| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
pandasのデータフレームの上から5行目までを表示させるメソッドとして、正しいものを選べ。
tail()
head()
view()
show()
解説
pandas のデータフレームの上から5行目までを表示させるメソッドは head() メソッドです。ちなみに末尾5行目を表示させるのは tail() メソッドです。
問2
Pythonについて説明している以下の文章のうち間違っているものを選べ
Pythonで変数を使用する際には、必ず変数の型を最初に定義する必要がある
Pythonはオブジェクト指向のプログラミング言語である
機械学習ライブラリにscikit-learnがある
Pythonの予約語の数は他のプログラミング言語と比較して少ない
解説
変数に格納するオブジェクトの型定義をしなくても変数の定義が可能なので、必ず変数の型を最初に定義する必要があるとは言えません。
最新のPython3.10では、変数を定義する際には型の定義をする型の絞り込み機能が追加されました。
これによりライブラリの追加などをせず、変数定義の際に型の指定ができるようになりました。
問3
以下のグラフは各ユーザーの支払い請求額をx軸、チップをy軸とした散布図である。この散布図の説明として正しいものを選べ
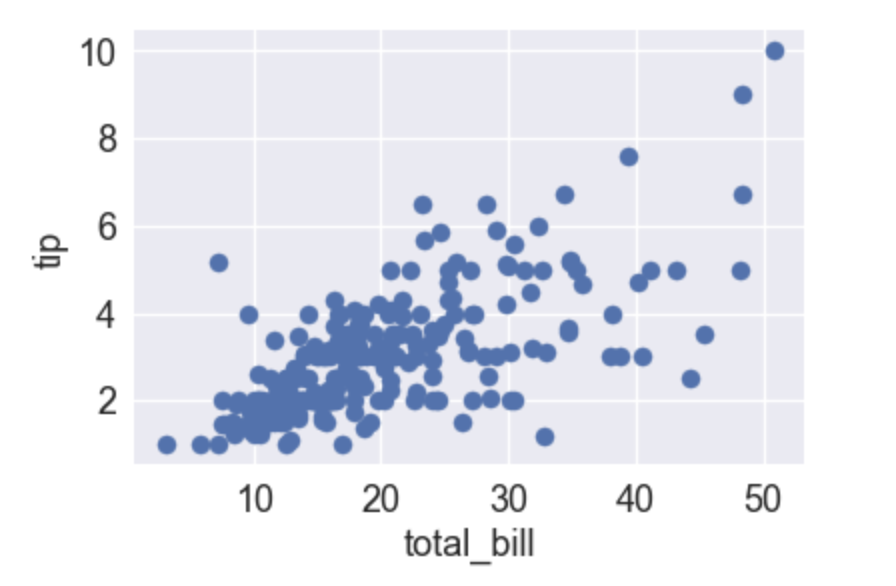
支払い請求額は30~40が最も多いことがわかる
チップが10付近の所に1つデータがあるが、これは外れ値である
支払い請求額とチップには概ね負の相関がある
支払い請求額とチップには概ね正の相関がある
解説
データ分析の知識を問われてる問題です。相関という言葉は、2つのデータについて片方の変化がもう片方に影響を与える関係がある場合に相関がある、という言い方をします。この場合、片方が上がれば片方も上がるので生の相関がある、という言い方が出来ます。
問4
交差検証の欠点として、各検証における予測ラベルの割合が不均一になる問題がある。この問題を解決する場合に使用される交差検証の名称として正しいものを選べ
層化k分割交差検証
均一k分割交差検証
ブートストラップ法
Leave-One-Out法
問5
Pythonのコーディング規約の名称として正しいものを選べ
Coding8
PEP8
PIP8
Flake8
解説
Pythonには共通のコーディング規約があります。名前はPEP8(ペップエイト)です。
出典元 「pep8-ja」(2021年12月23日11時00分 UTC版) 『はじめに — pep8-ja 1.0 ドキュメント』
問6
scikit-learnのmetricsモジュールのclassification_report関数で出力されないものとして正しいものを選べ
AUC
適合率
再現率
F値
問7
機械学習モデルの精度改善をする場合の措置として間違っているものを選べ
評価指標を変更する
学習データ量を増やす
ハイパーパラメーターのチューニング
特徴量の選定
問8
6面体のサイコロをふったとき、偶数の目が出る確率として正しいものを選べ。
0.5
1/6
1
1/3
解説
6面体のサイコロを振った時に出るパターンは6通りです。偶数が出るのは3通りです。確率は、期待する事象/全体の事象 で求まります。 つまり3/6→1/2→0.5が正解です。
問9
dfと名付けられている、以下のようなデータフレームがある。このデータフレームから、人口/万人カラムを削除する場合のコードとして正しいものを選べ
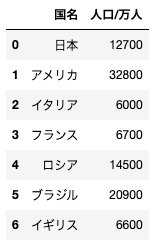
df.drop(“人口/万人”, axis=1)
df.drop(“人口/万人”, axis=0)
df.drop[“人口/万人”]
df[“人口/万人”].drop()
問10
import pandas as pd
df = pd.DataFrame({"国名":["日本","アメリカ","中国","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"面積":[380000, 9834000, 959700, 301300, 643800, 17100000, 8516000, 242500]})
上記コードを実行した後に、以下の写真の出力を得るために実行するべきコードを選べ
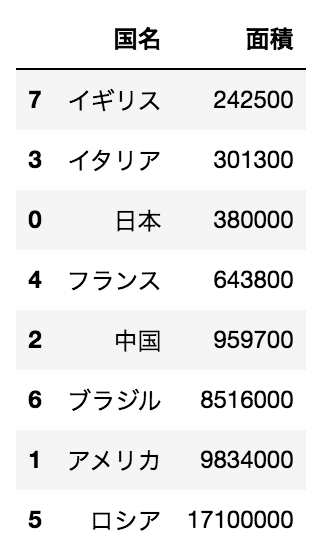
df[“面積”].sort_values()
df.sort_values(“面積”, ascending=False)
df.sort_values(“面積”)
df[“面積”].sort_values(ascending=False)
問11
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
性別ごとの人数を棒グラフで表示するためのコードとして正しいものを選べ
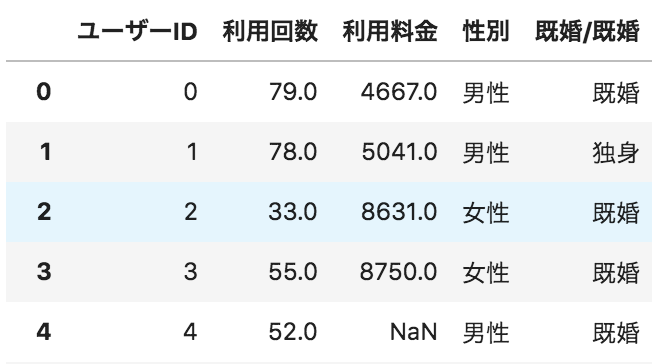
import matplotlib.pyplot as plt
df["性別"].value_counts().plot.bar()
plt.show()
①
import matplotlib.pyplot as plt
df["性別"].plot.bar()
plt.show()
②
import matplotlib.pyplot as plt
plt.bar(df["性別"].value_counts())
plt.show()
③
import matplotlib.pyplot as plt
df["性別"].value_counts().bar()
plt.show()
④
①
②
③
④
解説
value_countsメソッドを使うことで指定したカラムの要素の合計が取得できます。
その結果に対してplot.bar()を実行すると期待するグラフを作成できます。
1 2 3 4 5 |
df["性別"].value_counts() # 結果 # 男性 3 # 女性 2 # Name: 性別, dtype: int64 |
また df["性別"].plot.bar()のように実行してしまうとエラーが発生しTypeError: no numeric data to plot Numericなデータを期待していることがわかります。
問12
以下のコードのXXXXの部分に当てはまるものとして正しいものを選べ
try:
with open('sample.txt', encoding='utf-8') as f:
txt = f.read()
f.close()
print(txt)
XXXX FileNotFoundError as err:
print("ファイルが存在しないため、読み込めませんでした。")
XXXX Exception as other:
print("ファイルが読み込めませんでした。")
exception
exceptional
except
reject
解説
try文ではexceptが使われます。
問13
以下のような日付、日経平均の株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームのカラムの型を確認するためのメソッドとして正しいものを選べ
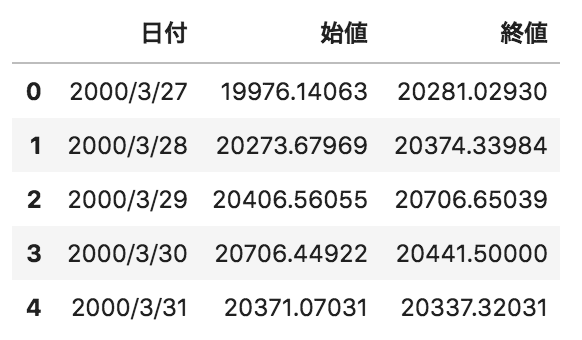
df.dtype
df.dtypes
df.columns
type(df)
解説
データフレームのカラムの型を確認するのは dtypes を使います。 dtype と紛らわしいですが、データフレームは複数のカラムを持つ場合があると考えると単体では無く複数系の dtypesを用いると理解出来ます。
問14
線形回帰の損失関数に対して、Ridge回帰とLasso回帰が追加している正則化項の組み合わせとして正しいものを選べ
(Ridge回帰, Lasso回帰)= (L2正則化項, L1正則化項)
(Ridge回帰, Lasso回帰)= (L1正則化項, L2正則化項)
(Ridge回帰, Lasso回帰)= (L1正則化項, L3正則化項)
(Ridge回帰, Lasso回帰)= (L3正則化項, L1正則化項)
解説
正則化項にはL1正則化(Lasso正則化)とL2正則化(Ridge正則化)というものがあります。
問15
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.linspace(0, 2, 5)
B = np.diff(A)*2
B == np.ones(4)
True
array([ 1, 1, 1, 1])
array([ True, True, True, True])
FALSE
問16
以下のグラフは、木曜日から日曜日のユーザーの支払い請求額に関する分布を示した箱ひげ図である。この箱ひげ図の説明として正しくないものを選べ
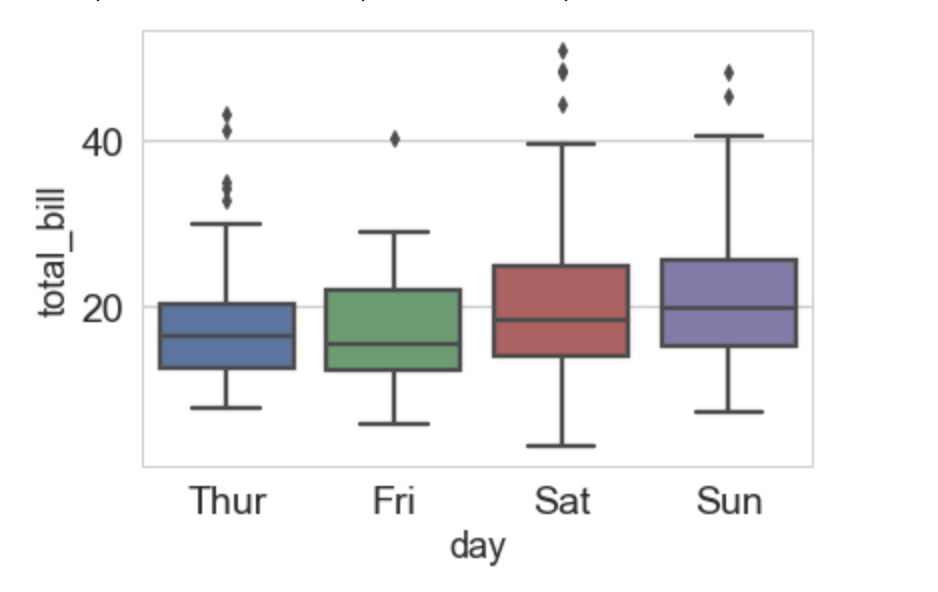
平均値は、日曜日がもっとも高い
第一四分位数がもっとも大きいのは、金曜日である
支払い請求額は土曜日がもっともばらついている
支払い請求額が最大のユーザーは、土曜日の利用である
解説
箱ひげ図の特徴の理解度の問題です。箱ひげ図はデータの四分位単位を表現出来ます。ここでは総数の25%に当たる値が第1四分位数がもっとも大きいのは金曜日(Fri)というのが間違いです。第1四分位数は箱の一番したの位置の値です。ここで一番大きい第1四分位数は日曜日(Sun)になります。
問17
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
横軸に利用回数、縦軸に利用料金の散布図を描画するためのコードとして正しいものを選べ
①
import matplotlib.pyplot as plt
plt.scatter(df["利用回数"],df["利用料金"])
plt.show()
②
import matplotlib.pyplot as plt
plt.scatter(df["利用料金"],df["利用回数"])
plt.show()
③
import matplotlib.pyplot as plt
plt.plot(df["利用回数"],df["利用料金"])
plt.show()
④
import matplotlib.pyplot as plt
df["利用回数"].scatter(df["利用料金"])
plt.show()
①
②
③
④
解説
第一引数にx軸, 第二引数にy軸にあたるものをセットします。
問18
クラスタリング手法として適切でないものを以下の中から選べ
k-近傍法
k-means法
ウォード法
単純連結法
解説
k-近傍法は教師あり学習の分類と考えられるの適切ではありません。
問19
以下のコードを実行した場合に出力されるグラフとして正しいものを選べ。
fig, ax = plt.subplots()
x = [1,2,3]
y1 = [10, 20, 30]
y2 = [30, 20, 10]
ax.bar(x, y1)
ax.bar(x, y2, bottom=y1)
plt.show()
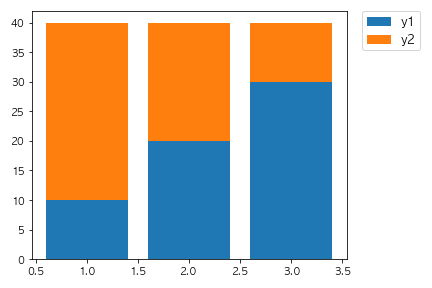
①
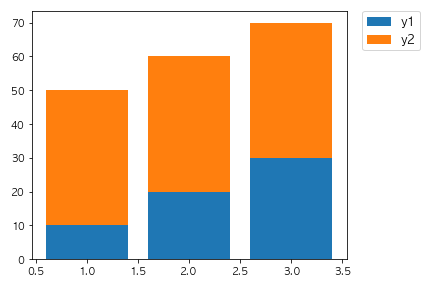
②
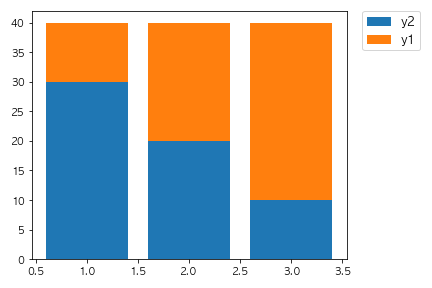
③
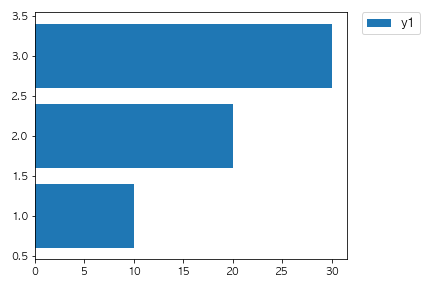
④
①
②
③
④
解説
bottom=y1でベースとなるデータを指定しています。
2回目のax.barの引数で設定されていることからy2はy1の上に積み上げることができます。
数値を変えたりbottomの対象を変えたりして挙動を確認してみましょう。
問20
以下のコードの出力として正しいものを選べ
import pandas as pd
df = pd.DataFrame({"A":[1,2,3,4,5], "B":[6,7,8,9,10]})
df.iloc[1]>3
A False
B True
①
0 True
1 True
2 True
3 True
4 True
②
A False
③
0 False
1 False
2 False
3 True
4 True
④
①
②
③
④
解説
pandasのilocメソッドの問題です。ilocは行と列を数値で指定出来ます。df.iloc[1]は1次元目の1行目にアクセスします。
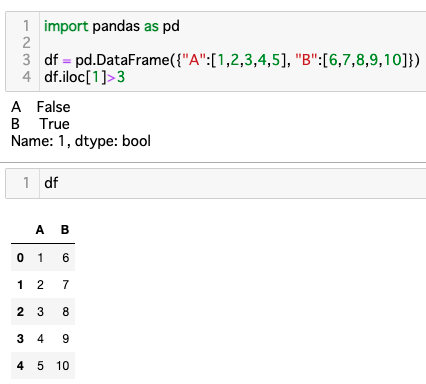
問21
以下のコードを実行した場合にxxに格納されるデータとして正しいものを選べ。
import numpy as np
m = np.arange(4)
n = np.arange(4)
xx, yy = np.meshgrid(m,n)
array([[0, 1, 2, 3], [0, 1, 2, 3], [0, 1, 2, 3], [0, 1, 2, 3]])
array([[0, 1, 2, 3], [0, 1, 2, 3]])
array([0, 1, 2, 3])
array([0, 1, 4, 9])
問22
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.ravel()
A[0,:]=0
B.reshape(3,2)
array([[1, 2, 3], [4, 5, 6]])
array([[0, 2], [3, 0], [5, 6]])
array([[0, 0], [0, 4], [5, 6]])
array([[1, 2], [3, 4], [5, 6]])
問23
datetimeモジュールについて説明している以下の文章のうち、誤っているものを選べ
取得する日付や日時のタイムゾーンを指定することができる
now()を使用することで、今日の日付を取得することができる
日数の差分を算出するなど、日付同士の演算をすることができない。
日時(datatime型)→文字列の変換はできるが、文字列→日時(datatime型)の変換はできない
解説
datetimeモジュールは取得する日付や日時のタイムゾーンを指定は出来ません。
datetimeモジュールに含まれるdatetimeクラスには日付や日時のタイムゾーンを指定できます。
1 2 3 4 5 6 |
from datetime import datetime # datetimeクラスをimport from datetime import timezone # timezoneクラスをimport datetime(2021, 1, 1, tzinfo=timezone.utc) # datetime.datetime(2021, 1, 1, 0, 0, tzinfo=datetime.timezone.utc) |
問24
matplotlibのhist()メソッドの引数に関する説明として間違っているものを選べ
最適なビンの数を決める手法を指定することができる
ビンの数を変更することができる
積み上げヒストグラムを描画することができる
相対度数分布を表示することができる
問25
以下の説明のうち、最頻値の説明として正しいものを選べ。
データの中でもっとも大きい値のこと。
データを小さい順に並べて、ちょうど真ん中にくる値である。データの個数が偶数と奇数の場合で算出方法が異なる
もっとも多く出現するデータ・値であり、アンケートなどの最多回答者などがこれに相当する。
データ全体がどの程度ばらついているかを示す値。
解説
最頻値の説明は漢字からも判断出来ますが、もっとも頻繁に出現するといった説明が正解です。
問26
以下のコードを実行すると、写真のようなグラフが描画される
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list)
plt.show()
グラフの線の色を赤色に変更したい場合のコードとして、正しいものを選べ
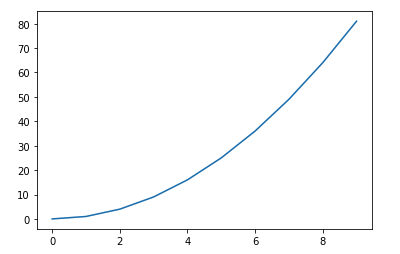
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list, color = "red")
plt.show()
①
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list)
plt.show(color = "red")
②
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list, ls="--")
plt.show()
③
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list, style="red")
plt.show()
④
①
②
③
④
解説
matplotlibのパラメータの問題です。グラフの線を赤くする場合はplotメソッドのcolorパラメータを使い、red (赤)を指定します。
問27
以下のコードを実行した際に、Aについて述べているものとして、間違っているものを選べ
import numpy as np
A = np.random.rand(10,1)
Aの配列の形状は(10,1)である。
Aに格納されている値は全て、標準正規分布に従う乱数である。
中心が10、標準偏差が1に従う正規分布から生成された乱数が格納されている
Aに格納されている値は0以上1未満の浮動小数点数である。
問28
以下の文章のうちグリッドサーチの説明として正しいものを選べ
指定したパラメーターの全ての組み合わせを試す手法。組み合わせの総数分モデルの学習を行うので、探索が終わるのに時間がかかる
各パラメーターにおいて指定した分布から無作為に探索値を抽出するので、分布の仮定が間違っていると最適なチューニング結果にならない
パラメーター探索の仮定で、ベイズ推論を行なっているため計算に時間がかかる
どのパラメーターを探索するかはアルゴリズムが自動で選んでくれる
問29
以下のグラフのxに関して微分した際の値として正しいものを選べ。グラフのCは任意定数を意味する

発散
0
1
解説
Cは任意の定数をとるため微分をすると0になります。
問30
venvやAnacondaで作成した仮想環境から抜ける際に使用するコマンドとして正しいものを選べ
exit
deactivate
quit
escape
解説
venvやAnacondaで作成した仮想環境から抜ける際に使用するコマンドは deactivate です。
出典元 「venv — 仮想環境の作成」(2021年12月23日14時00分 UTC版) 『venv — 仮想環境の作成 — Python 3.10.0b2 ドキュメント』
問31
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 1],[1, 1]])
B = np.array([1, 1])
np.dot(A, B)
array([[1, 1], [1, 1]])
array([[2, 2]])
array([2, 2])
実行不可(エラーが出る)
問32
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[0, 1, 2, 3, 4]])
B = np.full((1, 5), 2)
np.sum(A>=B)
3
10
9
4
問33
以下の配列の形状として正しいものを選べ。
array([[1,2,3], [4,5,6]])
(3, 2)
(1, 6)
(3, 3)
(2, 3)
解説
配列の問題です。2行3列が正解です。
問34
以下のようなデータがある。このようなデータ型をなんと呼ぶか、正しいものを選べ
{“数学”: 95, “国語”: 65, “英語”: 75}
リスト
タプル
真偽値(ブーリアン)
辞書(ディクショナリ)
解説
辞書は キー(key): 値(value) のペアの集合であり、キーが (辞書の中で)一意でなければならない、と考えるとよいでしょう。
出典元 「辞書型 (dictionary)」(2021年12月23日11時00分 UTC版) 『5. データ構造 — Python 3.10.0b2 ドキュメント』
問35
scikit-learnで実装されているk-means法について説明している以下の文章のうち間違っているものを選べ
クラスターの重心位置の更新計算は、指定した回数分だけ行われる
教師なし学習であるため、教師ラベルは必要ない
initの引数に”random”を指定すると、最初のクラスター点をデータの中からランダムに選ぶため、初期値依存性がある
クラスターの個数は、使用者が指定する必要がある
問36
ROC曲線の横軸と縦軸が意味するものとして正しい組み合わせを以下の中から選べ
(横軸, 縦軸)= (偽陽性率, 真陽性率)
(横軸, 縦軸)= (真陽性率, 偽陽性率)
(横軸, 縦軸)= (適合率, 再現率)
(横軸, 縦軸)= (再現率, 適合率)
問37
matplitlibのpieメソッドを用いて円グラフを影をつけて表示させる場合の、pieメソッド内で指定する引数として正しいものを選べ
shadow=True
counterclock=True
explode=True
frame=True
解説
引数shadowにTrueをセットすることで影をつけれます。defaultではFalseが設定されています。
問38
機械学習モデルについて説明している以下の文章のうち間違っているものを選べ
機械学習モデルでは、何かを分類するタスクしか解くことができない
ラベルではなく数値そのものを予測する問題を回帰問題という
データが大量に存在する場合にモデルを構築する際は、学習データ、検証データ、テストデータの3つに分割するのが理想である
異なる検証データで結果を比較するために、交差検証を実施することもある
問39
scikit-learnのDesicionTreeClassifierモジュールを使用する場合に引数として指定できないものを選べ
木の数
木の深さ
葉の数
不純度の指標
問40
データエンジニアの業務について説明している以下の文章のうち、間違っているものを選べ
集計ミスがないかの確認をする
データサイエンティストや顧客とコミュニケーションを取る
データベース言語を用いてデータの抽出を行う
機械学習のアルゴリズムを深い領域で理解する
解説
データエンジニアはデータ分析がしやすいようにデータを加工したり、企業の希望に合うようにデータを整頓する業務を担います。機械学習のアルゴリズムを理解し精度を上げる等の業務は機械学習エンジニアが担います。