scikit-learnのDesicionTreeClassifierモジュールを使用する場合に引数として指定できないものを選べ
木の数
木の深さ
葉の数
不純度の指標
解説
一つの木から枝をはやしていくので木の数は設定できません。
以下は、サポートベクターマシンを使用するためscikit-learnのサポートベクターマシンモジュールを使用する場合のコードである
svm.SVC(kernel='rbf', gamma=0.7, C=0.1)
線形分類問題を解く場合に変更するパラメーターとその変更方法を述べている文章のうち、正しいものを選べ
kernelを”linear”に変更する
kernelを”sigmoid”に変更する
C を1以上にする
gammaを1以上にする
以下のようなグラフを描画するために、コードのXXX の部分に記述されるコードとして正しいものを選べ
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({"国名":["日本","アメリカ","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"人口/万人":[12700, 32800, 6000, 6700, 14500, 20900, 6600]})
plt.rcParams["font.family"] = "AppleGothic"
XXX
plt.xlabel("人口(万人)")
plt.show()
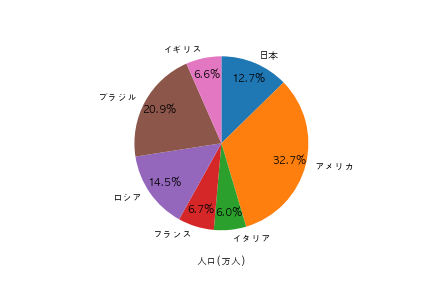
plt.pie(df["人口/万人"], labels=df["国名"], counterclock=False, startangle=90, autopct="%1.1f%%", pctdistance=0.8)
①
plt.pie(df["人口/万人"], labels=df["国名"], autopct="%1.2f%%", pctdistance=0.8)
②
plt.pie(df["人口/万人"], autopct="%1.2f%%", pctdistance=0.8)
③
plt.pie(df["人口/万人"], labels=df["国名"], counterclock=False, startangle=90, autopct="%1.1f%%", pctdistance=1.2)
④
①
②
③
④
以下のような配列AとBは行列の次元は異なるが、A*Bなどの演算を行うことが可能である。このような異なる次元のデータの演算を可能にする機能の名称として正しいものを選べ。
A = np.array([[1, 2],[2, 1]])
B = np.array([6, 8])
ユニバーサルファンクション
ブロードキャスト
ジェネレーター
マジックキャスト
決定木の不純度の指標として使用される「ジニ不純度」の説明している以下の文章のXXXとYYYに当てはまる組みとして正しいものを選べ
ある2つのカテゴリー(ラベル0とラベル1)を持つ特徴量を分割する場合のジニ不純度は、ラベル0なのにラベル1と割り振られる確率とラベル1なのにラベル0と割り振られる確率のXXXを考える必要がある。クラス0である確率をP(0)、クラス1である確率をP(1)とすると、求めるジニ不純度は
となる
XXX = 和, YYY = 2
XXX = 積, YYY = 2
XXX = 積, YYY = 1/2
XXX = 和, YYY = 1/2
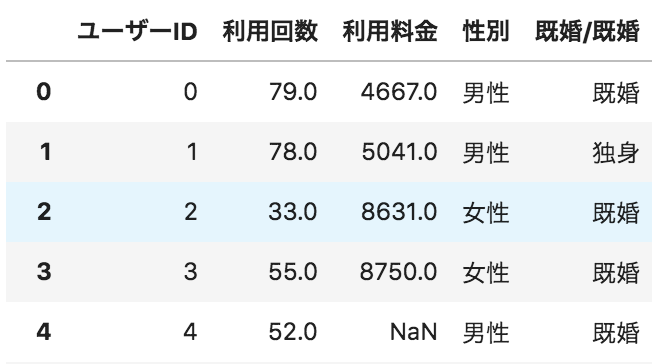
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
サービス利用料金ごとの人数をヒストグラムで表示するためのコードとして正しいものを選べ
import matplotlib.pyplot as plt
df["利用料金"].hist()
plt.show()
①
import matplotlib.pyplot as plt
df["利用料金"].boxplot()
plt.show()
②
import matplotlib.pyplot as plt
df["利用料金"].value_counts().hist()
plt.show()
③
import matplotlib.pyplot as plt
plt.bar(df["利用回数"], df["ユーザーID"])
plt.show()
④
①
②
③
④
解説
dfで指定した列に対してhistメソッドを実行すると指定したデータのヒストグラムを作成します。
さらにdf["利用料金"].hist(by=df["性別"])のようにbyでdfを指定すると指定したdfのサブプロットを作成します。
今回のケースだと性別ごとの利用料金のヒストグラムが作成されます。
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
pickleモジュールの説明として正しいものを選べ
正規表現を扱うためのモジュールである
オブジェクトをpklファイルとして保存するために使用するモジュールで、構築した予測モデルを保存する場合などに使用される
画像データを扱う場合のモジュールで、ファイルを読み込むことはできるが、オブジェクトを保存することはできない
Pythonオブジェクトをpickle化するには、pickle.save(オブジェクト名)と実行する
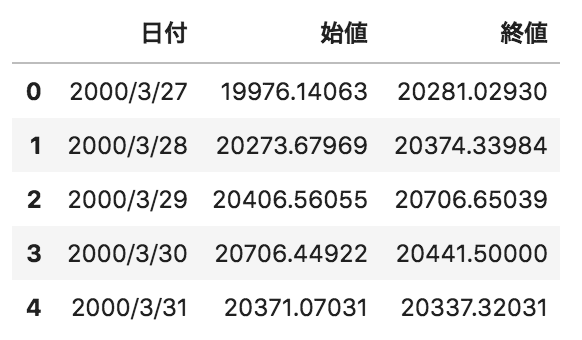
以下のようなpandasデータフレームdfがある。日付カラムをこのデータフレームのインデックスにする場合のコードとして正しいものを選べ
df[“日付”].set_index()
df.reset_index(“日付”)
df.set_index(“日付”)
df.index(“日付”)
データフレームを抜き出す処理
import pandas as pd
df = pd.DataFrame({"国名":["日本","アメリカ","中国","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"面積":[380000, 9834000, 959700, 301300, 643800, 17100000, 8516000, 242500],
"人口/万人":[12700, 32800, 139300, 6000, 6700, 14500, 20900, 6600]})
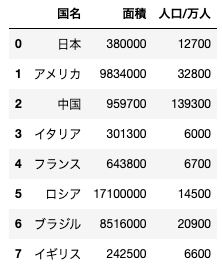
上記コードを実行すると、以下のようなデータフレームが作成される。このデータフレームから中国のみのデータフレームを抜き出す処理として正しいものを選べ
df.sort_values(“人口/万人”, ascending=True).iloc[-1,:]
df[df[“国名”]!=”中国”]
df[df.index==2]
df[“国名”]==”中国”
欠損値の対処方法として、間違っているものを選べ
One-hotエンコーディングを行う
その特徴量の統計的な代表値などで埋める
欠損値があるデータを用いない
欠損がある場合でも動作する機械学習アルゴリズムを選定する
以下のコードを実行した際の出力として正しいものを選べ
A = [1]*10
A
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]
[10]
[[1],[1],[1],[1],[1],[1],[1],[1],[1],[1]]
[[10],[10],[10],[10],[10],[10],[10],[10],[10],[10]]
matplotlibについて説明している以下の文章のうち、間違っているものを選べ
plotメソッドではedgecolor引数を指定することで、グラフの枠線の色を指定することができる
color引数では、文字列の他に、HTMLやCSS3で定義された色名を指定することができる
散布図で指定することができるマーカーの種類は30種以上ある
plot()メソッドでは線の太さを変更することはできない
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.eye(4)
first, second = np.hsplit(A, [2])
first
array([[1., 0.], [0., 1.], [0., 0.], [0., 0.]])
array([[1., 0., 0.], [0., 1., 0.], [0., 0., 1.], [0., 0., 0.]])
array([[1., 0., 0., 0.], [0., 1., 0., 0.], [0., 0., 1., 0.]])
array([[1., 0., 0., 0.], [0., 1., 0., 0.]])
解説
NumPyのメソッドの問題です。4行4列の単位行列を作成したあと、hsplitで0列~1列目までをfirstに入れます。4行2列のデータになり、選択肢が正解になります。
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[0, 1, 2, 3, 4]])
B = np.full((1, 5), 1)
A[A>=B]
array([1, 2, 3, 4])
array([False, True, True, True, True])
array([[1, 2, 3, 4]])
array([[False, True, True, True, True]])
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.linspace(0, 2, 5)
B = np.diff(A)*2
B == np.ones(4)
True
array([ 1, 1, 1, 1])
array([ True, True, True, True])
FALSE
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
scikit-learnで実装されているk-means法について説明している以下の文章のうち間違っているものを選べ
クラスターの重心位置の更新計算は、指定した回数分だけ行われる
教師なし学習であるため、教師ラベルは必要ない
initの引数に”random”を指定すると、最初のクラスター点をデータの中からランダムに選ぶため、初期値依存性がある
クラスターの個数は、使用者が指定する必要がある
以下のpandasデータフレームdfのDateカラムはオブジェクト型である。このDateカラムをdatetime型に変換するコードとして正しいものを以下の中から選べ
df[“Date”] = pd.datetime(df[“Date”])
df[“Date”] = pd.to_datetime(df[“Date”])
df[“Date”] = pd.to_date(df[“Date”])
df[“Date”] = df[“Date”].astype(datetime)
A+Bが計算できない組み合わせとして、正しいものを以下の中から選べ。
A = np.array([[0,1,2]]) B = np.ones((3,1))
A = np.array([[0,1,2]]) B = np.ones((3,2))
A = np.array([[0,1,2]]) B = np.ones((1,3))
A = np.array([[0,1,2]]) B = np.ones((2,3))
以下は、サポートベクターマシンを使用するためscikit-learnのサポートベクターマシンモジュールを使用する場合のコードである
svm.SVC(kernel='rbf', gamma=0.7, C=0.1)
線形分類問題を解く場合に変更するパラメーターとその変更方法を述べている文章のうち、正しいものを選べ
kernelを”linear”に変更する
kernelを”sigmoid”に変更する
C を1以上にする
gammaを1以上にする
以下の文章のうち次元削減手法として適切でないものを選べ
k-means法
主成分分析(PCA)
線形判別分析(LDA)
t-SNE
scikit-learnで学習した決定木を可視化する際に使用するライブラリとして正しいものを以下の中から選べ
pydotplus
seaborn
gnuplot
ggplot
解説
pydotplusモジュールのgraph_from_dot_data関数にscikit-learnで得た学習結果をセットするとこで可視化するために必要なグラフのオブジェクトが作成できます。
そのオブジェクトを画像や可視化ツールで表示します。
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
利用回数の箱ひげ図を描画するコードとして正しいものを選べ
import matplotlib.pyplot as plt
plt.boxplot(df["利用回数"])
plt.show()
①
import matplotlib.pyplot as plt
plt.hist(df["利用回数"])
plt.show()
②
import matplotlib.pyplot as plt
plt.violinplot(df["利用回数"])
plt.show()
③
import matplotlib.pyplot as plt
df["利用回数"].boxplot()
plt.show()
④
①
②
③
④
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
np.log(np.exp(np.eye(2)))
array([[ 0., -inf], [-inf, 0.]])
array([[2.71828183, 1. ], [1. , 2.71828183]])
array([[1., 0.], [0., 1.]])
array([[1., 1.], [1., 1.]])
カテゴリカル型やオブジェクト型のデータが格納されたpandasデータフレームに対して、describeメソッドを用いて算出することができない統計量として正しいものを選べ
ユニーク数
データ数
最頻(もっとも多く出現するデータ)のレコード数
最大文字数
解説
describeメソッドは各列ごとに平均、標準偏差、最大値、最小値、最頻値などの要約統計量を取得できます。データの概要を知る時に便利です。
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A[0,:]
A[0,:]=0
B
array([1, 2, 3])
array([0, 0, 0])
array([[1], [4]])
array([[0], [0]])
csvファイルをpandasで読み込む場合に、読み込むカラムを指定する方法として正しいものを選べ
※選択肢中の’data.csv’ は読み込む元データが格納されたcsvファイルとする
pd.read_csv(‘data.csv’, usecols=[カラム名])
pd.read_csv(‘data.csv’, index_col=[カラム名])
pd.read_csv(‘data.csv’, use_cols=[カラム名])
pd.read_csv(‘data.csv’, cols=[カラム名])
以下の不定積分の答えとして正しいものを選べ。Cは積分定数とする。
解説
分数の積分問題です。これは反対を考えると対数を微分すると真数を分母とした分数になることを知っていれば解けます。
対数の見方は次のイメージです。
:2の3乗は8になる。2を底、8を真数、3を指数と呼びます。
:2の3乗は8になる。2を底、8を真数、3を対数と呼びます。
以下のコードを実行した際の出力として正しいものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = a.copy()
a2 = a.reshape(3,2)
b*a2
array([[ 20, 100], [ 20, 100]])
array([[ 0, 1, 10], [ 0, 10, 100], [ 0, 11, 110]])
エラーになり、計算は実行できない
np.array([0,1,10, 0,1,10])
以下のような日付、日経平均の株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームのカラムの型を確認するためのメソッドとして正しいものを選べ
df.dtype
df.dtypes
df.columns
type(df)
dfと名付けられている、以下のようなデータフレームがある。このデータフレームから、人口/万人カラムを削除する場合のコードとして正しいものを選べ
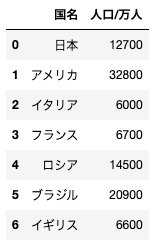
df.drop(“人口/万人”, axis=1)
df.drop(“人口/万人”, axis=0)
df.drop[“人口/万人”]
df[“人口/万人”].drop()
以下のコードの出力として正しいものを選べ
import pandas as pd
df = pd.DataFrame({"A":[1,2,3,4,5], "B":[6,7,8,9,10]})
df.iloc[1]>3
A False
B True
①
0 True
1 True
2 True
3 True
4 True
②
A False
③
0 False
1 False
2 False
3 True
4 True
④
①
②
③
④
解説
pandasのilocメソッドの問題です。ilocは行と列を数値で指定出来ます。df.iloc[1]は1次元目の1行目にアクセスします。
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.flatten()
A[1,:]=0
B[-1]
array([0, 0, 0])
6
array([6])
array([4, 5, 6])
解説
浅いコピーと深いコピーの問題です。この問題では深いコピーである flattenメソッドを使用しているのでAの変更はBに影響しません。
enjoyという出力を返すように、XXXXに当てはまるものとして正しいものを選べ
import re
pattern = r"enjoy"
text = "enjoy data science"
matchOB = re.match(pattern , text)
if matchOB:
print(matchOB.XXXX)
output()
group()
match()
search()
解説
reモジュールのgroupメソッドの問題です。groupメソッドはマッチした文字列を取得します。