| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
1×2×3×4×5と同じ意味を表す数式として正しいものを選べ
問2
行列Aのサイズが(n,m)、行列Bのサイズが(m,n)のとき、この2つの行列の積ABのサイズとして正しいものを選べ
(n,n)
(m,m)
(m,n)
(n,m)
問3
matplotlibのグラフ描画に関する以下の説明のうち、間違っているものを選べ
1つのグラフオブジェクト内では、1つのフォントしか指定できない
日本語の文字列にも対応しているフォントがデフォルトでは指定されていない
グラフの軸ラベルの文字列を回転させることはできる
縦軸が左右にある2軸グラフを描画することはできる
問4
matplotlibのpieメソッドを用いて円グラフのある要素だけずらして表示する場合に指定する引数として正しいものを選べ
explode
startangle
radius
counterclock
問5
以下のコードの出力として正しいものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = np.array([[100],[100]])
c = np.concatenate([a,b],axis=1)
c = c.reshape(4,2)
np.dot(c, b)
array([[100, 101, 110, 200], [100, 101, 110, 200]])
array([[ 0, 100, 1000], [ 0, 100, 1000], [10000, 10000, 10000]])
array([[10000, 10200, 12000]])
array([[ 100], [11000], [ 100], [11000]])
問6
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
解説
行列積の問題です。
は2行2列と2行2列の行列積です。便宜上前者をA行列、後者をB行列とし、結果をC行列と呼びます。初めにA :
とB:
を行列積をするとどうなるかを確認しましょう。行列積の方法はAの1行目とBの1列目を始めに積和計算し、(1 * 1)+(0 * 0) =1 でC行列の1行1列目が求まります。次に、Aの1行目とBの2列目を計算し、(1 * 1) +(0 * 1) =1 でC行列の1行2列目が求まります。Aの2行目とBの1列目を計算し、(0 * 1) +(1 * 0) =0 でC行列の2行1列目が求まります。Aの2行目とBの2列目を計算し、(0 * 1) +(1 * 1) =1 でC行列の2行2列目が求まります。
問7
Matplotlibの記述について間違っているものを選べ
1つの描画オブジェクトの中に、複数のグラフを表示させることはできない
グラフの判例を描画するだけでなく、その表示位置やフォント、文字サイズも変更することができる。
描画したグラフをpngファイルなどで保存することができる。
Matplotlibのコードには2種類あり、MATLABのように書くスタイルとオブジェクト指向に則ったスタイルがあるM
問8
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
サービス利用料金ごとの人数をヒストグラムで表示するためのコードとして正しいものを選べ
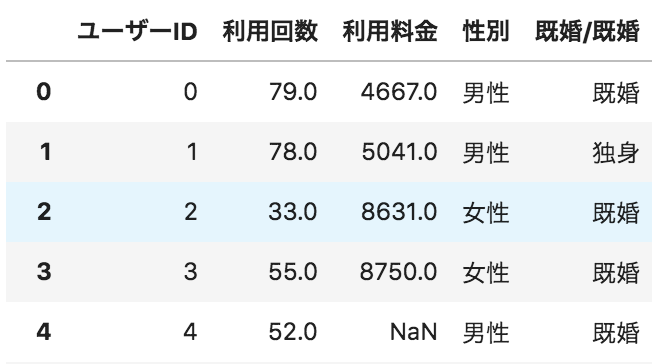
import matplotlib.pyplot as plt
df["利用料金"].hist()
plt.show()
①
import matplotlib.pyplot as plt
df["利用料金"].boxplot()
plt.show()
②
import matplotlib.pyplot as plt
df["利用料金"].value_counts().hist()
plt.show()
③
import matplotlib.pyplot as plt
plt.bar(df["利用回数"], df["ユーザーID"])
plt.show()
④
①
②
③
④
問9
以下のコードを実行した場合のBとCに格納されているデータの組み合わせとして、正しいものを選べ。選択肢は(B, C)の順に記載されている。
import numpy as np
A = np.eye(3)
B = np.count_nonzero(A)
C = np.sum(A)
(array([3]), array([3]))
(3, 3)
(True, 6)
(True, 3)
問10
以下のコードを実行した際の出力として正しいものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = np.array([100,100,100])
np.vstack([a,b])
array([[ 0, 1, 10], [ 0, 1, 10], [100, 100, 100]])
array([0, 1, 10, 0, 1, 10, 100, 100, 100])
array([[ 0, 1, 10, 100], [ 0, 1, 10, 100], [100, 100, 100]])
array([[ 0, 1, 10, 100], [ 0, 1, 10, 100]])
問11
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.eye(4)
first, second = np.vsplit(A, [3])
second.T
array([[0., 0., 0., 1.]])
array([[0., 0., 1., 0.], [0., 0., 0., 1.]])
array([[0., 0.], [0., 0.], [1., 0.], [0., 1.]])
array([[0.], [0.], [0.], [1.]])
問12
A = (1,2,3) B = (4,5,6)の2つの座標がある。座標AB間のユークリッド距離として正しいものを選べ
27
9
3
問13
以下の文章のうちOne-hotエンコーディングの説明として正しいものを選べ
各カテゴリーラベルごとのカラムが新たに生成されるため、特徴量の数は増える
各カテゴリーを1,2,3…と数値に変換する処理である
カラムごとに0~1の範囲に収まるようにデータを変換する処理である
各カテゴリーを列として展開し、該当する値の列は1、それ以外の列は-1が入力される
問14
以下は、サポートベクターマシンを使用するためscikit-learnのサポートベクターマシンモジュールを使用する場合のコードである
svm.SVC(kernel='rbf', gamma=0.7, C=0.1)
線形分類問題を解く場合に変更するパラメーターとその変更方法を述べている文章のうち、正しいものを選べ
kernelを”linear”に変更する
kernelを”sigmoid”に変更する
C を1以上にする
gammaを1以上にする
問15
データエンジニアの業務について説明している以下の文章のうち、間違っているものを選べ
集計ミスがないかの確認をする
データサイエンティストや顧客とコミュニケーションを取る
データベース言語を用いてデータの抽出を行う
機械学習のアルゴリズムを深い領域で理解する
問16
データサイエンティストの役割について説明している以下の文章のうち、正しいものを選べ
技術の進歩が速い分野なので、論文などを読んで最新技術をキャッチアップする必要がある
Pythonで実装できるモデルを扱うことが多く、R言語を知っておく必要はない
業務中に自分でPCを修理する場合もあるので、コンピューターの内部構造や動作原理などを知っておく必要がある
データ分析さえできればよく、顧客の立場になり、その分析結果をどう使えるかまでを考えて分析する必要はない
問17
サポートベクターマシンについて説明している以下の文章のうち正しいものを選べ
scikit-learnで使用する場合、カーネルはガウスカーネル以外にも指定することができる
内部で欠損値を処理するアルゴリズムが実装されているため、欠損値はNULL値のままでよい
線形分離可能な問題にのみ適用できる
マージンの距離を最小にするように最適化するアルゴリズムである
問18
以下のような日付ごとの利用回数と利用料金が格納されたpandasデータフレームdfがある。このデータフレームdfの中から利用回数が最大のレコードを抽出するコードとして正しいものを選べ
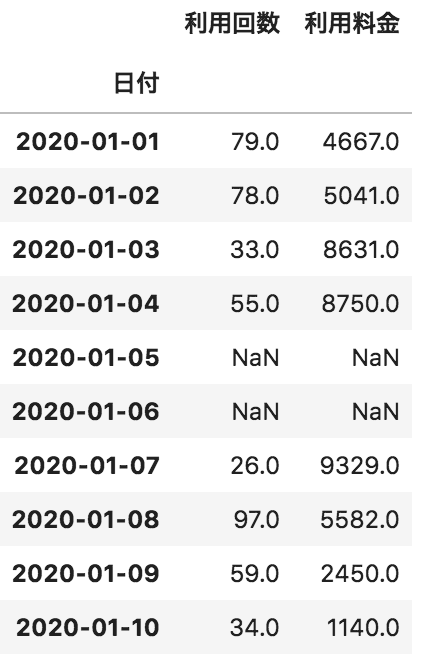
df[df[“利用回数”].max()]
df[df[“利用回数”]==df[“利用回数”].min()]
df[“利用回数”].max()
df[df[“利用回数”]==df[“利用回数”].max()]
問19
matplotlibでテキストをグラフ内に描画するメソッドについて説明している以下の文章のうち間違っているものを選べ
add_text()メソッドを用いる
メソッドの引数でグラフ内のどの位置に表示するかを座標で指定することができる
メソッドの引数で描画するテキストのサイズを指定することができる
text()メソッドを使用する
問20
決定木について説明している以下の文章のうち、正しいものを選べ
情報利得の大きい順に特徴量が使用され、木が作られる
木が下に行けば行くほど、特徴量の情報利得は大きい
各葉においてデータを分割する際の閾値はあらかじめモデル作成者が決める必要がある
欠損値は除外するか、何かしらの値で埋めておく必要がある
問21
pandasデータフレームdfをNumPy配列に変換する処理として正しいものを選べ
np.convert(df)
df.values
np.ndarray(df)
df.array
問22
import pandas as pd
df = pd.DataFrame({"国名":["日本","アメリカ","中国","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"面積":[380000, 9834000, 959700, 301300, 643800, 17100000, 8516000, 242500],
"人口/万人":[12700, 32800, 139300, 6000, 6700, 14500, 20900, 6600]})
上記コードを実行すると、以下のようなデータフレームが作成される。このデータフレームから中国のみのデータフレームを抜き出す処理として正しいものを選べ
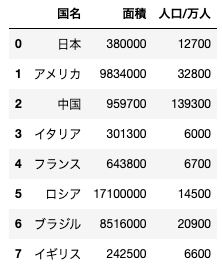
df.sort_values(“人口/万人”, ascending=True).iloc[-1,:]
df[df[“国名”]!=”中国”]
df[df.index==2]
df[“国名”]==”中国”
問23
loggingモジュールには、5種類のログレベル(重要度)でログを出力するためのメソッドが用意されています。重要度の高い順にメソッドを並び替えたものとして、正しいものを選べ。
critical()→error()→info()→debug()→warning()
debug()→critical()→error()→warning()→info()
critical()→error()→warning()→info()→debug()
critical()→error()→warning()→debug()→info()
問24
以下のコードを実行した際に、Aについて述べているものとして、間違っているものを選べ
import numpy as np
A = np.random.rand(10,1)
Aの配列の形状は(10,1)である。
Aに格納されている値は全て、標準正規分布に従う乱数である。
中心が10、標準偏差が1に従う正規分布から生成された乱数が格納されている
Aに格納されている値は0以上1未満の浮動小数点数である。
問25
以下のようなデータフレームdfがある。このデータフレームから、A列とB列の値が3000のデータフレームを抽出するコードとして正しいものを選べ。
import pandas as pd
df = pd.DataFrame({"A":[10,200,3000,40000],
"B":[1000,2000,3000,4000]})
df[(df[“A”]==3000)or(df[“B”]==3000)]
df[([“A”]==3000)&([“B”]==3000)]
df[(df[“A”]==3000)&(df[“B”]==3000)]
df[df[“A”, “B”]==3000]
問26
階層的クラスタリングの結果の解釈に用いられる樹形図の説明として正しいものを選べ
データ数が多いと表示が困難であるため、一部だけ取り出して可視化するなどの工夫が必要である
樹形図の縦軸はクラスター内誤差平方和(SSE)である
次元削減をして特徴量を2変数にしてから、可視化しなければならない
最短距離法を用いた場合には、樹形図による可視化はできない
問27
データエンジニアの役割について説明している以下の文章のうち、正しいものを選べ
データエンジニアはモデリングのみを担当することが多く、データの概要把握のためのデータ集計やデータ可視化を行うことはない。
データエンジニアが使用するツールはwindowsOSでしか動作しないものが多く、windowsOSを使わなければならない
データエンジニアはデータサイエンティストと連携して、予測モデルを構築するためのデータの前処理や抽出作業を行うことがある
データエンジニアはモデリングのみを担当することが多く、データの前処理を行うことはない
問28
set型のデータに関して説明している以下の文章のうち、正しいものを選べ
標準のデータ型にはなく、使う場合はモジュールをインポートする必要がある
重複しない要素を含み、集合演算をする場合に用いられる
イミュータブルなデータ型であり、要素の追加や削除はできない
データの各要素が、keyとvalueという2組みのデータから成り立ち、それぞれ取り出すことができる
問29
テストデータを用いてパラメーターチューニングをしてはいけない理由として正しいものを選べ
実際には手に入り得ないデータであり、未来の情報をみてモデルの精度を恣意的に向上させていることになるから
テストデータは学習データよりもデータ数が多いので、チューニングに時間がかかるから
テストデータは学習データとデータの分布が異なるから
学習データとテストデータでは特徴量が異なるから
問30
以下のコードを実行した場合にBに格納されているものとして正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.ravel()
A[0,:]=0
array([1, 2, 3, 4, 5, 6])
array([0, 2, 3, 0, 5, 6])
array([[1, 2, 3, 4, 5, 6]])
array([0, 0, 0, 4, 5, 6])
問31
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームにその日の株価の増減値(終値-始値)に応じて、ランクを付与するコードの実装として正しいものを選べ
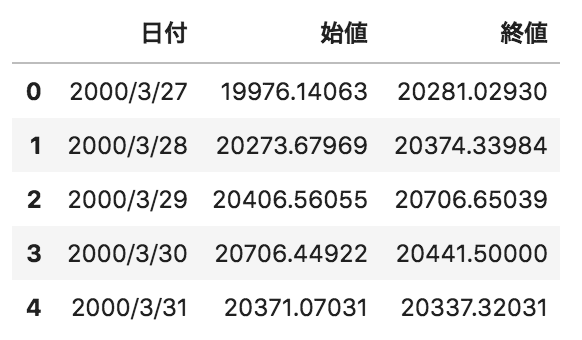
①
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df["増減値"].apply(add_rank)
②
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df.add_rank(df["増減値"])
③
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply(add_rank(df["終値"] - df["始値"]))
④
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply().add_rank(df["終値"] - df["始値"])
①
②
③
④
問32
モデルの評価指標について説明している以下の文章のうち、正しいものを選べ
適合率と再現率にはトレードオフの関係がある
分類問題の際に使用する評価指標は精度(accuracy)のみである
回帰問題の評価指標にはF値を算出することが多い
scikit-learnには適合率、再現率、F値を算出するためのモジュールが存在しなく、自分で混同行列から算出する必要がある
問33
matplotlibのhist()メソッドの返り値として取得できる情報として正しいものを選べ
(各ビンの度数、各ビンの範囲、パッチオブジェクトが格納されている配列)の3つの返り値を持つ
各ビンの範囲と各ビンの度数が格納されているディクショナリとして1つの返り値を持つ
(各ビンの度数、各ビンの範囲)の2つの返り値を持つ
(各ビンの度数、各ビンの範囲, 最頻値)の3つの返り値を持つ
問34
以下の関数f(x, y)のxに関する偏微分として正しいものを選べ
問35
モデルが選択した行動に対してどの程度よかったかを評価するために「価値」という概念を導入した、自律的に最適な行動選択を学習する枠組みをなんと呼ぶか
強化学習
教師なし学習
半教師あり学習
GAN(Generative Adversarial Network)
問36
以下の文章のうち次元削減手法として適切でないものを選べ
k-means法
主成分分析(PCA)
線形判別分析(LDA)
t-SNE
問37
以下のような出力をするコードとして正しいものを選べ
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08',
'2020-01-09', '2020-01-10', '2020-01-11', '2020-01-12',
'2020-01-13', '2020-01-14', '2020-01-15', '2020-01-16',
'2020-01-17', '2020-01-18', '2020-01-19', '2020-01-20',
'2020-01-21', '2020-01-22', '2020-01-23', '2020-01-24',
'2020-01-25', '2020-01-26', '2020-01-27', '2020-01-28',
'2020-01-29', '2020-01-30', '2020-01-31'],
dtype='datetime64[ns]', freq='D')
pd.date(start=”2020-01-01”, end=”2020-1-31”)
pd.date_range(start=”2020-01-01”, end=”2020-1-31”)
pd.date_range([“2020-01-01”, “2020-1-31”])
pd.range(start=”2020-01-01”, end=”2020-1-31”)
問38
pipを用いてXXXXというパッケージをアンインストールする場合に使用するコマンドとして正しいものを選べ
pip remove XXXX
pip uninstall XXXX
pip detach XXXX
pip demount XXXX
問39
A = (1,2,3) B = (4,5,6)の2つの座標がある。座標AB間のマンハッタン距離として正しいものを選べ
9
3
27
問40
s = ‘DIVE INTO CODE’ という文字列が格納された変数に対する処理の説明として間違っているものを選べ
s.lower()を実行すると、”dive into code”という文字列が返ってくる
s.split()を実行すると、[‘DIVE’, ‘INTO’, ‘CODE’]というリストが返ってくる
s.strip()を実行すると、”DIVEINTOCODE”という文字列が返ってくる
s.replace(‘CODE’, ‘Python’)を実行すると、’DIVE INTO Python’という文字列が返ってくる