tanx
sinx
解説
三角関数ではないのは解答のsinhxです。
問14
scikit-learnで実装されているk-means法について説明している以下の文章のうち間違っているものを選べ
クラスターの重心位置の更新計算は、指定した回数分だけ行われる
教師なし学習であるため、教師ラベルは必要ない
initの引数に”random”を指定すると、最初のクラスター点をデータの中からランダムに選ぶため、初期値依存性がある
クラスターの個数は、使用者が指定する必要がある
解説
クラスターの重心位置の更新計算は、指定した回数分だけ行われる、が誤りです。
問15
以下のコードの後に、np.dot(a, b)を実行した場合の出力と同じにならないものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = a.copy()
a = a.reshape(3,2)
a.dot(b)
a @ b
np.matmul(a,b)
np.multiply(a,b)
解説
NumPyの行列積メソッドの問題です。dot、@、matmulは全て行列積のメソッドですが、multiplyはスカラー倍のメソッドになります。
問16
データサイエンティストに求められる能力として必須ではないものを選べ
プログラミング能力
案件を獲得するための営業能力
アルゴリズム構築に必要な数理的能力
顧客へわかりやすく分析結果を伝えるためのレポーティング能力
解説
データサイエンティストは企業をサポートするために、アルゴリズムや統計等を活用して有益な知見を見出す業務を担います。案件を獲得するための営業力は不要です。
問17
決定木の不純度の指標として使用される「ジニ不純度」の説明している以下の文章のXXXとYYYに当てはまる組みとして正しいものを選べ
ある2つのカテゴリー(ラベル0とラベル1)を持つ特徴量を分割する場合のジニ不純度は、ラベル0なのにラベル1と割り振られる確率とラベル1なのにラベル0と割り振られる確率のXXXを考える必要がある。クラス0である確率をP(0)、クラス1である確率をP(1)とすると、求めるジニ不純度は
となる
XXX = 和, YYY = 2
XXX = 積, YYY = 2
XXX = 積, YYY = 1/2
XXX = 和, YYY = 1/2
解説
ジニ不純度を求める考え方は説明文の通りです。適切な単語については公式の観点で説明をします。ジニ不純度を求める公式は下記のようになります。
「ラベル0なのにラベル1と割り振られる確率とラベル1なのにラベル0と割り振られる確率」とはつまり間違える確率です。発生する確率の反対が間違える確率ですので1から発生する確率を減算しています。2乗は式変換すると発生するものとなります。
問18
scikit-learnのmetricsモジュールのclassification_report関数で出力されないものとして正しいものを選べ
AUC
適合率
再現率
F値
解説
以下出力される値です
precision 適合率
recall 再現率
f1-score F値
support テストデータの件数
accuracy 正解率
macro avg マクロ平均
weighted avg 重み付き平均
問19
以下の1月のデータが格納されたデータフレームAと2月のデータが格納されたデータフレームBを行方向にデータフレームを結合するコードとして、正しいものを選べ(AとBのカラム名は全て同じものとする)
A
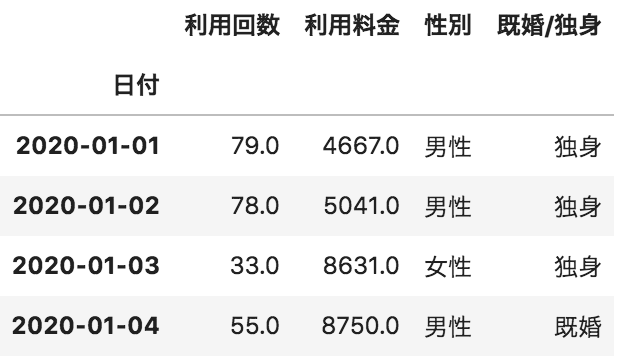
B
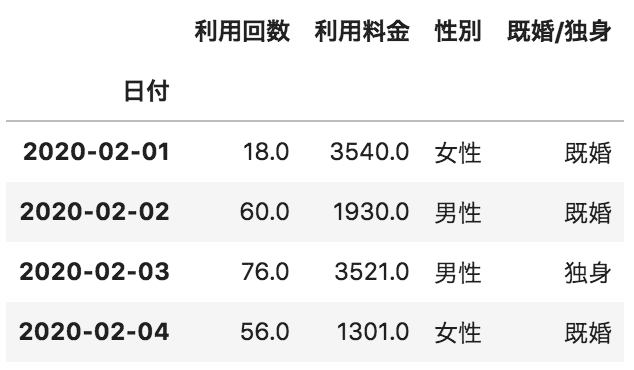
pd.concat([A, B], axis=1)
pd.concat([A, B], axis=0)
pd.merge([A, B], axis=0)
pd.join([A, B], axis=0)
解説
concatメソッドでaxis=0を設定するとindex方向(行)に結合します。
問20
set型のデータに関して説明している以下の文章のうち、正しいものを選べ
標準のデータ型にはなく、使う場合はモジュールをインポートする必要がある
重複しない要素を含み、集合演算をする場合に用いられる
イミュータブルなデータ型であり、要素の追加や削除はできない
データの各要素が、keyとvalueという2組みのデータから成り立ち、それぞれ取り出すことができる
解説
setオブジェクトは重複しない要素を含み、一意な値のみが要素として残ります。
iterable から要素を取り込んだ、新しい set もしくは frozenset オブジェクトを返します。
出典元 「組み込み型」(2021年12月23日11時00分 UTC版) 『組み込み型 — Python 3.10.0b2 ドキュメント』
問21
次の計算結果として正しいものを選べ
log2+log5
log10
log7
log25
log3
解説
底が同じ対数同士の加算は乗算をします。ちなみにこの問題では底が書かれていませんが、eが底になります。底がeの場合は省略可能だからです。
問22
以下のような、日付に対して番号が格納されているデータフレームdfがある。このデータフレームの月ごとの番号の平均を出力するコードとして正しいものを選べ
df.groupby(pd.Grouper(freq=”W”)).mean()
df.groupby(pd.Grouper(freq=”M”)).mean()
df.groupby(pd.Grouper(freq=”Y”)).mean()
df.groupby(freq=”M”).mean()
解説
引数のfreqにはオフセットエイリアスと呼ばれる文字列をセットできます。(Mだと毎月の頻度Wだと毎週の頻度)
対象のdfはindexが日付になっているので月ごとにでグルーピングし平均を取得するmeanメソッドを使い月毎の平均データを出力できます。
問23
pipを用いてXXXXというパッケージをアンインストールする場合に使用するコマンドとして正しいものを選べ
pip remove XXXX
pip uninstall XXXX
pip detach XXXX
pip demount XXXX
解説
pip を使ってパッケージをアンインストールする方法は pip uninstall を使用します。
出典元 「pip」(2021年12月23日14時00分 UTC版) 『pip uninstall — pip 9.1.0.dev0 ドキュメント』
問24
dfと名付けられている、以下のようなデータフレームがある。このデータフレームから、人口/万人カラムを削除する場合のコードとして正しいものを選べ
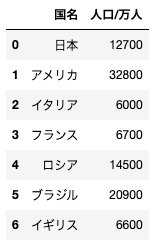
df.drop(“人口/万人”, axis=1)
df.drop(“人口/万人”, axis=0)
df.drop[“人口/万人”]
df[“人口/万人”].drop()
解説
データフレームから特定の列や列を削除する場合には drop メソッドを使います。ここでは列を削除したいので axis=1 を指定しています。
問25
機械学習を用いたデータ分析について説明している文章のうち、正しいものを選べ
特徴量エンジニアリングを実施するためにも、扱っているデータの専門知識を勉強することは重要である
前処理や基礎集計は分析業務の初期段階で一度実施するだけでよく、再度これらの処理手順に戻ることはない
データ分析は結果だけ示せばよいので、データサイエンティストやデータエンジニアには説明責任は生じない
分析要件は顧客が理解していればよく、データサイエンティストやデータエンジニアは分析要件の理解をする必要はない
解説
機械学習を用いたデータ分析を実施する際に、扱うデータの専門知識(ドメイン知識)を持っていることは重要です。例えば血圧についてデータ分析をする時に、20代の平均血圧と50代の平均血圧のを知っているという専門知識を持っている人といない人でデータ分析をさせた場合は分析の方針や結果について大きな差が出るというのはイメージしやすいと思います。
問26
以下のような日付ごとの利用回数と利用料金が格納されたpandasデータフレームdfがある。このデータフレームdfの利用回数の「最頻値」を出力するコードとして正しいものを選べ
df[“利用回数”].median()
df[“利用回数”].count()
df[“利用回数”].mean()
df[“利用回数”].mode()
解説
modeメソッドを使うと最頻値を取得できます。
問27
以下のコードを実行した場合に出力されるグラフとして正しいものを選べ。
fig, ax = plt.subplots()
x = [1,2,3]
y1 = [10, 20, 30]
y2 = [30, 20, 10]
ax.bar(x, y1)
ax.bar(x, y2, bottom=y1)
plt.show()
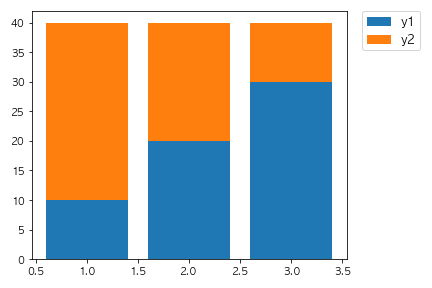
①
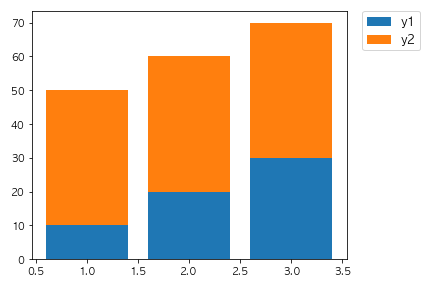
②
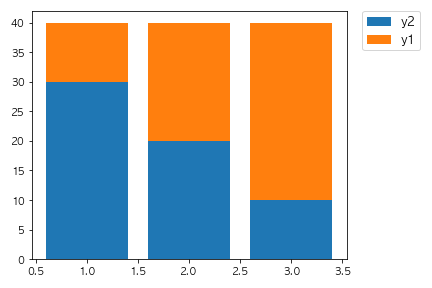
③
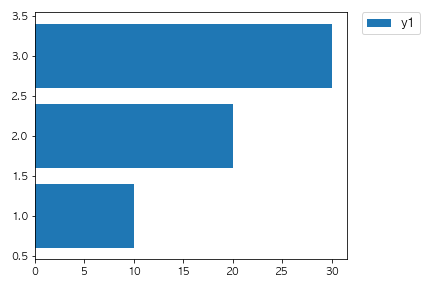
④
①
②
③
④
解説
bottom=y1でベースとなるデータを指定しています。
2回目のax.barの引数で設定されていることからy2はy1の上に積み上げることができます。
数値を変えたりbottomの対象を変えたりして挙動を確認してみましょう。
問28
以下のコードの出力として正しいものを選べ
A = [x for x in range(10)]
B = {x for x in range(20)}
if len(A)==10:
print("A")
elif len(A)==10&len(B)==20:
print("A,B")
else:
print("None")
A
A, B
None
A A, B
解説
初めにAという変数に10個の要素を生成します。条件分岐のif文でAのlenを用いて、10と等しいかを判断しています。もちろん等しいので、print文にてAが出力されるという流れになります。
問29
添付写真のようなpandasデータフレームから、以下のデータが格納されたcsvファイル(example.csv)を出力するためのコードとして正しいものを選べ
name of country,area
日本,380000
アメリカ,9834000
中国,959700
イタリア,301300
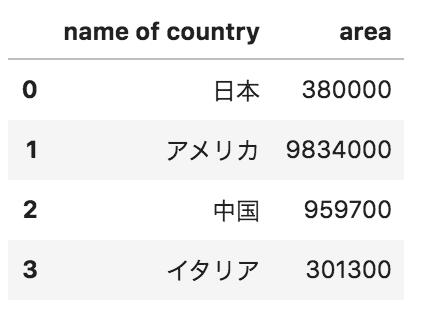
df.to_csv(“example.csv”)
df.output_csv(“example.csv”, index=False)
df.to_excel(“example.csv”, index=True)
df.to_csv(“example.csv”, index=False)
解説
データフレームをcsvに変換するメソッドは to_csv() を用います。index のパラメータを使うと行数を表示できます。今回の出力イメージには name of country の左側に行数の表示がありませんで、 index=False を用いています。
問30
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.eye(4)
first, second = np.vsplit(A, [3])
second.T
array([[0., 0., 0., 1.]])
array([[0., 0., 1., 0.], [0., 0., 0., 1.]])
array([[0., 0.], [0., 0.], [1., 0.], [0., 1.]])
array([[0.], [0.], [0.], [1.]])
解説
NumPyのメソッドの問題です。4行4列の単位行列を作成したあと、vsplitで3行目をsecondに入れます。1行4列のデータを転置しているので4行1列の選択肢が正解になります。
問31
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[0, 1, 2, 3, 4]])
B = np.full((1, 5), 1)
A[A>=B]
array([1, 2, 3, 4])
array([False, True, True, True, True])
array([[1, 2, 3, 4]])
array([[False, True, True, True, True]])
解説
numpyの問題です。特にここでは条件を満たす要素の取得をしています。A>=Bの条件を満たすものは正解の選択肢になります。
問32
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
np.log(np.exp(np.eye(2)))
array([[ 0., -inf], [-inf, 0.]])
array([[2.71828183, 1. ], [1. , 2.71828183]])
array([[1., 0.], [0., 1.]])
array([[1., 1.], [1., 1.]])
解説
NumPyの各種メソッドの問題です。eyeメソッドで2行2列の単位行列を作成します。続いてここに指数関数のexpメソッドを実施します。結果は次のようになります。array([[2.71828183, 1.], [1., 2.71828183]])これはe(ネイピア数)の1乗は2.71828183になることと、eの0乗は1になるからです。最後に対数を取ります。底をeとした対数がeの場合、1が出力され、底をeとした対数が1の場合0が出力されます。
問33
線形回帰について説明している以下の文章のうち正しいものを選べ
特徴量が5個以上あるデータには用いることができない
過学習することがないので、検証データを用意する必要はない。
分類する予測モデルを構築する際に使用するアルゴリズムである
L1正則化やL2正則化を用いることで過学習を抑えることができる
解説
線形回帰を用いて機械学習をする場合、学習や推定においてデータの上限はありません。過学習は起きるので扱う場合は検証データを用意したほうが良いと言えます。分類以外の予測モデルも構築が出来ます。線形回帰は過学習を抑えるために正則化を用いれます。L1正則化(Lasso回帰)とL2正則化(Ridge回帰)には違いがあります。前者は重みの合計を足したもので、後者は重みの二乗の合計を足したものです。
問34
以下のようなデータフレームdfがある。このデータフレームから、B列の値が3000以上のデータフレームを抽出するコードとして正しいものを選べ。
import pandas as pd
df = pd.DataFrame({"A":[10,200,3000,40000],
"B":[1000,2000,3000,4000]})
df[[“B”]>=3000]
df[“B”]>=3000
df[df[“B”]>=3000]
df[df[“B”]>=3000][“B”]
解説
データフレームからデータを抽出する問題です。大きな流れはデータフレームからデータを抽出して再度データフレームに入れるイメージです。後、演算子に注意しましょう。
問35
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
横軸に利用回数、縦軸に利用料金の散布図を描画するためのコードとして正しいものを選べ
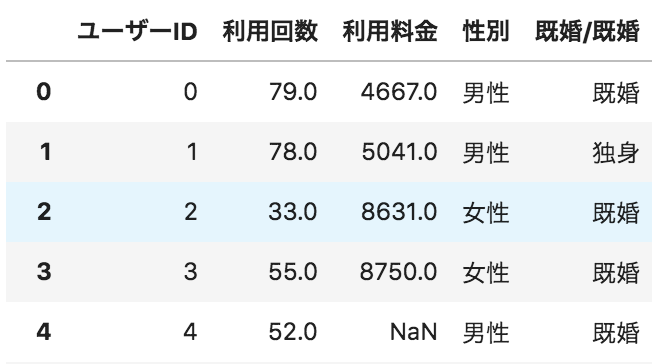
①
import matplotlib.pyplot as plt
plt.scatter(df["利用回数"],df["利用料金"])
plt.show()
②
import matplotlib.pyplot as plt
plt.scatter(df["利用料金"],df["利用回数"])
plt.show()
③
import matplotlib.pyplot as plt
plt.plot(df["利用回数"],df["利用料金"])
plt.show()
④
import matplotlib.pyplot as plt
df["利用回数"].scatter(df["利用料金"])
plt.show()
①
②
③
④
解説
第一引数にx軸, 第二引数にy軸にあたるものをセットします。
問36
以下の文章のうちF値の説明として正しいものを選べ
適合率と再現率の調和平均
正例と予測したデータのうち、実際に正例であるデータの割合
実際の正例のデータのうち正例と予測したデータの割合
予測の正負と実際のデータの正負が一致したデータの割合
解説
F1は「PrecisionとRecallの調和平均」が正解です。
求める公式は次の通りです。
問37
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
性別ごとの利用回数のヒストグラムを別々に(※)描画するコードとして正しいものを選べ
※1つのグラフ内ではなく、男性のヒストグラム、女性のヒストグラムをそれぞれ別のグラフオブジェクトとして描画するという意味です
df["利用回数"].hist(by=df["性別"])
plt.show()
①
df["性別"].hist(by=df["利用回数"])
plt.show()
②
df["利用回数"].hist()
plt.show()
③
df.groupby("性別")["利用回数"].hist()
plt.show()
④
①
②
③
④
解説
byで指定した値ごとにヒストグラムのグループが作成されます。
仮に今回
1 |
df["性別"].hist(by=df["利用回数"]) |
byに利用回数を指定した場合は利用回数ごとのヒストグラムが作成されてしまいます(5つのヒストグラムのグループが作成される)
問38
特徴量の正規化について説明している以下の文章のうち、間違っているものを選べ
特徴量の最大値が1、最小値が0となるように変換をする、最大最小正規化が存在する
特徴量のオーダーが大きく異なる場合は正規化を実施する必要はない
データの分布が標準正規分布に従うように変換する、分散正規化が存在する
scikit-learnには正規化を行うためのモジュールが存在する
解説
正規化(せいきか、英語: normalization)とは、データ等々を一定のルール(規則)に基づいて変形し、利用しやすくすること。
出典元 「正規化」(2021年12月23日19時00分 UTC版) 『ウィキペディア(Wikipedia)』
問39
R言語について説明している以下の文章のうち、正しいものを選べ
DeepLearningのフレーワークにはR用のパッケージは存在しない
Rで機械学習モデルを構築する場合、scikit-learnのR用パッケージをインストールしなければならない
R言語はグラフ描画をするためのパッケージが存在しない
RにはC++を使うためのパッケージが存在し、高速化をする際によく用いられる
解説
「RにはC++を使うためのパッケージが存在し、高速化をする際によく用いられる」例としてdplyrというパッケージが存在しています。plyr の派生パッケージでデータフレームの処理を高速に行います。
問40
venvやAnacondaで作成した仮想環境から抜ける際に使用するコマンドとして正しいものを選べ
exit
deactivate
quit
escape
解説
venvやAnacondaで作成した仮想環境から抜ける際に使用するコマンドは deactivate です。
出典元 「venv — 仮想環境の作成」(2021年12月23日14時00分 UTC版) 『venv — 仮想環境の作成 — Python 3.10.0b2 ドキュメント』