問1
線形回帰について説明している以下の文章のうち正しいものを選べ
特徴量が5個以上あるデータには用いることができない
過学習することがないので、検証データを用意する必要はない。
分類する予測モデルを構築する際に使用するアルゴリズムである
L1正則化やL2正則化を用いることで過学習を抑えることができる
解説
線形回帰を用いて機械学習をする場合、学習や推定においてデータの上限はありません。過学習は起きるので扱う場合は検証データを用意したほうが良いと言えます。分類以外の予測モデルも構築が出来ます。線形回帰は過学習を抑えるために正則化を用いれます。L1正則化(Lasso回帰)とL2正則化(Ridge回帰)には違いがあります。前者は重みの合計を足したもので、後者は重みの二乗の合計を足したものです。
問2
以下のコードの出力として正しいものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = np.array([[100],[100]])
c = np.concatenate([a,b],axis=1)
c = c.reshape(4,2)
np.dot(c, b)
array([[100, 101, 110, 200], [100, 101, 110, 200]])
array([[ 0, 100, 1000], [ 0, 100, 1000], [10000, 10000, 10000]])
array([[10000, 10200, 12000]])
array([[ 100], [11000], [ 100], [11000]])
解説
NumPyの行列操作の問題です。上から読むと、行列a(2行, 3列)と行列b(2, 1)を定義します。cはaとbをaxis=1、つまり列(水平)方向で結合し、c(2, 4)となります。その後reshapeメソッドを用い4行2列に変換しています。np.dot(c, b)で行列積の計算をします。c(4, 2)@b(2, 1)ですので内側が2であってますので計算可能で、外側の数値がサイズになりますので、最後の行で出力するサイズは(4,1)になります。中身の数値はc@bの結果です。出力の一行目は(0100)+(1100)=100、2行目は(10100)+(100100)=11000というような出力になります。
問3
以下のコードを実行した場合に、出力されるグラフとして正しいものを選べ(ランダムのデータを使っているので形状は変わってもよい)
fig, ax = plt.subplots()
x1 = [x for x in range(1,4)]
y1 = [1,2,3]
x2 = [x for x in range(1,6)]
y2 = [np.random.randint(10) for x in range(5)]
ax.bar(x1, y1, label="y1")
ax.plot(x2, y2, label="y2")
ax.legend()
plt.show()
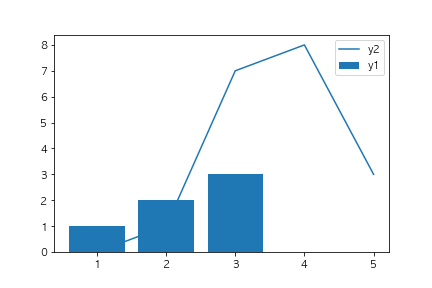
①
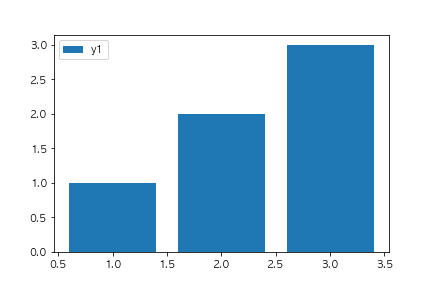
②
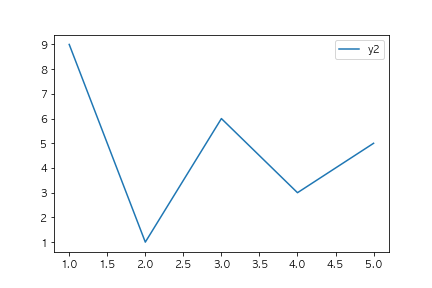
③
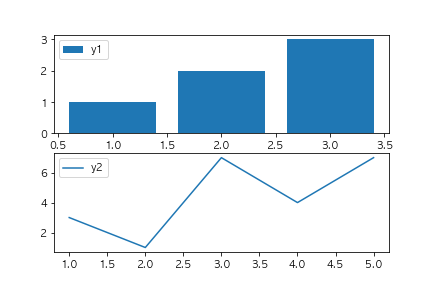
④
①
②
③
④
解説
barとplotメソッドを使っているため棒グラフと線グラフが表示されている選択肢に絞り込まれます。
またadd_subplotを使用していないことから①の選択肢が正しいことがわかります。
問4
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
問5
以下の文章のうちグリッドサーチの説明として正しいものを選べ
指定したパラメーターの全ての組み合わせを試す手法。組み合わせの総数分モデルの学習を行うので、探索が終わるのに時間がかかる
各パラメーターにおいて指定した分布から無作為に探索値を抽出するので、分布の仮定が間違っていると最適なチューニング結果にならない
パラメーター探索の仮定で、ベイズ推論を行なっているため計算に時間がかかる
どのパラメーターを探索するかはアルゴリズムが自動で選んでくれる
解説
得られた予測結果から最も精度の高いパラメータを求めます。
正解の選択肢にもあるようにパラメータの全ての組み合わせを試すため精度の高いパラメータをもとめるのに時間が多くかかる場合があります。
問6
連続的な値を確率変数として考えることができる分布として正しいものを選べ。
正規分布
二項分布
ポアソン分布
離散一様分布
解説
連続的な値を確率変数として考えることができる分布は正規分布です。
問7
pandasのcorr()メソッドでデフォルトで算出される相関係数の種類として、正しいものを選べ
スピアマンの相関係数
ケンドールの順位相関係数
ピアソンの相関係数
ピアソンの相関係数、スピアマンの順位相関係数、ケンドールの順位相関係数が全て算出される
解説
pandasのcorr()メソッドでデフォルトで算出される相関係数のはピアソンの相関係数です。
問8
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A[0,:]
A[0,:]=0
B
array([1, 2, 3])
array([0, 0, 0])
array([[1], [4]])
array([[0], [0]])
解説
浅いコピーと深いコピーの問題です。この問題では浅いコピーである通常の格納をしているのでAの変更はBにも影響します。
問9
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.flatten()
A[1,:]=0
B = B.reshape(6,1)
B[-1]
0
array([6])
array([0])
6
解説
浅いコピーと深いコピーの問題です。この問題では深いコピーである flattenメソッドを使用しているのでAの変更はBに影響しません。
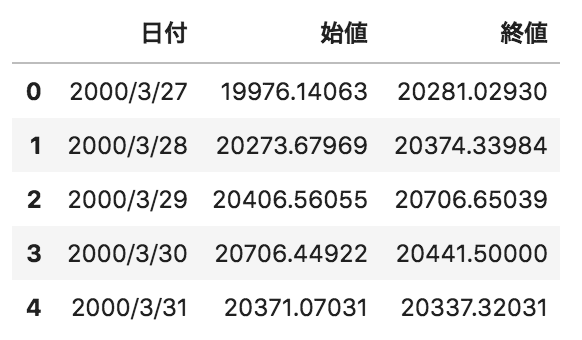
問10
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームにその日の株価の増減値(終値-始値)に応じて、ランクを付与するコードの実装として正しいものを選べ
①
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df["増減値"].apply(add_rank)
②
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df.add_rank(df["増減値"])
③
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply(add_rank(df["終値"] - df["始値"]))
④
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply().add_rank(df["終値"] - df["始値"])
①
②
③
④
問11
正規分布に従う乱数を生成するNumPyのメソッドとして、正しいものを選べ
np.random.randn()
np.random.rand()
np.random.random()
np.random.uniform()
解説
randam.randnメソッドで正規分布に従う乱数を取得できます。引数がない場合は単一の値を返します。また負の値はセットすることはできません。
問12
以下のコードの後に、np.dot(a, b)を実行した場合の出力と同じにならないものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = a.copy()
a = a.reshape(3,2)
np.multiply(a,b)
np.matmul(a,b)
a @ b
a.dot(b)
解説
multiplyは引数の要素ごとに乗算します。今回はbroadcastできないためエラーにもなります。
その他の選択肢は内積と行列積をおこなうメソッドであり, np.dot(a, b)を実行した場合の出力と同じ結果を得ます。
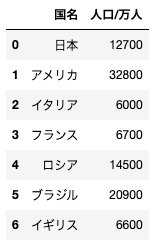
問13
dfと名付けられている、以下のようなデータフレームがある。このデータフレームから、人口/万人カラムを削除する場合のコードとして正しいものを選べ
df.drop(“人口/万人”, axis=1)
df.drop(“人口/万人”, axis=0)
df.drop[“人口/万人”]
df[“人口/万人”].drop()
解説
データフレームから特定の列や列を削除する場合には drop メソッドを使います。ここでは列を削除したいので axis=1 を指定しています。
問14
以下の関数のxに関する微分として正しいものを選べ
1
解説
対数の微分問題です。これは反対を考えると分数を積分すると分母を真数とした対数になることを知っていれば解けます。
対数の見方は次のイメージです。
:2の3乗は8になる。2を底、8を真数、3を指数と呼びます。
:2の3乗は8になる。2を底、8を真数、3を対数と呼びます。
問15
クラスタリング手法として適切でないものを以下の中から選べ
k-近傍法
k-means法
ウォード法
単純連結法
解説
k-近傍法は教師あり学習の分類と考えられるの適切ではありません。
問16
データサイエンティストに求められる能力として必須ではないものを選べ
プログラミング能力
案件を獲得するための営業能力
アルゴリズム構築に必要な数理的能力
顧客へわかりやすく分析結果を伝えるためのレポーティング能力
解説
データサイエンティストは企業をサポートするために、アルゴリズムや統計等を活用して有益な知見を見出す業務を担います。案件を獲得するための営業力は不要です。
問17
A = (1,2,3) B = (4,5,6)の2つの座標がある。座標AB間のユークリッド距離として正しいものを選べ
27
9
3
解説
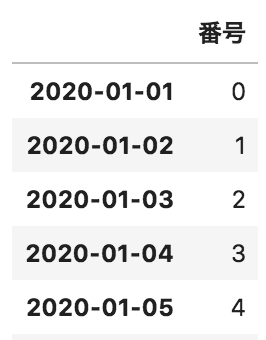
問18
以下のような、日付に対して番号が格納されているデータフレームdfがある。このデータフレームの月ごとの番号の平均を出力するコードとして正しいものを選べ
df.groupby(pd.Grouper(freq=”W”)).mean()
df.groupby(pd.Grouper(freq=”M”)).mean()
df.groupby(pd.Grouper(freq=”Y”)).mean()
df.groupby(freq=”M”).mean()
解説
引数のfreqにはオフセットエイリアスと呼ばれる文字列をセットできます。(Mだと毎月の頻度Wだと毎週の頻度)
対象のdfはindexが日付になっているので月ごとにでグルーピングし平均を取得するmeanメソッドを使い月毎の平均データを出力できます。
問19
三角関数でないものを以下の選択肢から選べ
cosx
sinhx
tanx
sinx
解説
三角関数ではないのは解答のsinhxです。
問20
scikit-learnのサポートベクターマシンのハイパーパラメーターのCについて説明している以下の文章のうち正しいものを選べ
Cの値が小さいほど、マージンは大きくなる
Cの値が大きいほど、マージンは大きくなる
C=Trueにすると、非線形の分類問題も境界線を求めることができるようになる
特徴量の数が大きいほど、Cの値も大きくする必要がある
解説
正則化項であるパラメータCは個々のデータポイントの重要度で、Cを無限大に大きくしていくとマージンは小さくなります。Cはデータポイントの重要度で、Cが大きいとデータポイントが決定境界に与える影響も大きくなります。決定境界とデータポイントまでの距離であるマージンはCが大きくなるに伴い小さくなります。
問21
6面体のサイコロをふったとき、偶数の目が出る確率として正しいものを選べ。
0.5
1/6
1
1/3
解説
6面体のサイコロを振った時に出るパターンは6通りです。偶数が出るのは3通りです。確率は、期待する事象/全体の事象 で求まります。 つまり3/6→1/2→0.5が正解です。
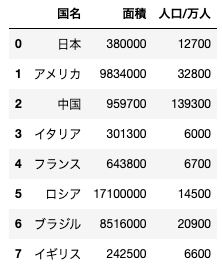
問22
import pandas as pd
df = pd.DataFrame({"国名":["日本","アメリカ","中国","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"面積":[380000, 9834000, 959700, 301300, 643800, 17100000, 8516000, 242500],
"人口/万人":[12700, 32800, 139300, 6000, 6700, 14500, 20900, 6600]})
上記コードを実行すると、以下のようなデータフレームが作成される。このデータフレームから中国のみのデータフレームを抜き出す処理として正しいものを選べ
df.sort_values(“人口/万人”, ascending=True).iloc[-1,:]
df[df[“国名”]!=”中国”]
df[df.index==2]
df[“国名”]==”中国”
解説
データフレームから特定のデータを抽出する問題です。ここではデータフレームに対して、indexパラメータを指定してデータを特定しています。抽出したデータを再度データフレームにする必要があるので外側でもデータフレームにしています。
問23
以下の不定積分の答えとして正しいものを選べ。Cは積分定数とする。
解説
分数の積分問題です。これは反対を考えると対数を微分すると真数を分母とした分数になることを知っていれば解けます。
対数の見方は次のイメージです。
:2の3乗は8になる。2を底、8を真数、3を指数と呼びます。
:2の3乗は8になる。2を底、8を真数、3を対数と呼びます。
問24
ROC曲線の横軸と縦軸が意味するものとして正しい組み合わせを以下の中から選べ
(横軸, 縦軸)= (偽陽性率, 真陽性率)
(横軸, 縦軸)= (真陽性率, 偽陽性率)
(横軸, 縦軸)= (適合率, 再現率)
(横軸, 縦軸)= (再現率, 適合率)
解説
ROC曲線では、横軸に偽陽性率、縦軸に真陽性率をプロットします。
問25
分散正規化を実施する以下のコードのXXXの部分に当てはまるものとして正しいものを選べ
※dfはデータが格納されているpandas データフレームとする
1 2 3 4 |
from sklearn.preprocessing import StandardScaler stdsc = StandardScaler() XXX |
stdsc.fit_transform(df)
stdsc.predict(df)
stdsc.transform(df)
stdsc.trans(df)
解説
特徴量の大きさを揃えるために正規化を行います。
分散正規化は、特徴量の平均値が0、標準偏差が1になるよう特徴量を変換する手法です。
1行で実行していることからfitと変換を同時に行っている
1 |
stdsc.fit_transform(df) |
が正しいです
問26
pandasのデータフレームの上から5行目までを表示させるメソッドとして、正しいものを選べ。
tail()
head()
view()
show()
解説
pandas のデータフレームの上から5行目までを表示させるメソッドは head() メソッドです。ちなみに末尾5行目を表示させるのは tail() メソッドです。
問27
1×2×3×4×5と同じ意味を表す数式として正しいものを選べ
解説
問28
matplotlibのグラフ描画に関する以下の説明のうち、間違っているものを選べ
1つのグラフオブジェクト内では、1つのフォントしか指定できない
日本語の文字列にも対応しているフォントがデフォルトでは指定されていない
グラフの軸ラベルの文字列を回転させることはできる
縦軸が左右にある2軸グラフを描画することはできる
解説
以下のコードのようにfontnameを指定することで別のフォントが使えます。
1 2 3 4 5 6 7 8 |
x = [1, 2, 3] y = [2, 4, 6] fig, ax = plt.subplots() ax.plot(x, y) ax.set_xlabel('X lable') ax.set_ylabel("Y label", fontname="Comic Sans MS") plt.show() |
またglobal設定をするとdefaultのフォント設定も変えることができます。
1 |
ax.set_ylabel("Y label", fontname="Comic Sans MS") |
問29
決定木の不純度の指標として、間違っているものを以下の中から選べ
情報利得
ジニ不純度
エントロピー
分類誤差
解説
不純度とは分類されたクラスに余計なものが含まれる割合のことです。
その割合を求める指標として
- ジニ不純度
- エントロピー
- 分類誤差
などがあります。
問30
以下のようなデータフレームdfがある。このデータフレームから国名カラムのみのデータフレームを抽出する際のコードとして正しくないものを選べ
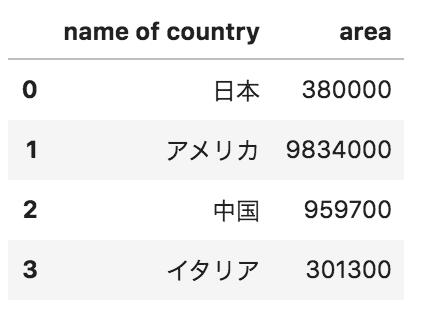
df.loc[:,[“name of country”]]
df.iloc[[0],:]
df.filter([“name of country”])
df[[“name of country”]]
解説
データフレームの抽出の問題です。抽出方法と次元を理解している必要があります。ここでは locを使い列名指定をしています。また、国名のカラムすべてを抽出しますので、行の次元はスライスの全選択をするコロン「:」が使われています。
問31
以下のような各日付に対して、利用回数と利用料金が格納されたデータフレームdfがある。このdfの欠損値をカラムごとの平均値で埋める処理として正しいものを選べ
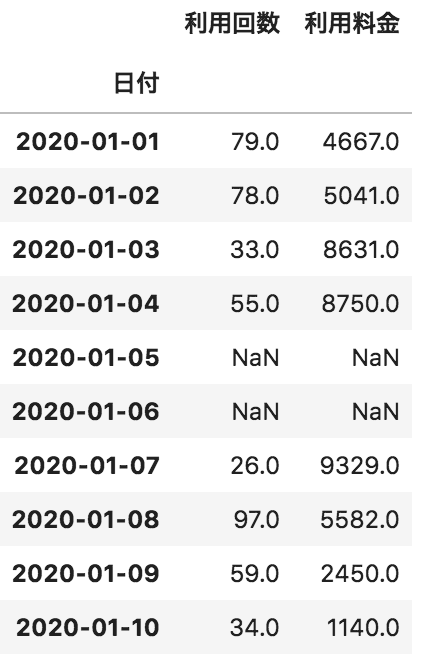
df.fillna(0)
df.dropna(0)
df.fillna(df.mean())
df.fillna(df.sum())
解説
fillnaメソッドを使うと欠損値(Na/NaN)の値を埋めることができます。問題文では平均値で埋めるとあるので引数にdf.mean()を適用します。
問32
matplitlibのpieメソッドを用いて円グラフを影をつけて表示させる場合の、pieメソッド内で指定する引数として正しいものを選べ
shadow=True
counterclock=True
explode=True
frame=True
解説
引数shadowにTrueをセットすることで影をつけれます。defaultではFalseが設定されています。
問33
以下のような、日付に対して番号が格納されているデータフレームdfがある。このデータフレームを水曜日までの1週間単位の番号の合計を出力するコードとして正しいものを選べ
df.groupby(pd.Grouper(freq=”W-WED”)).count()
df.groupby(pd.Grouper(freq=”M-WED”)).sum()
df.groupby(pd.Grouper(freq=”W-WED”)).mean()
df.groupby(pd.Grouper(freq=”W-WED”)).sum()
解説
引数のfreqにはオフセットエイリアスと呼ばれる文字列をセットできます。(Wだと毎週の頻度でMだと毎月の頻度)
そして一部のオフセットエイリアスにはアンカー接尾辞をつかうことができます。(今回だと-WED)
対象のdfはindexが日付になっているので水曜日ごとにでグルーピングし合計を取得するsumメソッドを使い1週間毎の合計データを出力できます。
問34
pipでインストールしたパッケージ一覧をテキストファイル(package_list.txt)に保存する際のコマンドとして、正しいものを選べ
pip output > package_list.txt
pip list output package_list.txt
pip freeze > package_list.txt
pip list < package_list.txt
解説
インストールされたパッケージを要件形式で出力します。結果をオプションでファイルに出力することが出来ます。
出典元 「pip」(2021年12月23日11時00分 UTC版) 『pip freeze — pip 9.1.0.dev0 ドキュメント』
問35
以下のようなデータフレームdfがある。このデータフレームのカラム名を変更する際のコードとして正しいものを以下の中から選べ
df.rename(columns={“name of country”:”国名”, “area”:”面積”})
df.rename(index={“国名”:”name of country”, “面積”:”area”})
df.rename(column={“国名”:”name of country”, “面積”:”area”})
df.columns({“国名”:”name of country”, “面積”:”area”})
解説
renameの引数にcolumnsを指定してdictもしくは関数を渡すことでカラム名を変更できます。
問36
モデルが選択した行動に対してどの程度よかったかを評価するために「価値」という概念を導入した、自律的に最適な行動選択を学習する枠組みをなんと呼ぶか
強化学習
教師なし学習
半教師あり学習
GAN(Generative Adversarial Network)
解説
強化学習の学習方策は2種類あります。価値ベース(Value-Based Method)と方策ベース(Policy-Based Method)です。問題文には価値の概念の取り入れた学習方策を聞かれているので解答は強化学習になります。
問37
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.eye(4)
first, second = np.vsplit(A, [3])
second.T
array([[0., 0., 0., 1.]])
array([[0., 0., 1., 0.], [0., 0., 0., 1.]])
array([[0., 0.], [0., 0.], [1., 0.], [0., 1.]])
array([[0.], [0.], [0.], [1.]])
解説
NumPyのメソッドの問題です。4行4列の単位行列を作成したあと、vsplitで3行目をsecondに入れます。1行4列のデータを転置しているので4行1列の選択肢が正解になります。
問38
以下のコードの出力として、正しいものを選べ
A = [1,2,3]
sum_num = 0
for num in A:
sum_num += num
print(sum_num)
0
sum_num
3
6
解説
コードリーディングの問題です。Aとsum_num変数を用意し、for文でAの中身を += を用いて順番に加算しています。(インクリメントを実現しています)for文が終わるとsum_numにAの和が格納されています。
問39
enjoyという出力を返すように、XXXXに当てはまるものとして正しいものを選べ
import re
pattern = r"enjoy"
text = "enjoy data science"
matchOB = re.match(pattern , text)
if matchOB:
print(matchOB.XXXX)
output()
group()
match()
search()
解説
reモジュールのgroupメソッドの問題です。groupメソッドはマッチした文字列を取得します。
問40
R言語について説明している以下の文章のうち、正しいものを選べ
DeepLearningのフレーワークにはR用のパッケージは存在しない
Rで機械学習モデルを構築する場合、scikit-learnのR用パッケージをインストールしなければならない
R言語はグラフ描画をするためのパッケージが存在しない
RにはC++を使うためのパッケージが存在し、高速化をする際によく用いられる
解説
「RにはC++を使うためのパッケージが存在し、高速化をする際によく用いられる」例としてdplyrというパッケージが存在しています。plyr の派生パッケージでデータフレームの処理を高速に行います。