| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
以下のコードの後に、np.dot(a, b)を実行した場合の出力と同じにならないものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = a.copy()
a = a.reshape(3,2)
np.multiply(a,b)
np.matmul(a,b)
a @ b
a.dot(b)
解説
multiplyは引数の要素ごとに乗算します。今回はbroadcastできないためエラーにもなります。
その他の選択肢は内積と行列積をおこなうメソッドであり, np.dot(a, b)を実行した場合の出力と同じ結果を得ます。
問2
以下のグラフは、木曜日から日曜日のユーザーの支払い請求額に関する分布を示した箱ひげ図である。この箱ひげ図の説明として正しくないものを選べ
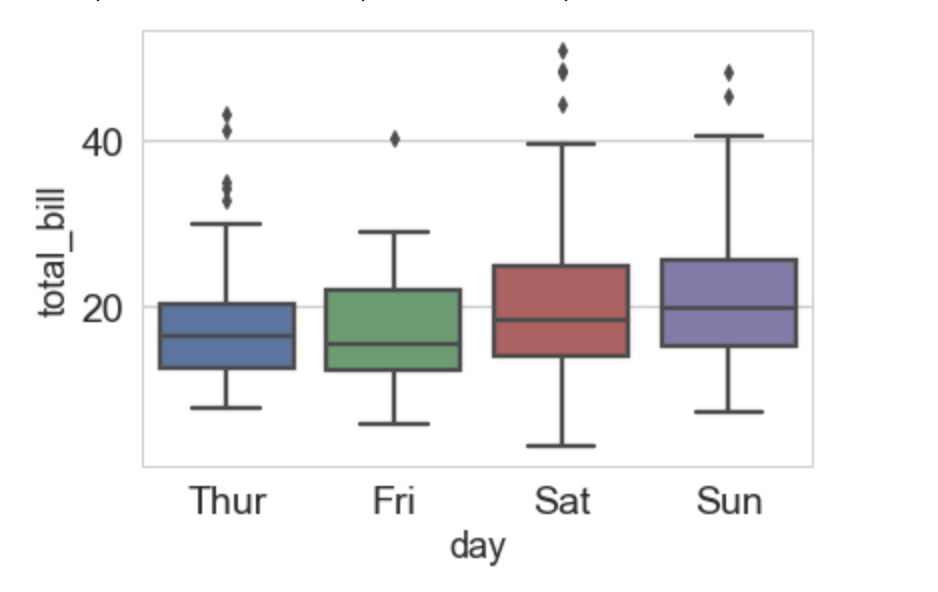
平均値は、日曜日がもっとも高い
第一四分位数がもっとも大きいのは、金曜日である
支払い請求額は土曜日がもっともばらついている
支払い請求額が最大のユーザーは、土曜日の利用である
問3
以下の説明のうち、最頻値の説明として正しいものを選べ。
データの中でもっとも大きい値のこと。
データを小さい順に並べて、ちょうど真ん中にくる値である。データの個数が偶数と奇数の場合で算出方法が異なる
もっとも多く出現するデータ・値であり、アンケートなどの最多回答者などがこれに相当する。
データ全体がどの程度ばらついているかを示す値。
問4
データエンジニアの役割について説明している以下の文章のうち、正しいものを選べ
データエンジニアはモデリングのみを担当することが多く、データの概要把握のためのデータ集計やデータ可視化を行うことはない。
データエンジニアが使用するツールはwindowsOSでしか動作しないものが多く、windowsOSを使わなければならない
データエンジニアはデータサイエンティストと連携して、予測モデルを構築するためのデータの前処理や抽出作業を行うことがある
データエンジニアはモデリングのみを担当することが多く、データの前処理を行うことはない
問5
pandasデータフレームdfをNumPy配列に変換する処理として正しいものを選べ
np.convert(df)
df.values
np.ndarray(df)
df.array
問6
0~9の整数が格納された配列A = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]を作成する方法として適していないものを選べ
A = ()
for x in range(10):
A.append(x)
①
A = list(range(10))
②
A = []
for x in range(10):
A.append(x)
③
A = [x for x in range(10)]
④
①
②
③
④
問7
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[0, 1, 2, 3, 4]])
B = np.full((1, 5), 1)
A[A>=B]
array([1, 2, 3, 4])
array([False, True, True, True, True])
array([[1, 2, 3, 4]])
array([[False, True, True, True, True]])
問8
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.eye(4)
first, second = np.hsplit(A, [2])
first
array([[1., 0.], [0., 1.], [0., 0.], [0., 0.]])
array([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.], [0., 0., 0.]])
array([[1., 0., 0., 0.], [0., 1., 0., 0.], [0., 0., 1., 0.]])
array([[1., 0., 0., 0.], [0., 1., 0., 0.]])
問9
Jupyter Notebookで用いられるマジックコマンドについて説明している以下の文章のうち、間違っているものを選べ
%timeitはセルに書かれた一行のプログラムに対して実行時間を、複数回施行して計測するコマンドである
%%timeitは1つのセルに対して実行時間を、複数回施行して計測するコマンドである
%matplotlib tk はコードセル直下にグラフを出力するためのコマンドである
%lsmagicはマジックコマンドの一覧を表示するコマンドである
問10
決定木について説明している以下の文章のうち、正しいものを選べ
情報利得の大きい順に特徴量が使用され、木が作られる
木が下に行けば行くほど、特徴量の情報利得は大きい
各葉においてデータを分割する際の閾値はあらかじめモデル作成者が決める必要がある
欠損値は除外するか、何かしらの値で埋めておく必要がある
問11
機械学習モデルの精度改善をする場合の措置として間違っているものを選べ
評価指標を変更する
学習データ量を増やす
ハイパーパラメーターのチューニング
特徴量の選定
問12
NumPy配列の要素のデータ型を確認するためのコマンドとして正しいものを選べ。
dtype
dypes
astype
astypes
問13
以下のコードを実行した場合にxxに格納されるデータとして正しいものを選べ。
import numpy as np
m = np.arange(4)
n = np.arange(4)
xx, yy = np.meshgrid(m,n)
array([[0, 1, 2, 3], [0, 1, 2, 3], [0, 1, 2, 3], [0, 1, 2, 3]])
array([[0, 1, 2, 3], [0, 1, 2, 3]])
array([0, 1, 2, 3])
array([0, 1, 4, 9])
問14
行列Aのサイズが(n,m)、行列Bのサイズが(m,n)のとき、この2つの行列の積ABのサイズとして正しいものを選べ
(n,n)
(m,m)
(m,n)
(n,m)
問15
datetimeモジュールについて説明している以下の文章のうち、誤っているものを選べ
取得する日付や日時のタイムゾーンを指定することができる
now()を使用することで、今日の日付を取得することができる
日数の差分を算出するなど、日付同士の演算をすることができない。
日時(datatime型)→文字列の変換はできるが、文字列→日時(datatime型)の変換はできない
問16
ランダムフォレストについて説明している以下の文章のうち、正しい選択肢を選べ
他の機械学習アルゴリズムと比較すると、欠損値の穴埋めや標準化などのデータの前処理を必要としないアルゴリズムである。
いくつかの決定木を作成するが、作成する木の数は自分で決めることができず、決まっている。
ランダムフォレストは、特徴量の数が多い分類問題にしか適用できない。
どの特徴量がモデルの出力に寄与しているかの程度を確認する指標が存在しない。
問17
A = (1,2,3) B = (4,5,6)の2つの座標がある。座標AB間のユークリッド距離として正しいものを選べ
27
9
3
問18
以下のコードを実行した際の出力として正しいものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = np.array([100,100,100])
np.vstack([a,b])
array([[ 0, 1, 10], [ 0, 1, 10], [100, 100, 100]])
array([0, 1, 10, 0, 1, 10, 100, 100, 100])
array([[ 0, 1, 10, 100], [ 0, 1, 10, 100], [100, 100, 100]])
array([[ 0, 1, 10, 100], [ 0, 1, 10, 100]])
問19
以下のコードを実行した際に、Aについて述べているものとして、間違っているものを選べ
import numpy as np
A = np.random.rand(10,1)
Aの配列の形状は(10,1)である。
Aに格納されている値は全て、標準正規分布に従う乱数である。
中心が10、標準偏差が1に従う正規分布から生成された乱数が格納されている
Aに格納されている値は0以上1未満の浮動小数点数である。
問20
決定木の不純度の指標として、間違っているものを以下の中から選べ
情報利得
ジニ不純度
エントロピー
分類誤差
問21
以下のようなpandasデータフレームdfがある。Dateカラムをこのデータフレームのインデックスにする場合のコードとして正しいものを選べ
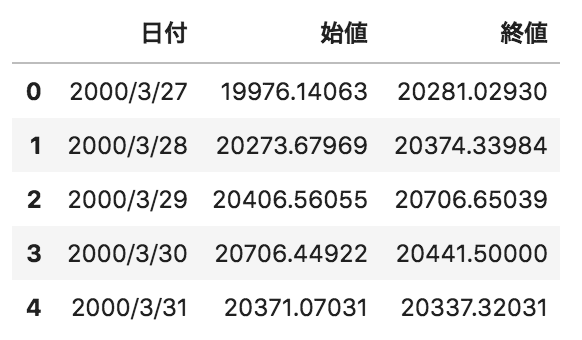
df[“Date”].set_index()
df.reset_index(“Date”)
df.set_index(“Date”)
df.index(“Date”)
問22
A = (1,2,3) B = (4,5,6)の2つの座標がある。座標AB間のマンハッタン距離として正しいものを選べ
9
3
27
問23
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームを始値の降順に並び替えるコードとして正しいものを選べ
df.sort(“始値”, ascending=False)
df.sort(“始値”)
df.sort_values(“始値”)
df.sort_values(“始値”, ascending=False)
問24
1×2×3×4×5と同じ意味を表す数式として正しいものを選べ
問25
matplotlibでテキストをグラフ内に描画するメソッドについて説明している以下の文章のうち間違っているものを選べ
add_text()メソッドを用いる
メソッドの引数でグラフ内のどの位置に表示するかを座標で指定することができる
メソッドの引数で描画するテキストのサイズを指定することができる
text()メソッドを使用する
問26
以下のコードを実行した際の出力として正しいものを選べ
A = [1]*10
A
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[10]
[[1],[1],[1],[1],[1],[1],[1],[1],[1],[1]]
[[10],[10],[10],[10],[10],[10],[10],[10],[10],[10]]
問27
A+Bが計算できない組み合わせとして、正しいものを以下の中から選べ。
A = np.array([[0,1,2]]) B = np.ones((3,1))
A = np.array([[0,1,2]]) B = np.ones((3,2))
A = np.array([[0,1,2]]) B = np.ones((1,3))
A = np.array([[0,1,2]]) B = np.ones((2,3))
問28
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 0]])
B = np.array([1, 0])
A @ B
array([1])
array([[1]])
array([[1, 1]])
array([[1, 1], [1, 1]])
問29
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームにその日の株価の増減値(終値-始値)を算出したカラムを追加するコードとして間違っているものを選べ
df.loc[:,”増減値”] = df.loc[:,”終値”] – df.loc[:,”始値”]
df.loc[:,”増減値”] = df.iloc[:,2] – df.iloc[:,1]
df[“増減値”] = df[“終値”] – df[“始値”]
df.loc[:,”増減値”] = df.loc[[“終値”]-[“始値”]]
問30
機械学習を用いたデータ分析において、データを入手してからモデルの学習を実施するまでの処理手順として、正しいものを選べ
データ入手→アルゴリズム選択→データ加工→データ可視化→モデルの学習
データ入手→アルゴリズム選択→データ加工→データ可視化→モデルの学習
データ入手→データ可視化→アルゴリズム選択→データ加工→モデルの学習
データ入手→データ加工→データ可視化→アルゴリズム選択→モデルの学習
問31
Matplotlibを用いて、1つの描画オブジェクト中に2つのグラフを表示するコードとして正しいものを選べ
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2)
plt.show()
①
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.show()
②
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.show()
③
import matplotlib.pyplot as plt
plt.plot()
plt.show()
④
①
②
③
④
問32
棒グラフが出力されるコードとして正しいものを選べ
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.bar(x, y)
plt.show()
①
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.scatter(x, y)
plt.show()
②
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.plot(x, y)
plt.show()
③
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.boxplot(x, y)
plt.show()
④
①
②
③
④
問33
以下のコードの出力として正しいものを選べ
import pandas as pd
df = pd.DataFrame({"A":[1,2,3,4,5], "B":[6,7,8,9,10]})
df["A"]>3

①

②

③

④
`
①
②
③
④
問34
A = (1,2,3), B = (4,5,6)のそれぞれ3成分からなる2つのベクトルがある。この2つのベクトルの内積として正しいものを選べ
32
27
315
問35
csvファイルをpandasで読み込む場合に、読み込むカラムを指定する方法として正しいものを選べ
※選択肢中の’data.csv’ は読み込む元データが格納されたcsvファイルとする
pd.read_csv(‘data.csv’, usecols=[カラム名])
pd.read_csv(‘data.csv’, index_col=[カラム名])
pd.read_csv(‘data.csv’, use_cols=[カラム名])
pd.read_csv(‘data.csv’, cols=[カラム名])
問36
データサイエンティストの役割について説明している以下の文章のうち、正しいものを選べ
技術の進歩が速い分野なので、論文などを読んで最新技術をキャッチアップする必要がある
Pythonで実装できるモデルを扱うことが多く、R言語を知っておく必要はない
業務中に自分でPCを修理する場合もあるので、コンピューターの内部構造や動作原理などを知っておく必要がある
データ分析さえできればよく、顧客の立場になり、その分析結果をどう使えるかまでを考えて分析する必要はない
問37
以下のコードを実行した場合のBとCに格納されているデータの組み合わせとして、正しいものを選べ。選択肢は(B, C)の順に記載されている。
import numpy as np
A = np.eye(3)
B = np.count_nonzero(A)
C = np.sum(A)
(array([3]), array([3]))
(3, 3)
(True, 6)
(True, 3)
問38
線形回帰の損失関数に対して、Ridge回帰とLasso回帰が追加している正則化項の組み合わせとして正しいものを選べ
(Ridge回帰, Lasso回帰)= (L2正則化項, L1正則化項)
(Ridge回帰, Lasso回帰)= (L1正則化項, L2正則化項)
(Ridge回帰, Lasso回帰)= (L1正則化項, L3正則化項)
(Ridge回帰, Lasso回帰)= (L3正則化項, L1正則化項)
問39
データエンジニアの役割について説明している以下の文章のうち、間違っているものを選べ
データベースの扱いは、サーバーサイドエンジニア が知っていればよく、SQLなどのデータベースを扱う言語をデータ分析者が知っておく必要はない
機械学習だけでなく、深層学習についても知っておく必要がある
データ数が100サンプルのデータを扱うこともありえる
クラウドサービスを用いてデータハンドリングを行う場合、金銭的、時間的コストを考えてコードを実装する必要がある
問40
以下のようなpandasデータフレームdfがある。このデータフレームに対して、
pd.get_dummies(df.loc[:,"ランク"],prefix="ランク")
を実行した場合の出力として正しいものを選べ。
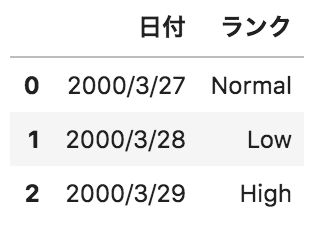
選択肢
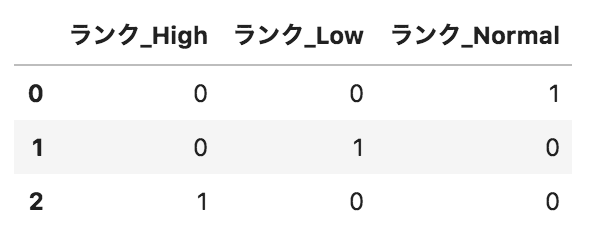
①
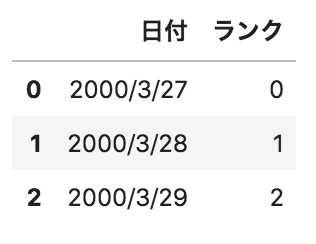
②
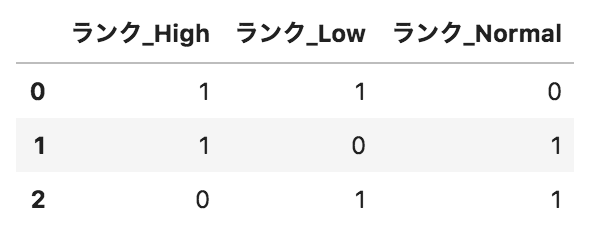
③
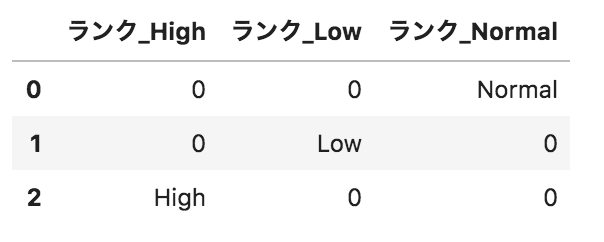
④
①
②
③
④