| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
データサイエンティストの役割について説明している以下の文章のうち、正しいものを選べ
技術の進歩が速い分野なので、論文などを読んで最新技術をキャッチアップする必要がある
Pythonで実装できるモデルを扱うことが多く、R言語を知っておく必要はない
業務中に自分でPCを修理する場合もあるので、コンピューターの内部構造や動作原理などを知っておく必要がある
データ分析さえできればよく、顧客の立場になり、その分析結果をどう使えるかまでを考えて分析する必要はない
問2
ランダムフォレストについて説明している以下の文章のうち、正しい選択肢を選べ
他の機械学習アルゴリズムと比較すると、欠損値の穴埋めや標準化などのデータの前処理を必要としないアルゴリズムである。
いくつかの決定木を作成するが、作成する木の数は自分で決めることができず、決まっている。
ランダムフォレストは、特徴量の数が多い分類問題にしか適用できない。
どの特徴量がモデルの出力に寄与しているかの程度を確認する指標が存在しない。
問3
特徴量の次元削減について説明している以下の文章のうち、正しいものを選べ
なるべくデータの情報を落とさずに、少ない特徴量でデータを表現するために用いられる
次元削減の手法には非線形変換を行う手法のみ存在する
scikit-learnで実装されている主成分分析を使用する際、次元数をいくつまで削減するかを指定することはできない
数学的には、内部で積分計算を行なっている
問4
scikit-learnのLogisticRegressionクラスを用いてモデルを構築した場合のラベルの予測確率を取得する関数として正しいものを以下の中から選べ
predict_proba()
predict()
get_params()
predict_log_proba()
問5
以下の説明文のうち、線形回帰の中で微分が使用される理由として正しいものを選べ
損失関数と呼ばれる関数を最小にするパラメーターを求める際に必要だから
損失関数と呼ばれる関数が描く面積を求める際に必要だから
仮定関数を決める際に必要だから
予測結果の妥当性を検証する際に必要だから
問6
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
問7
以下のコードは、欠損値をカラムごとの平均値で埋めるために書かれたコードである。以下のコードのXXXの部分に記述されるコードとして正しいものを選べ
※dfは欠損を含むデータが格納されているpandasデータフレームである, versionは0.20以上
from sklearn.impute import SimpleImputer
XXX
imp.fit(df)
imp.transform(df)
imp = SimpleImputer(strategy=”mean”)
imp = SimpleImputer(strategy=”median”)
imp = SimpleImputer(strategy=”mean”, axis=1)
imp = SimpleImputer(strategy=”median”, axis=0)
問8
np.random.randint(1,11)を繰り返し実行した場合の平均値は、繰り返し回数が多ければ多いほど、ある値に近づいていく。ある値として正しいものを以下の中から選べ。
1
11
3.5
5.5
問9
import pandas as pd
df = pd.DataFrame({"国名":["日本","アメリカ","中国","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"面積":[380000, 9834000, 959700, 301300, 643800, 17100000, 8516000, 242500],
"人口/万人":[12700, 32800, 139300, 6000, 6700, 14500, 20900, 6600]})
上記コードを実行すると、以下のようなデータフレームが作成される。このデータフレームから中国のみのデータフレームを抜き出す処理として正しいものを選べ
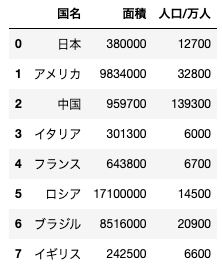
df.sort_values(“人口/万人”, ascending=True).iloc[-1,:]
df[df[“国名”]!=”中国”]
df[df.index==2]
df[“国名”]==”中国”
解説
データフレームから特定のデータを抽出する問題です。ここではデータフレームに対して、indexパラメータを指定してデータを特定しています。抽出したデータを再度データフレームにする必要があるので外側でもデータフレームにしています。
問10
Jupyter Notebookについて説明している以下の文章のうち、正しいものを選べ
セル上で、シェルコマンドを実行する際には’#’を行頭に入力する
セル上で、シェルコマンドを実行する際には’!’を行頭に入力する
セル上で、シェルコマンドを実行する際には’%’を行頭に入力する
セル上で、シェルコマンドを実行する際には’’を行頭に入力する
問11
データサイエンティストやデータエンジニアが使用するツールについて説明している以下の文章のうち、正しいものを選べ
scikit-learnやNumPy、pandasの役割について理解しておく必要はない
たとえデータが小さくても、自分のPCでデータ分析を実施してはならない
anacondaなどの環境構築を行うためのツールは、分析の再現性という観点から実務では使ってはならない
Pythonを用いて前処理や集計をする必然性はなく、Excelを用いて実施してもよい
問12
交差検証の欠点として、各検証における予測ラベルの割合が不均一になる問題がある。この問題を解決する場合に使用される交差検証の名称として正しいものを選べ
層化k分割交差検証
均一k分割交差検証
ブートストラップ法
Leave-One-Out法
問13
matplotlibについて説明している以下の文章のうち、正しいものを選べ。
matplotlibはグラフを描画する際に用いられるライブラリである
matplotlibは多次元配列の演算の記述を簡便にするために用いられるライブラリである
matplotlibはテーブルデータなどの表形式のデータをハンドリングする際に用いられるライブラリである。
matplotlibは、機械学習のアルゴリズムを用いてモデルを構築するために使用するライブラリである。
問14
以下のコードの出力として正しいものを選べ
A = [x for x in range(10)]
B = {x for x in range(20)}
if len(A)==10:
print("A")
elif len(A)==10&len(B)==20:
print("A,B")
else:
print("None")
A
A, B
None
A A, B
問15
以下の行列について特徴として誤っているものを選べ
単位行列である
非正方行列である
対角行列である
逆行列が存在する
問16
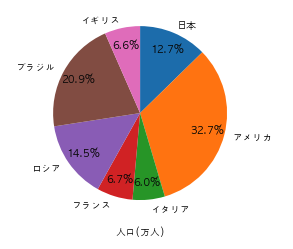
以下のコードを実行した際に出力されるグラフとして正しいものを選べ
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({"国名":["日本","アメリカ","イタリア","フランス", "ロシア", "ブラジル", "イギリス"], "人口/万人":[12700, 32800, 6000, 6700, 14500, 20900, 6600]})
plt.rcParams["font.family"] = "AppleGothic"
plt.barh(df["国名"], df["人口/万人"])
plt.xlabel("人口(万人)")
plt.show()
①
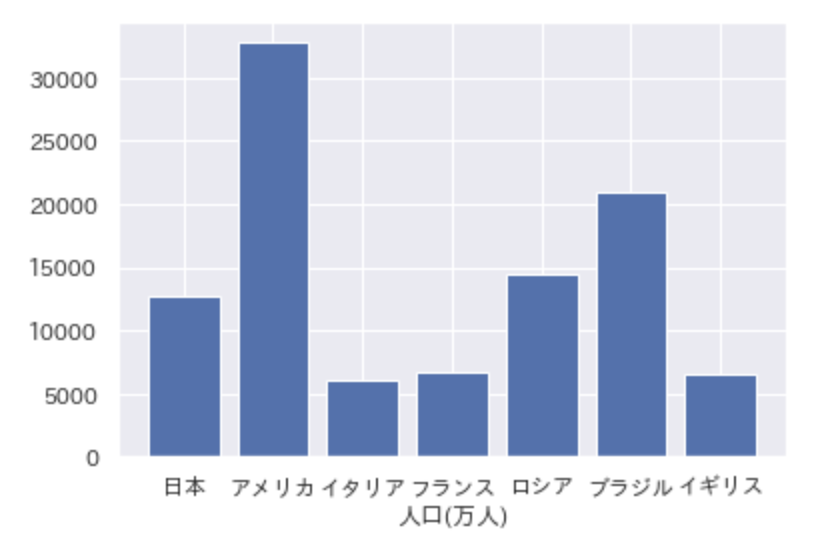
②
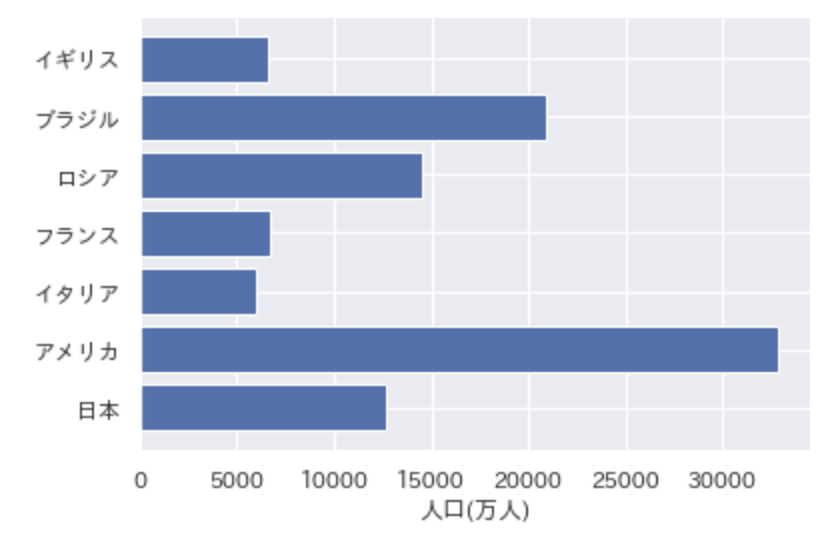
③
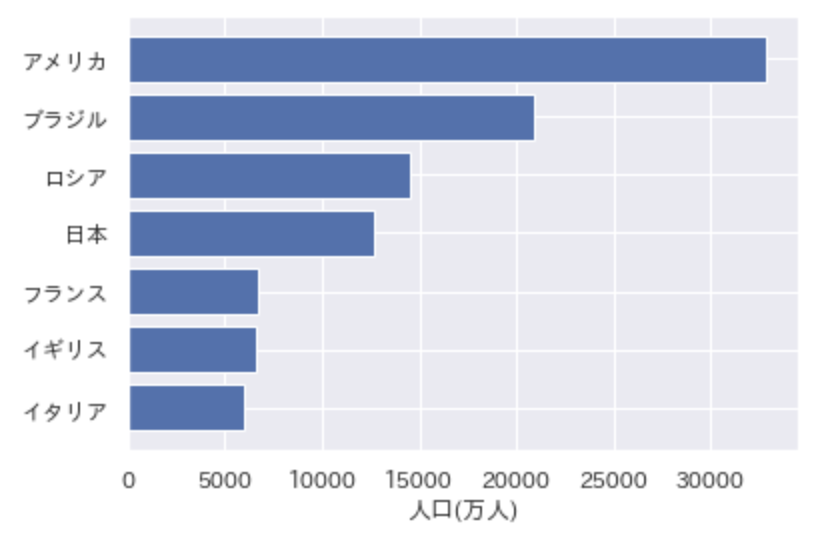
④
①
②
③
④
問17
pandasデータフレームdfをNumPy配列に変換する処理として正しいものを選べ
np.convert(df)
df.values
np.ndarray(df)
df.array
問18
機械学習を用いたデータ分析において、データを入手してからモデルの学習を実施するまでの処理手順として、正しいものを選べ
データ入手→アルゴリズム選択→データ加工→データ可視化→モデルの学習
データ入手→アルゴリズム選択→データ加工→データ可視化→モデルの学習
データ入手→データ可視化→アルゴリズム選択→データ加工→モデルの学習
データ入手→データ加工→データ可視化→アルゴリズム選択→モデルの学習
問19
機械学習アルゴリズムにおける、ハイパーパラメーターの説明として正しいものを以下の中から選べ
学習時にアルゴリズムで決定されず、モデル構築者が指定する必要があるパラメーター
学習時に機械学習アルゴリズムにより最適化される値
モデルの評価指標に使用されるパラメーター
モデルの損失関数に使用されるパラメーター
問20
10面体のサイコロの期待値として正しいものを選べ。
5
1/10
3.5
5.5
問21
以下の関数のxに関する微分として正しいものを選べ
1
問22
データエンジニアの役割について説明している以下の文章のうち、間違っているものを選べ
データベースの扱いは、サーバーサイドエンジニア が知っていればよく、SQLなどのデータベースを扱う言語をデータ分析者が知っておく必要はない
機械学習だけでなく、深層学習についても知っておく必要がある
データ数が100サンプルのデータを扱うこともありえる
クラウドサービスを用いてデータハンドリングを行う場合、金銭的、時間的コストを考えてコードを実装する必要がある
問23
以下のコードを実行した際に、Aについて述べているものとして、間違っているものを選べ
import numpy as np
A = np.random.rand(10,1)
Aの配列の形状は(10,1)である。
Aに格納されている値は全て、標準正規分布に従う乱数である。
中心が10、標準偏差が1に従う正規分布から生成された乱数が格納されている
Aに格納されている値は0以上1未満の浮動小数点数である。
問24
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[0, 1, 2, 3, 4]])
B = np.full((1, 5), 1)
A[A>=B]
array([1, 2, 3, 4])
array([False, True, True, True, True])
array([[1, 2, 3, 4]])
array([[False, True, True, True, True]])
問25
csvファイルをpandasで読み込む場合に、読み込むカラムを指定する方法として正しいものを選べ
※選択肢中の’data.csv’ は読み込む元データが格納されたcsvファイルとする
pd.read_csv(‘data.csv’, usecols=[カラム名])
pd.read_csv(‘data.csv’, index_col=[カラム名])
pd.read_csv(‘data.csv’, use_cols=[カラム名])
pd.read_csv(‘data.csv’, cols=[カラム名])
問26
以下の関数f(x, y)のyに関する偏微分として正しいものを選べ
問27
loggingモジュールには、5種類のログレベル(重要度)でログを出力するためのメソッドが用意されています。重要度の高い順にメソッドを並び替えたものとして、正しいものを選べ。
critical()→error()→info()→debug()→warning()
debug()→critical()→error()→warning()→info()
critical()→error()→warning()→info()→debug()
critical()→error()→warning()→debug()→info()
問28
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.flatten()
A[1,:]=0
B = B.reshape(6,1)
B[-1]
0
array([6])
array([0])
6
問29
サポートベクターマシンについて説明している以下の文章のうち正しいものを選べ
scikit-learnで使用する場合、カーネルはガウスカーネル以外にも指定することができる
内部で欠損値を処理するアルゴリズムが実装されているため、欠損値はNULL値のままでよい
線形分離可能な問題にのみ適用できる
マージンの距離を最小にするように最適化するアルゴリズムである
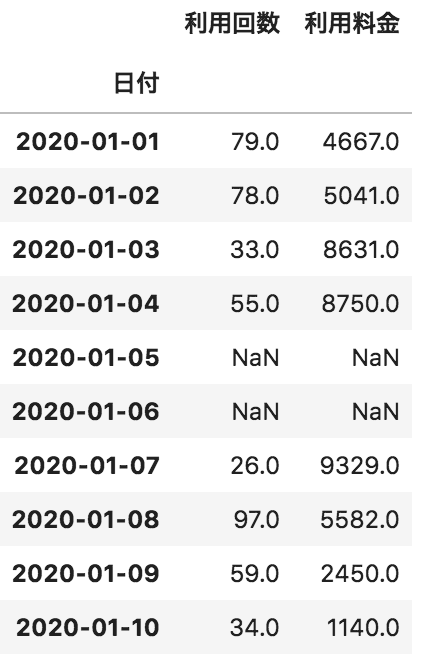
問30
以下のような各日付に対して、利用回数と利用料金が格納されたデータフレームdfがある。このdfの欠損値をカラムごとの平均値で埋める処理として正しいものを選べ
df.fillna(0)
df.dropna(0)
df.fillna(df.mean())
df.fillna(df.sum())
問31
三角関数でないものを以下の選択肢から選べ
cosx
sinhx
tanx
sinx
問32
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.flatten()
A[1,:]=0
B[-1]
array([0, 0, 0])
6
array([6])
array([4, 5, 6])
問33
venvやAnacondaで作成した仮想環境から抜ける際に使用するコマンドとして正しいものを選べ
exit
deactivate
quit
escape
問34
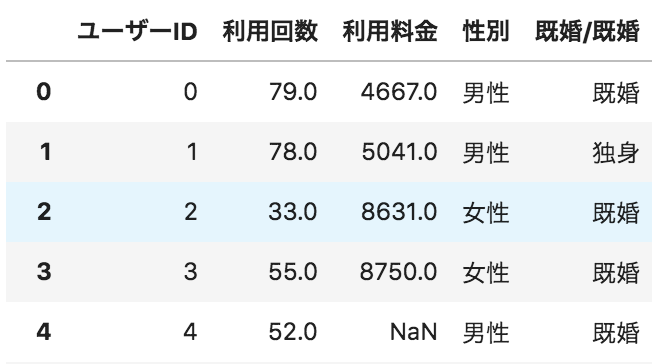
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
利用回数の箱ひげ図を描画するコードとして正しいものを選べ
import matplotlib.pyplot as plt
plt.boxplot(df["利用回数"])
plt.show()
①
import matplotlib.pyplot as plt
plt.hist(df["利用回数"])
plt.show()
②
import matplotlib.pyplot as plt
plt.violinplot(df["利用回数"])
plt.show()
③
import matplotlib.pyplot as plt
df["利用回数"].boxplot()
plt.show()
④
①
②
③
④
問35
以下のコードを実行した場合にxxに格納されるデータとして正しいものを選べ。
import numpy as np
m = np.arange(4)
n = np.arange(4)
xx, yy = np.meshgrid(m,n)
array([[0, 1, 2, 3], [0, 1, 2, 3], [0, 1, 2, 3], [0, 1, 2, 3]])
array([[0, 1, 2, 3], [0, 1, 2, 3]])
array([0, 1, 2, 3])
array([0, 1, 4, 9])
問36
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 0]])
B = np.array([1, 0])
A @ B
array([1])
array([[1]])
array([[1, 1]])
array([[1, 1], [1, 1]])
問37
以下のような日付ごとの利用回数と利用料金が格納されたpandasデータフレームdfがある。このデータフレームdfの利用回数の「最大値」を出力するコードとして正しいものを選べ
df[“利用回数”].mode()
df[“利用回数”].max()
df[“利用回数”].count()
df[“利用回数”].median()
問38
以下のようなデータが格納されたexample.csvというファイルをpandasデータフレームとして読み込むためのコードとして正しいものを選べ。
国名,面積
日本,380000
アメリカ,9834000
中国,959700
イタリア,301300
import pandas as pd
df = pd.read_csv("example.csv")
①
import pandas as pd
df = pd.read_excel("example.csv")
②
import pandas as pd
df = pd.read_pickle("example.csv")
③
import pandas as pd
df = pd.load_csv("example.csv")
④
①
②
③
④
問39
以下の説明のうち、最頻値の説明として正しいものを選べ。
データの中でもっとも大きい値のこと。
データを小さい順に並べて、ちょうど真ん中にくる値である。データの個数が偶数と奇数の場合で算出方法が異なる
もっとも多く出現するデータ・値であり、アンケートなどの最多回答者などがこれに相当する。
データ全体がどの程度ばらついているかを示す値。
問40
以下のようなデータフレームdfがある。このデータフレームから、B列の値が3000以上のデータフレームを抽出するコードとして正しいものを選べ。
import pandas as pd
df = pd.DataFrame({"A":[10,200,3000,40000],
"B":[1000,2000,3000,4000]})
df[[“B”]>=3000]
df[“B”]>=3000
df[df[“B”]>=3000]
df[df[“B”]>=3000][“B”]