| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
欠損値の対処方法として、間違っているものを選べ
One-hotエンコーディングを行う
その特徴量の統計的な代表値などで埋める
欠損値があるデータを用いない
欠損がある場合でも動作する機械学習アルゴリズムを選定する
問2
scikit-learnのサポートベクターマシンのハイパーパラメーターのCについて説明している以下の文章のうち正しいものを選べ
Cの値が小さいほど、マージンは大きくなる
Cの値が大きいほど、マージンは大きくなる
C=Trueにすると、非線形の分類問題も境界線を求めることができるようになる
特徴量の数が大きいほど、Cの値も大きくする必要がある
解説
正則化項であるパラメータCは個々のデータポイントの重要度で、Cを無限大に大きくしていくとマージンは小さくなります。Cはデータポイントの重要度で、Cが大きいとデータポイントが決定境界に与える影響も大きくなります。決定境界とデータポイントまでの距離であるマージンはCが大きくなるに伴い小さくなります。
問3
以下のコードの出力として正しいものを選べ
fig, ax = plt.subplots()
x = [10, 20, 30]
label=[1 ,2, 3]
ax.pie(x, autopct="%1.1f%%", labels=label)
plt.show()
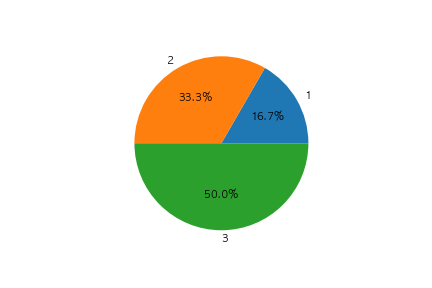
①

②
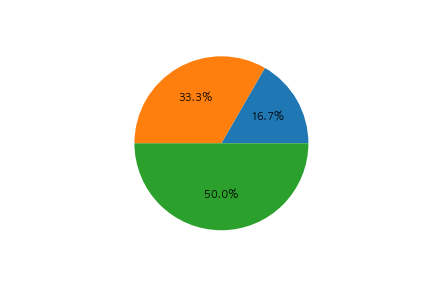
③
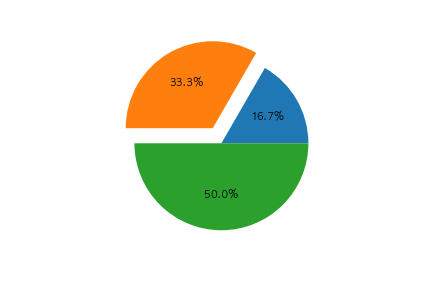
④
①
②
③
④
問4
決定木の不純度の指標として使用される「ジニ不純度」の説明している以下の文章のXXXとYYYに当てはまる組みとして正しいものを選べ
ある2つのカテゴリー(ラベル0とラベル1)を持つ特徴量を分割する場合のジニ不純度は、ラベル0なのにラベル1と割り振られる確率とラベル1なのにラベル0と割り振られる確率のXXXを考える必要がある。クラス0である確率をP(0)、クラス1である確率をP(1)とすると、求めるジニ不純度は
となる
XXX = 和, YYY = 2
XXX = 積, YYY = 2
XXX = 積, YYY = 1/2
XXX = 和, YYY = 1/2
問5
scikit-learnで実装されているk-means法について説明している以下の文章のうち間違っているものを選べ
クラスターの重心位置の更新計算は、指定した回数分だけ行われる
教師なし学習であるため、教師ラベルは必要ない
initの引数に”random”を指定すると、最初のクラスター点をデータの中からランダムに選ぶため、初期値依存性がある
クラスターの個数は、使用者が指定する必要がある
問6
機械学習モデルについて説明している以下の文章のうち間違っているものを選べ
機械学習モデルでは、何かを分類するタスクしか解くことができない
ラベルではなく数値そのものを予測する問題を回帰問題という
データが大量に存在する場合にモデルを構築する際は、学習データ、検証データ、テストデータの3つに分割するのが理想である
異なる検証データで結果を比較するために、交差検証を実施することもある
問7
scikit-learnのLogisticRegressionクラスを用いてモデルを構築した場合のラベルの予測確率を取得する関数として正しいものを以下の中から選べ
predict_proba()
predict()
get_params()
predict_log_proba()
問8
サポートベクターマシンについて説明している以下の文章のうち正しいものを選べ
scikit-learnで使用する場合、カーネルはガウスカーネル以外にも指定することができる
内部で欠損値を処理するアルゴリズムが実装されているため、欠損値はNULL値のままでよい
線形分離可能な問題にのみ適用できる
マージンの距離を最小にするように最適化するアルゴリズムである
問9
データエンジニアの役割について説明している以下の文章のうち、正しいものを選べ
データエンジニアはモデリングのみを担当することが多く、データの前処理を行うことはない
データエンジニアはデータサイエンティストと連携して、予測モデルを構築するためのデータの前処理や抽出作業を行うことがある
データエンジニアはモデリングのみを担当することが多く、データの概要把握のためのデータ集計やデータ可視化を行うことはない。
データエンジニアが使用するツールはwindowsOSでしか動作しないものが多く、windowsOSを使わなければならない
問10
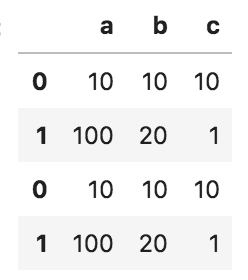
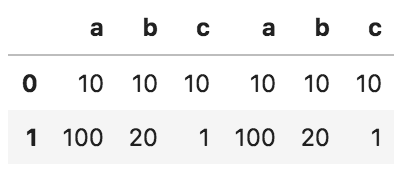
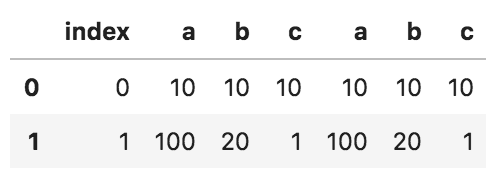
以下のコードの出力として正しいものを選べ
import pandas as pd
df_1 = pd.DataFrame({'a': [10, 100], 'b': [10, 20], 'c': [10, 1]})
df_2 = pd.DataFrame({'a': [10, 100], 'b': [10, 20], 'c': [10, 1]})
pd.concat([df_1, df_2], axis=0).reset_index(drop = True)
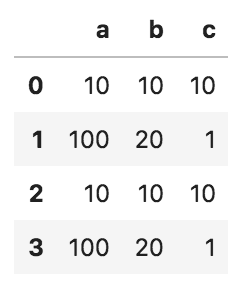
①
②
③
④
①
②
③
④
問11
import pandas as pd
df = pd.DataFrame({"国名":["日本","アメリカ","中国","イタリア","フランス", "ロシア", "ブラジル", "イギリス"],
"面積":[380000, 9834000, 959700, 301300, 643800, 17100000, 8516000, 242500]})
上記コードを実行した後に、以下の写真の出力を得るために実行するべきコードを選べ
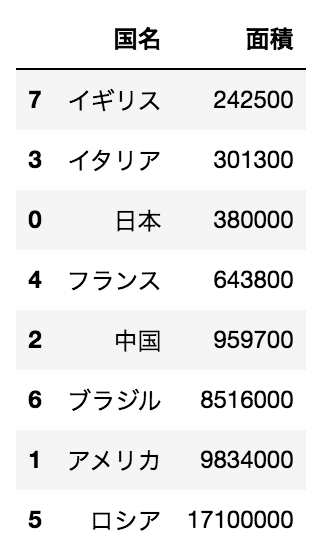
df[“面積”].sort_values()
df.sort_values(“面積”, ascending=False)
df.sort_values(“面積”)
df[“面積”].sort_values(ascending=False)
問12
以下の不定積分の答えとして正しいものを選べ。Cは積分定数とする。
問13
datetimeモジュールについて説明している以下の文章のうち、誤っているものを選べ
取得する日付や日時のタイムゾーンを指定することができる
now()を使用することで、今日の日付を取得することができる
日数の差分を算出するなど、日付同士の演算をすることができない。
日時(datatime型)→文字列の変換はできるが、文字列→日時(datatime型)の変換はできない
問14
以下のコードの出力として正しいものを選べ
import numpy as np
a = np.array([[0,1,10],[0,1,10]])
b = np.array([[100],[100]])
c = np.concatenate([a,b],axis=1)
c = c.reshape(4,2)
np.dot(c, b)
array([[100, 101, 110, 200], [100, 101, 110, 200]])
array([[ 0, 100, 1000], [ 0, 100, 1000], [10000, 10000, 10000]])
array([[10000, 10200, 12000]])
array([[ 100], [11000], [ 100], [11000]])
問15
以下のコードを実行した際の出力として正しいものを選べ
import copy
A = [1,2,3]
B = A.copy()
A.append(4)
B
[1,2,3,4]
[1,2,3]
[[1,2,3],[1,2,3]]
[ ]
問16
Jupyter Notebookについて説明している以下の文章のうち、正しいものを選べ
単一行でセルを実行できることもあり、セル内で関数を作成することは良くない
単一のコードを実行できることもあり、後から見直した時のために、セルとセルの間には適度に、コメントを残すべきである
ノートブックが複数に別れていると面倒なので、ノートブックは長くても1つに納める方が良い
使っていないノートブックは自動でシャットダウンされるので、いくつでもノートブックを開くことは問題ない
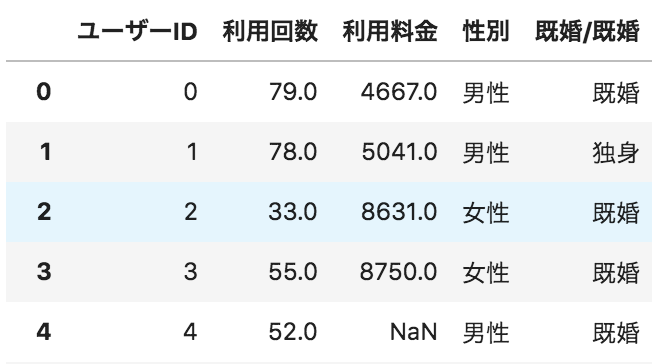
問17
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
利用回数の箱ひげ図を描画するコードとして正しいものを選べ
import matplotlib.pyplot as plt
plt.boxplot(df["利用回数"])
plt.show()
①
import matplotlib.pyplot as plt
plt.hist(df["利用回数"])
plt.show()
②
import matplotlib.pyplot as plt
plt.violinplot(df["利用回数"])
plt.show()
③
import matplotlib.pyplot as plt
df["利用回数"].boxplot()
plt.show()
④
①
②
③
④
問18
クラスタリング手法として適切でないものを以下の中から選べ
k-近傍法
k-means法
ウォード法
単純連結法
問19
以下の文章のうちグリッドサーチの説明として正しいものを選べ
指定したパラメーターの全ての組み合わせを試す手法。組み合わせの総数分モデルの学習を行うので、探索が終わるのに時間がかかる
各パラメーターにおいて指定した分布から無作為に探索値を抽出するので、分布の仮定が間違っていると最適なチューニング結果にならない
パラメーター探索の仮定で、ベイズ推論を行なっているため計算に時間がかかる
どのパラメーターを探索するかはアルゴリズムが自動で選んでくれる
問20
機械学習を用いたデータ分析において、データを入手してからモデルの学習を実施するまでの処理手順として、正しいものを選べ
データ入手→アルゴリズム選択→データ加工→データ可視化→モデルの学習
データ入手→アルゴリズム選択→データ加工→データ可視化→モデルの学習
データ入手→データ可視化→アルゴリズム選択→データ加工→モデルの学習
データ入手→データ加工→データ可視化→アルゴリズム選択→モデルの学習
問21
棒グラフが出力されるコードとして正しいものを選べ
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.bar(x, y)
plt.show()
①
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.scatter(x, y)
plt.show()
②
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.plot(x, y)
plt.show()
③
fig, ax = plt.subplots()
x = [1,2,3]
y = [10, 20, 30]
ax.boxplot(x, y)
plt.show()
④
①
②
③
④
問22
配列の形状が(2,10)であり、各要素が平均2、標準偏差5の正規分布に従う乱数を生成するコマンドとして正しいものを選べ。
np.random.normal[2,5,size=(2,10)]
np.random.random(2,5,size=(2,10))
np.random.normal(2,5,size=(2,10))
np.random.rand(2,5,size=(2,10))
問23
scikit-learnのGridSearchCVクラスには、もっとも精度が良い時のハイパーパラメーターの値を取得するための属性がある。その属性として正しいものを選べ
best_params_
best_estimator_
best_index_
cv_results_
問24
A = (1,2,3) B = (4,5,6)の2つの座標がある。座標AB間のユークリッド距離として正しいものを選べ
27
9
3
問25
AUCはROC曲線から算出されるが、具体的にはROC曲線の何を算出したものか。以下の中から正しいものを選べ
ROC曲線の面積
ROC曲線の縦軸の最大値
ROC曲線の横軸の最大値
ROC曲線の勾配(微分)
問26
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 1],[1, 1]])
B = np.array([1, 1])
np.dot(A, B)
array([[1, 1], [1, 1]])
array([[2, 2]])
array([2, 2])
実行不可(エラーが出る)
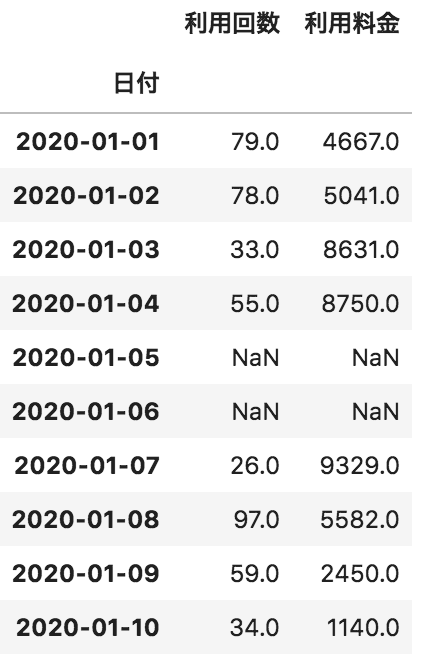
問27
以下のような各日付に対して、利用回数と利用料金が格納されたデータフレームdfがある。このdfの欠損値を0で埋める処理として正しいものを選べ
df.fillna()
df.fillna(method=”ffill”)
df.dropna(0)
df.fillna(0)
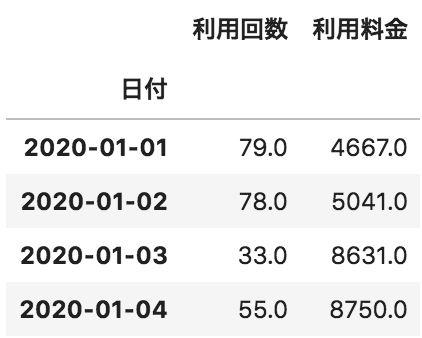
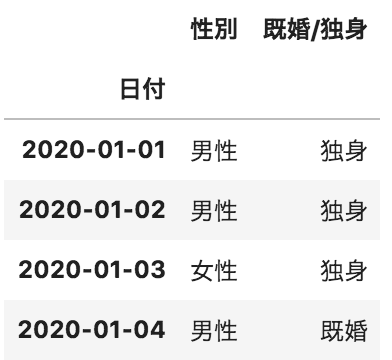
問28
以下のような、pandasデータフレームAとpandasデータフレームBがある。この2つのデータフレームの日付が一致する部分のみを列方向に結合したデータフレームを作成するコードとして正しいものを選べ
A
B
pd.merge(A, B, how=”left”, on=”日付”)
pd.join(A, B, how=”inner”, on=”日付”)
pd.merge(A, B, how=”inner”, on=”日付”)
pd.merge([A, B], how=”inner”, on=”日付”)
問29
以下のコードの出力として正しいものを選べ
import pandas as pd
df = pd.DataFrame({"A":[1,2,3,4,5], "B":[6,7,8,9,10]})
df.iloc[1]>3
A False
B True
①
0 True
1 True
2 True
3 True
4 True
②
A False
③
0 False
1 False
2 False
3 True
4 True
④
①
②
③
④
問30
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
問31
pip freeze コマンドの説明として正しいものを選べ
インストールされているパッケージの一覧を出力する
pipのバージョンを最新にする
実行中のpipコマンドを強制終了するコマンド
現在のpipのバージョンを出力するコマンド
問32
以下のような、ユーザーごとのサービス利用状況が格納されたデータフレームdfがある。
横軸に利用回数、縦軸に利用料金の散布図を描画するためのコードとして正しいものを選べ
①
import matplotlib.pyplot as plt
plt.scatter(df["利用回数"],df["利用料金"])
plt.show()
②
import matplotlib.pyplot as plt
plt.scatter(df["利用料金"],df["利用回数"])
plt.show()
③
import matplotlib.pyplot as plt
plt.plot(df["利用回数"],df["利用料金"])
plt.show()
④
import matplotlib.pyplot as plt
df["利用回数"].scatter(df["利用料金"])
plt.show()
①
②
③
④
問33
以下の行列について特徴として誤っているものを選べ
単位行列である
非正方行列である
対角行列である
逆行列が存在する
問34
数値データが格納されたpandasデータフレームに対して、describeメソッドを用いて算出することができない統計量として正しいものを選べ
最大値
外れ値
平均値
データ件数
問35
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
A = np.array([[1, 3, 5]])
B = np.array([[6, 8, 10]])
C = np.concatenate([A, B], axis=0)
D = np.diff(C, axis=0)
np.sum(D)
8
33
15
9
問36
線形回帰について説明している以下の文章のうち正しいものを選べ
特徴量が5個以上あるデータには用いることができない
過学習することがないので、検証データを用意する必要はない。
分類する予測モデルを構築する際に使用するアルゴリズムである
L1正則化やL2正則化を用いることで過学習を抑えることができる
問37
以下のコードを実行した場合の出力として正しいものを選べ。
import numpy as np
A = np.array([[1,2,3],[4,5,6]])
B = A.ravel()
A[0,:]=0
B.reshape(3,2)
array([[1, 2, 3], [4, 5, 6]])
array([[0, 2], [3, 0], [5, 6]])
array([[0, 0], [0, 4], [5, 6]])
array([[1, 2], [3, 4], [5, 6]])
問38
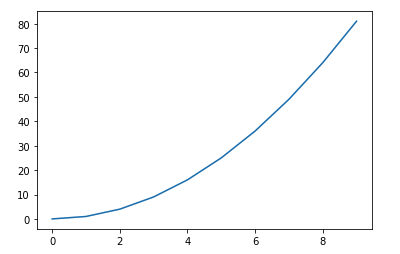
以下のコードを実行すると、写真のようなグラフが描画される
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list)
plt.show()
グラフの線の色を赤色に変更したい場合のコードとして、正しいものを選べ
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list, color = "red")
plt.show()
①
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list)
plt.show(color = "red")
②
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list, ls="--")
plt.show()
③
import matplotlib.pyplot as plt
x_list = [i for i in range(10)]
y_list = list(map(lambda x: x**2, x_list))
plt.plot(x_list, y_list, style="red")
plt.show()
④
①
②
③
④
問39
dfと名付けられている、以下のようなデータフレームがある。このデータフレームから、人口/万人カラムを削除する場合のコードとして正しいものを選べ
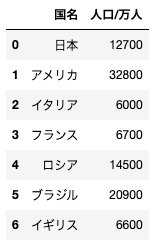
df.drop(“人口/万人”, axis=1)
df.drop(“人口/万人”, axis=0)
df.drop[“人口/万人”]
df[“人口/万人”].drop()
問40
以下のコードを実行した際に出力されるグラフとして正しいものを選べ
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({"国名":["日本","アメリカ","イタリア","フランス", "ロシア", "ブラジル", "イギリス"], "人口/万人":[12700, 32800, 6000, 6700, 14500, 20900, 6600]})
df = df.sort_values("人口/万人")
plt.rcParams["font.family"] = "AppleGothic"
plt.bar(df["国名"], df["人口/万人"])
plt.ylabel("人口(万人)")
plt.show()
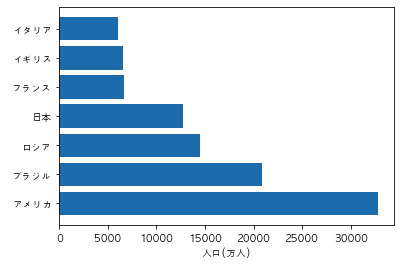
①
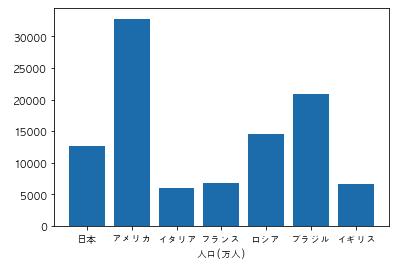
②
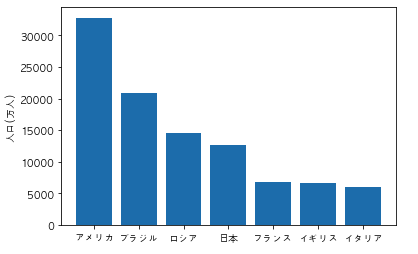
③
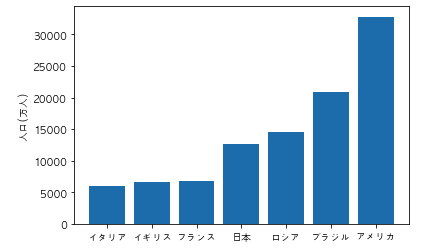
④
①
②
③
④