| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
次の計算結果として正しいものを選べ
log2+log5
log10
log7
log25
log3
問2
線形回帰の損失関数に対して、Ridge回帰とLasso回帰が追加している正則化項の組み合わせとして正しいものを選べ
(Ridge回帰, Lasso回帰)= (L2正則化項, L1正則化項)
(Ridge回帰, Lasso回帰)= (L1正則化項, L2正則化項)
(Ridge回帰, Lasso回帰)= (L1正則化項, L3正則化項)
(Ridge回帰, Lasso回帰)= (L3正則化項, L1正則化項)
解説
正則化項にはL1正則化(Lasso正則化)とL2正則化(Ridge正則化)というものがあります。
問3
階層的クラスタリングの結果の解釈に用いられる樹形図の説明として正しいものを選べ
データ数が多いと表示が困難であるため、一部だけ取り出して可視化するなどの工夫が必要である
樹形図の縦軸はクラスター内誤差平方和(SSE)である
次元削減をして特徴量を2変数にしてから、可視化しなければならない
最短距離法を用いた場合には、樹形図による可視化はできない
問4
Pythonのコーディング規約の名称として正しいものを選べ
Coding8
PEP8
PIP8
Flake8
問5
以下のコードのXXXに当てはまるものとして正しいものを選べ
#必要なモジュールのimport
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
boston = load_boston()
x, y = boston.data, boston.target
# 学習データとテストデータに分割
XXX
# 線形回帰をインスタンス化
lr = LinearRegression()
lr.fit(x_train, y_train)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
x_train, x_test, y_train, y_test = train_test_split(x, test_size=0.3)
x_train, x_test, y_train, y_test = lr.predict(x)
x_train, x_test = train_test_split(x, y, test_size=0.3)
問6
欠損値の対処方法として、間違っているものを選べ
One-hotエンコーディングを行う
その特徴量の統計的な代表値などで埋める
欠損値があるデータを用いない
欠損がある場合でも動作する機械学習アルゴリズムを選定する
問7
以下の関数のxに関する微分として正しいものを選べ
1
問8
AUCはROC曲線から算出されるが、具体的にはROC曲線の何を算出したものか。以下の中から正しいものを選べ
ROC曲線の面積
ROC曲線の縦軸の最大値
ROC曲線の横軸の最大値
ROC曲線の勾配(微分)
問9
A = (1,2,3), B = (4,5,6)のそれぞれ3成分からなる2つのベクトルがある。この2つのベクトルの内積として正しいものを選べ
32
27
315
問10
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 3, 5]])
B = np.array([[6, 8, 10]])
C = np.concatenate([A, B], axis=0)
D = np.diff(C, axis=0)
np.sum(D)
8
33
15
9
問11
scikit-learnのLogisticRegressionクラスを用いてモデルを構築した場合のラベルの予測確率を取得する関数として正しいものを以下の中から選べ
predict_proba()
predict()
get_params()
predict_log_proba()
問12
pipでインストールしたパッケージ一覧をテキストファイル(package_list.txt)に保存する際のコマンドとして、正しいものを選べ
pip output > package_list.txt
pip list output package_list.txt
pip freeze > package_list.txt
pip list < package_list.txt
問13
以下のようなグラフを描画するために、コードのXXX の部分に記述されるコードとして正しいものを選べ
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({"国名":["日本","アメリカ","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"人口/万人":[12700, 32800, 6000, 6700, 14500, 20900, 6600]})
plt.rcParams["font.family"] = "AppleGothic"
XXX
plt.xlabel("人口(万人)")
plt.show()
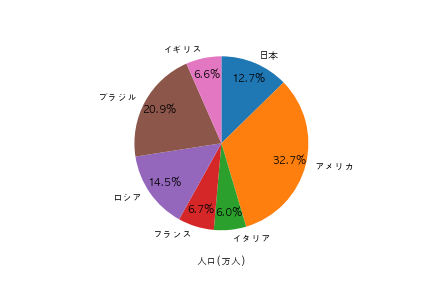
plt.pie(df["人口/万人"], labels=df["国名"], counterclock=False, startangle=90, autopct="%1.1f%%", pctdistance=0.8)
①
plt.pie(df["人口/万人"], labels=df["国名"], autopct="%1.2f%%", pctdistance=0.8)
②
plt.pie(df["人口/万人"], autopct="%1.2f%%", pctdistance=0.8)
③
plt.pie(df["人口/万人"], labels=df["国名"], counterclock=False, startangle=90, autopct="%1.1f%%", pctdistance=1.2)
④
①
②
③
④
問14
以下のような日付ごとの利用回数と利用料金が格納されたpandasデータフレームdfがある。このデータフレームdfの利用回数の「最頻値」を出力するコードとして正しいものを選べ
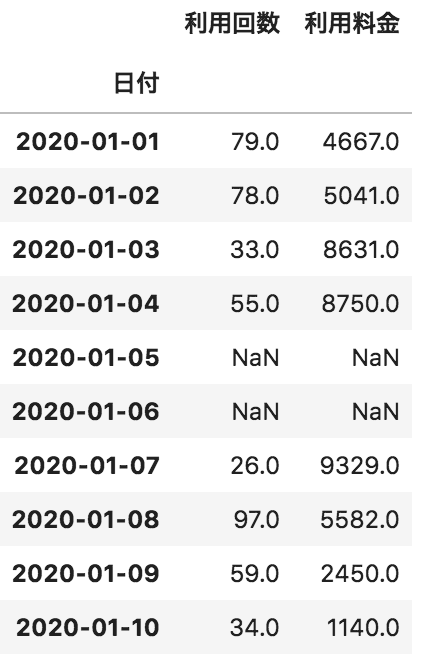
df[“利用回数”].median()
df[“利用回数”].count()
df[“利用回数”].mean()
df[“利用回数”].mode()
問15
以下のコードを実行した際に、Aについて述べているものとして、間違っているものを選べ
import numpy as np
A = np.random.rand(10,1)
Aの配列の形状は(10,1)である。
Aに格納されている値は全て、標準正規分布に従う乱数である。
中心が10、標準偏差が1に従う正規分布から生成された乱数が格納されている
Aに格納されている値は0以上1未満の浮動小数点数である。
問16
ランダムフォレストについて説明している以下の文章のうち、正しい選択肢を選べ
他の機械学習アルゴリズムと比較すると、欠損値の穴埋めや標準化などのデータの前処理を必要としないアルゴリズムである。
いくつかの決定木を作成するが、作成する木の数は自分で決めることができず、決まっている。
ランダムフォレストは、特徴量の数が多い分類問題にしか適用できない。
どの特徴量がモデルの出力に寄与しているかの程度を確認する指標が存在しない。
問17
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[0, 1, 2, 3, 4]])
B = np.full((1, 5), 1)
A[A>=B]
array([1, 2, 3, 4])
array([False, True, True, True, True])
array([[1, 2, 3, 4]])
array([[False, True, True, True, True]])
問18
Jupyter Notebookについて説明している以下の文章のうち、間違っているものを選べ
Pythonだけでなく、Rも扱える
セルにコードを書き込むことで、単一行のコードもインタラクティブに実行できる。
macOS , windowsOS, ubuntuOSのどのOSでも使用できる
Jupyter Notebookには拡張機能がなく、カスタマイズすることができない
問19
matplotlibのグラフ描画に関する以下の説明のうち、間違っているものを選べ
1つのグラフオブジェクト内では、1つのフォントしか指定できない
日本語の文字列にも対応しているフォントがデフォルトでは指定されていない
グラフの軸ラベルの文字列を回転させることはできる
縦軸が左右にある2軸グラフを描画することはできる
問20
クラスタリング手法として適切でないものを以下の中から選べ
k-近傍法
k-means法
ウォード法
単純連結法
問21
添付写真のようなpandasデータフレームから、以下のデータが格納されたcsvファイル(example.csv)を出力するためのコードとして正しいものを選べ
name of country,area
日本,380000
アメリカ,9834000
中国,959700
イタリア,301300
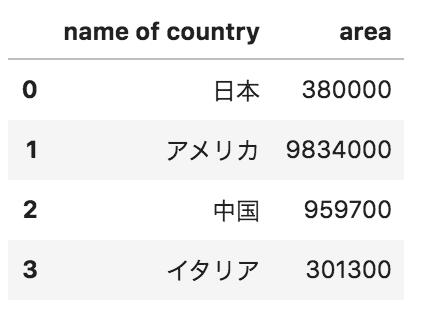
df.to_csv(“example.csv”)
df.output_csv(“example.csv”, index=False)
df.to_excel(“example.csv”, index=True)
df.to_csv(“example.csv”, index=False)
問22
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.eye(4)
first, second = np.hsplit(A, [2])
first
array([[1., 0.], [0., 1.], [0., 0.], [0., 0.]])
array([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.], [0., 0., 0.]])
array([[1., 0., 0., 0.], [0., 1., 0., 0.], [0., 0., 1., 0.]])
array([[1., 0., 0., 0.], [0., 1., 0., 0.]])
問23
pandasデータフレームA ,Bを列方向にインデックスをキーに用いてデータを連結する方法として、正しいものを選べ
pd.concat([A, B], axis=1)
pd.concat([df_num, df_per], axis=0)
pd.merge([df_num, df_per], axis=1)
pd.join([df_num, df_per], axis=1)
問24
数値データが格納されたpandasデータフレーム(df)に対して、各カラム間の相関係数を算出するコードとして正しいものを選べ
df.corr()
df.relative()
df.info()
df.describe()
問25
以下のようなデータが格納されたexample.csvというファイルをpandasデータフレームとして読み込むためのコードとして正しいものを選べ。
国名,面積
日本,380000
アメリカ,9834000
中国,959700
イタリア,301300
import pandas as pd
df = pd.read_csv("example.csv")
①
import pandas as pd
df = pd.read_excel("example.csv")
②
import pandas as pd
df = pd.read_pickle("example.csv")
③
import pandas as pd
df = pd.load_csv("example.csv")
④
①
②
③
④
問26
以下の主成分分析を実施するコードのXXXに当てはまるものとして正しいものを選べ
※選択肢中に登場するdfは主成分分析を施す元データを意味する
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = XXX
fig, ax = plt.subplots()
ax.scatter(X_pca[:, 0], X_pca[:, 1])
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_xlim(-1.1, 1.1)
ax.set_ylim(-1.1, 1.1)
plt.show()
pca.fit_transform(df)
pca.transform(df)
pca.predict(df)
pca.fit(df)
問27
以下のようなデータフレームdfがある。このデータフレームから国名カラムのみのデータフレームを抽出する際のコードとして正しくないものを選べ
df.loc[:,[“name of country”]]
df.iloc[[0],:]
df.filter([“name of country”])
df[[“name of country”]]
問28
シグモイド関数について説明している以下の文章のうち、正しいものを選べ
ニューラルネットワークの活性化関数として使われる関数であり、この関数の出力は0より大きく1より小さい
ニューラルネットワークの活性化関数として使われる関数であり、入力に対して線形変換を施す
線形回帰を使用する際の仮定関数であり、これにより誤差が小さくなるように学習することができる
以下の数式で表される関数であり、この関数の出力は0以上1以下である
問29
以下の配列の形状として正しいものを選べ。
array([[1,2,3], [4,5,6]])
(3, 2)
(1, 6)
(3, 3)
(2, 3)
問30
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A[0,:]
A[0,:]=0
B
array([1, 2, 3])
array([0, 0, 0])
array([[1], [4]])
array([[0], [0]])
問31
確率密度関数と確率の関係として正しいものを以下の中から選べ。
確率は確率密度関数の勾配である。
確率は確率密度関数の面積である。
確率は確率密度関数の幅の広さである。
確率は確率密度関数の最大値である。
問32
matplotlibについて説明している以下の文章のうち、正しいものを選べ。
matplotlibはグラフを描画する際に用いられるライブラリである
matplotlibは多次元配列の演算の記述を簡便にするために用いられるライブラリである
matplotlibはテーブルデータなどの表形式のデータをハンドリングする際に用いられるライブラリである。
matplotlibは、機械学習のアルゴリズムを用いてモデルを構築するために使用するライブラリである。
問33
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
問34
棒グラフが出力されるコードとして正しいものを選べ
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.bar(x, y)
plt.show()
①
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.scatter(x, y)
plt.show()
②
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.plot(x, y)
plt.show()
③
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.boxplot(x, y)
plt.show()
④
①
②
③
④
問35
以下のコードを実行した場合のBとCに格納されているデータの組み合わせとして、正しいものを選べ。選択肢は(B, C)の順に記載されている。
import numpy as np
A = np.eye(3)
B = np.count_nonzero(A)
C = np.sum(A)
(array([3]), array([3]))
(3, 3)
(True, 6)
(True, 3)
問36
サポートベクターマシンについて説明している以下の文章のうち正しいものを選べ
分類問題にのみ使えるアルゴリズムである
カーネルをrbfカーネルなどにすることで非線形構造を有するデータに対しても使用することができる
scikit-learnで実装されているサポートベクトルマシンを使う場合、サポートベクトルの数はハイパーパラメーターであり、任意に調整できる
教師なし学習のアルゴリズムである
問37
以下のコードの出力として正しいものを選べ
A = [x for x in range(10)]
B = {x for x in range(20)}
if len(A)==10:
print("A")
elif len(A)==10&len(B)==20:
print("A,B")
else:
print("None")
A
A, B
None
A A, B
問38
Pythonについて説明している以下の文章のうち間違っているものを選べ
Pythonで変数を使用する際には、必ず変数の型を最初に定義する必要がある
Pythonはオブジェクト指向のプログラミング言語である
機械学習ライブラリにscikit-learnがある
Pythonの予約語の数は他のプログラミング言語と比較して少ない
問39
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
性別ごとの利用回数のヒストグラムを別々に(※)描画するコードとして正しいものを選べ
※1つのグラフ内ではなく、男性のヒストグラム、女性のヒストグラムをそれぞれ別のグラフオブジェクトとして描画するという意味です
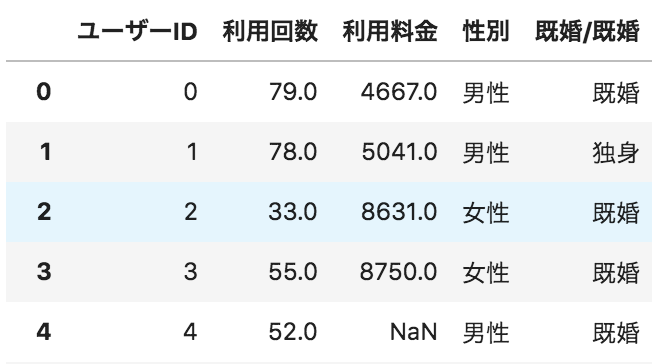
df["利用回数"].hist(by=df["性別"])
plt.show()
①
df["性別"].hist(by=df["利用回数"])
plt.show()
②
df["利用回数"].hist()
plt.show()
③
df.groupby("性別")["利用回数"].hist()
plt.show()
④
①
②
③
④
問40
以下のグラフのxに関して微分した際の値として正しいものを選べ。グラフのCは任意定数を意味する

発散
0
1