| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
以下の関数f(x, y)のyに関する偏微分として正しいものを選べ
解説
問2
以下のようなデータフレームdfがある。このデータフレームから、B列の値が3000以上のデータフレームを抽出するコードとして正しいものを選べ。
import pandas as pd
df = pd.DataFrame({"A":[10,200,3000,40000],
"B":[1000,2000,3000,4000]})
df[[“B”]>=3000]
df[“B”]>=3000
df[df[“B”]>=3000]
df[df[“B”]>=3000][“B”]
問3
matplitlibのpieメソッドを用いて円グラフを影をつけて表示させる場合の、pieメソッド内で指定する引数として正しいものを選べ
shadow=True
counterclock=True
explode=True
frame=True
問4
pipでインストールしたパッケージ一覧をテキストファイル(package_list.txt)に保存する際のコマンドとして、正しいものを選べ
pip output > package_list.txt
pip list output package_list.txt
pip freeze > package_list.txt
pip list < package_list.txt
問5
機械学習を用いたデータ分析について説明している文章のうち、正しいものを選べ
モデルの学習を実施したあとは、適切な検証データ、適切な指標を用いてモデルの精度の良し悪しを判断する必要がある
モデルの学習を実施さえすれば、十分な精度が保証されており、すぐに予測モデルを運用することができる
モデルの良し悪しを決めるための評価指標を適切に選ばなくても機械学習アルゴリズムで使っていれば問題ない
特徴量の選択は、適当に決めても精度に大きな影響はないため、特徴量エンジニアリングに時間を割くべきではな
問6
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 0]])
B = np.array([1, 0])
A @ B
array([1])
array([[1]])
array([[1, 1]])
array([[1, 1], [1, 1]])
問7
以下のコードの出力として正しいものを選べ
A = [x for x in range(10)]
B = {x for x in range(20)}
if len(A)==10:
print("A")
elif len(A)==10&len(B)==20:
print("A,B")
else:
print("None")
A
A, B
None
A A, B
問8
scikit-learnのGridSearchCVクラスには、もっとも精度が良い時のハイパーパラメーターの値を取得するための属性がある。その属性として正しいものを選べ
best_params_
best_estimator_
best_index_
cv_results_
問9
venvやAnacondaで作成した仮想環境から抜ける際に使用するコマンドとして正しいものを選べ
exit
deactivate
quit
escape
問10
Matplotlibを用いて、1つの描画オブジェクト中に2つのグラフを表示するコードとして正しいものを選べ
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2)
plt.show()
①
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.show()
②
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.show()
③
import matplotlib.pyplot as plt
plt.plot()
plt.show()
④
①
②
③
④
問11
ポアソン分布について述べている以下の文章のうち、正しいものを選べ
ポアソン分布におけるパラメーターは、平均値と標準偏差である。
交通事故の発生回数の予測、機械部品の故障予測など、稀に生じる事象についてモデル化したい場合に用いられる、離散型の確率分布である。
二項分布における試行回数と平均値が∞に発散する場合の極限を計算することで、ポアソン分布の確率密度関数は得られる
確率変数の実現値が連続変数である連続型確率分布である。
問12
以下の主成分分析を実施するコードのXXXに当てはまるものとして正しいものを選べ
※選択肢中に登場するdfは主成分分析を施す元データを意味する
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = XXX
fig, ax = plt.subplots()
ax.scatter(X_pca[:, 0], X_pca[:, 1])
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_xlim(-1.1, 1.1)
ax.set_ylim(-1.1, 1.1)
plt.show()
pca.fit_transform(df)
pca.transform(df)
pca.predict(df)
pca.fit(df)
問13
以下のようなデータフレームdfがある。このデータフレームから国名カラムのみのデータフレームを抽出する際のコードとして正しくないものを選べ
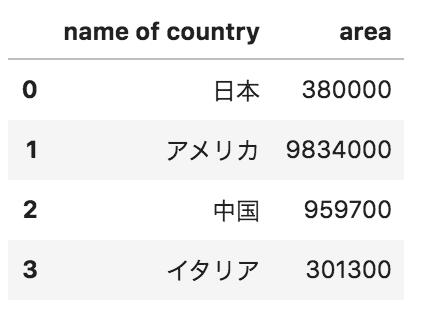
df.loc[:,[“name of country”]]
df.iloc[[0],:]
df.filter([“name of country”])
df[[“name of country”]]
問14
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
横軸に利用回数、縦軸に利用料金の散布図を描画するためのコードとして正しいものを選べ
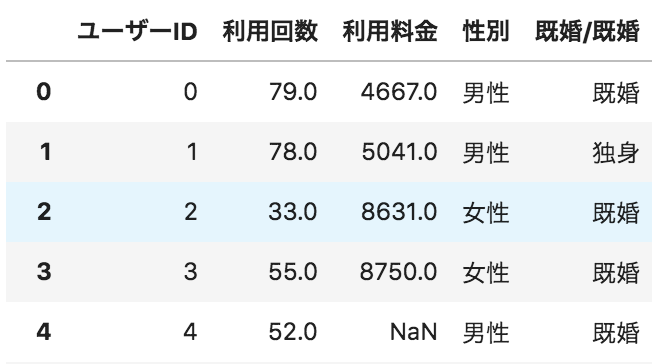
①
import matplotlib.pyplot as plt
plt.scatter(df["利用回数"],df["利用料金"])
plt.show()
②
import matplotlib.pyplot as plt
plt.scatter(df["利用料金"],df["利用回数"])
plt.show()
③
import matplotlib.pyplot as plt
plt.plot(df["利用回数"],df["利用料金"])
plt.show()
④
import matplotlib.pyplot as plt
df["利用回数"].scatter(df["利用料金"])
plt.show()
①
②
③
④
問15
pandasデータフレームA ,Bを列方向にインデックスをキーに用いてデータを連結する方法として、正しいものを選べ
pd.concat([A, B], axis=1)
pd.concat([df_num, df_per], axis=0)
pd.merge([df_num, df_per], axis=1)
pd.join([df_num, df_per], axis=1)
問16
次の計算結果として正しいものを選べ
log2+log5
log10
log7
log25
log3
問17
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームにその日の株価の増減値(終値-始値)に応じて、ランクを付与するコードの実装として正しいものを選べ
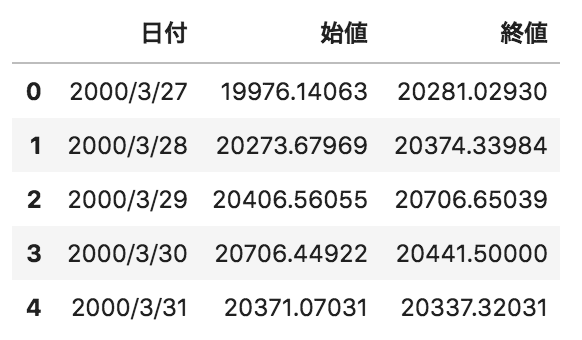
①
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df["増減値"].apply(add_rank)
②
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df.add_rank(df["増減値"])
③
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply(add_rank(df["終値"] - df["始値"]))
④
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply().add_rank(df["終値"] - df["始値"])
①
②
③
④
問18
以下のscikit-learnの説明のうち正しいものを選べ
学習データとテストデータに分割するためのメソッドががなく、多くの場合、自分で分割するための関数を用意しなければならない。
Deep Learningを行うことができない(ディープニューラルネットワークのモデルを構築することができない)
GPUで動かすためのサポートがない
pandasのデータフレームを扱うことができず、モデル作成の際は必ずNumPyを用いなければならない
問19
以下のような日付ごとの利用回数と利用料金が格納されたpandasデータフレームdfがある。このデータフレームdfの利用回数の「最大値」を出力するコードとして正しいものを選べ
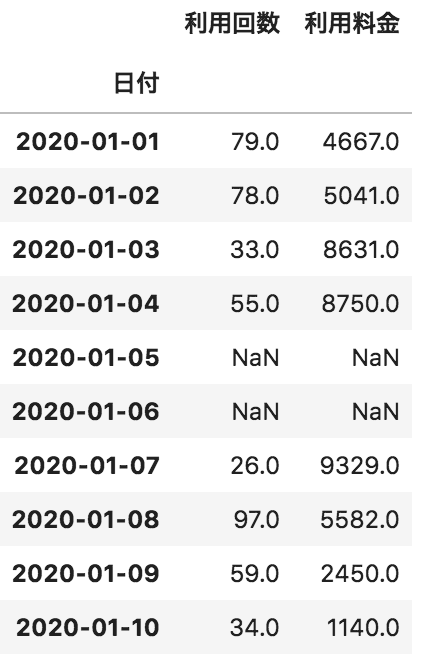
df[“利用回数”].mode()
df[“利用回数”].max()
df[“利用回数”].count()
df[“利用回数”].median()
問20
データサイエンティストやデータエンジニアが使用するツールについて説明している以下の文章のうち、正しいものを選べ
scikit-learnやNumPy、pandasの役割について理解しておく必要はない
たとえデータが小さくても、自分のPCでデータ分析を実施してはならない
anacondaなどの環境構築を行うためのツールは、分析の再現性という観点から実務では使ってはならない
Pythonを用いて前処理や集計をする必然性はなく、Excelを用いて実施してもよい
問21
モデルの評価指標について説明している以下の文章のうち、正しいものを選べ
適合率と再現率にはトレードオフの関係がある
分類問題の際に使用する評価指標は精度(accuracy)のみである
回帰問題の評価指標にはF値を算出することが多い
scikit-learnには適合率、再現率、F値を算出するためのモジュールが存在しなく、自分で混同行列から算出する必要がある
問22
三角関数でないものを以下の選択肢から選べ
cosx
sinhx
tanx
sinx
問23
決定木の不純度の指標として使用される「ジニ不純度」の説明している以下の文章のXXXとYYYに当てはまる組みとして正しいものを選べ
ある2つのカテゴリー(ラベル0とラベル1)を持つ特徴量を分割する場合のジニ不純度は、ラベル0なのにラベル1と割り振られる確率とラベル1なのにラベル0と割り振られる確率のXXXを考える必要がある。クラス0である確率をP(0)、クラス1である確率をP(1)とすると、求めるジニ不純度は
となる
XXX = 和, YYY = 2
XXX = 積, YYY = 2
XXX = 積, YYY = 1/2
XXX = 和, YYY = 1/2
問24
set型のデータに関して説明している以下の文章のうち、正しいものを選べ
標準のデータ型にはなく、使う場合はモジュールをインポートする必要がある
重複しない要素を含み、集合演算をする場合に用いられる
イミュータブルなデータ型であり、要素の追加や削除はできない
データの各要素が、keyとvalueという2組みのデータから成り立ち、それぞれ取り出すことができる
問25
Jupyter Notebookで用いられるマジックコマンドについて説明している以下の文章のうち、間違っているものを選べ
%timeitはセルに書かれた一行のプログラムに対して実行時間を、複数回施行して計測するコマンドである
%%timeitは1つのセルに対して実行時間を、複数回施行して計測するコマンドである
%matplotlib tk はコードセル直下にグラフを出力するためのコマンドである
%lsmagicはマジックコマンドの一覧を表示するコマンドである
問26
Matplotlibの記述について正しいものを選べ
デフォルトで日本語フォントに対応しているため、日本語を表示させるための設定をする必要はない
今でも定期的にバージョンのアップデートなどがされており、世界中のデータ分析者に使われている
開発者は日本人である
2次元プロットだけでなく、3次元プロットにも対応している
問27
カテゴリカル型やオブジェクト型のデータが格納されたpandasデータフレームに対して、describeメソッドを用いて算出することができない統計量として正しいものを選べ
ユニーク数
データ数
最頻(もっとも多く出現するデータ)のレコード数
最大文字数
問28
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 3, 5]])
B = np.array([[6, 8, 10]])
C = np.concatenate([A, B], axis=0)
D = np.diff(C, axis=0)
np.sum(D)
8
33
15
9
問29
シグモイド関数について説明している以下の文章のうち、正しいものを選べ
ニューラルネットワークの活性化関数として使われる関数であり、この関数の出力は0より大きく1より小さい
ニューラルネットワークの活性化関数として使われる関数であり、入力に対して線形変換を施す
線形回帰を使用する際の仮定関数であり、これにより誤差が小さくなるように学習することができる
以下の数式で表される関数であり、この関数の出力は0以上1以下である
問30
以下の文章のうち次元削減手法として適切でないものを選べ
k-means法
主成分分析(PCA)
線形判別分析(LDA)
t-SNE
問31
決定木について説明している以下の文章のうち、正しいものを選べ
情報利得の大きい順に特徴量が使用され、木が作られる
木が下に行けば行くほど、特徴量の情報利得は大きい
各葉においてデータを分割する際の閾値はあらかじめモデル作成者が決める必要がある
欠損値は除外するか、何かしらの値で埋めておく必要がある
問32
R言語について説明している以下の文章のうち、正しいものを選べ
DeepLearningのフレーワークにはR用のパッケージは存在しない
Rで機械学習モデルを構築する場合、scikit-learnのR用パッケージをインストールしなければならない
R言語はグラフ描画をするためのパッケージが存在しない
RにはC++を使うためのパッケージが存在し、高速化をする際によく用いられる
問33
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
サービス利用料金ごとの人数をヒストグラムで表示するためのコードとして正しいものを選べ
import matplotlib.pyplot as plt
df["利用料金"].hist()
plt.show()
①
import matplotlib.pyplot as plt
df["利用料金"].boxplot()
plt.show()
②
import matplotlib.pyplot as plt
df["利用料金"].value_counts().hist()
plt.show()
③
import matplotlib.pyplot as plt
plt.bar(df["利用回数"], df["ユーザーID"])
plt.show()
④
①
②
③
④
問34
ある変数xの標準偏差が1、ある変数yの標準偏差が2、この2つのxとyの共分散が2であるとき、この2変数のピアソンの相関係数として正しいものを選べ。
0.25
2
0.5
1
問35
以下のコードを実行すると、変数A, B, C, Dには1つだけ異なるデータが格納される(4つのうち3つは同じデータが格納される)。格納されているデータが他の変数と異なる変数を選べ。
import numpy as np
A = np.full(10, 10.0)
B = np.array([10])*10
C = np.zeros(10)+10
D = np.ones(10)*10
C
B
A
D
問36
正規分布に従う乱数を生成するNumPyのメソッドとして、正しいものを選べ
np.random.randn()
np.random.rand()
np.random.random()
np.random.uniform()
問37
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.linspace(0, 2, 5)
B = np.diff(A)*2
B == np.ones(4)
True
array([ 1, 1, 1, 1])
array([ True, True, True, True])
FALSE
問38
以下のコードを実行した際の出力として正しいものを選べ
A = [1]*10
A
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[10]
[[1],[1],[1],[1],[1],[1],[1],[1],[1],[1]]
[[10],[10],[10],[10],[10],[10],[10],[10],[10],[10]]
問39
以下のような、pandasデータフレームAとpandasデータフレームBがある。この2つのデータフレームの日付が一致する部分のみを列方向に結合したデータフレームを作成するコードとして正しいものを選べ
A
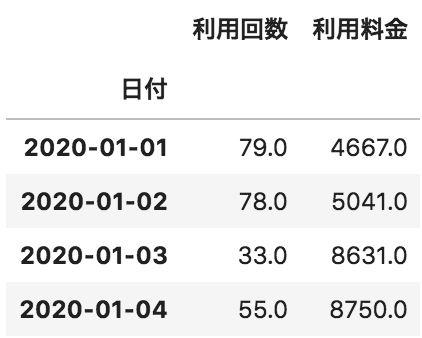
B
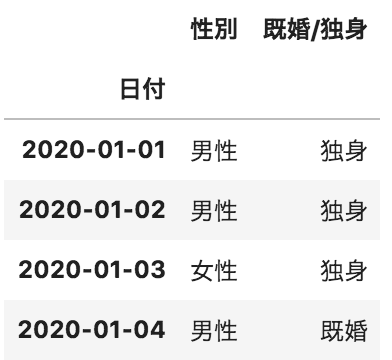
pd.merge(A, B, how=”left”, on=”日付”)
pd.join(A, B, how=”inner”, on=”日付”)
pd.merge(A, B, how=”inner”, on=”日付”)
pd.merge([A, B], how=”inner”, on=”日付”)
問40
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)