| 問番号 |
|---|
| 問1 |
| 問2 |
| 問3 |
| 問4 |
| 問5 |
| 問6 |
| 問7 |
| 問8 |
| 問9 |
| 問10 |
| 問番号 |
|---|
| 問11 |
| 問12 |
| 問13 |
| 問14 |
| 問15 |
| 問16 |
| 問17 |
| 問18 |
| 問19 |
| 問20 |
| 問番号 |
|---|
| 問21 |
| 問22 |
| 問23 |
| 問24 |
| 問25 |
| 問26 |
| 問27 |
| 問28 |
| 問29 |
| 問30 |
| 問番号 |
|---|
| 問31 |
| 問32 |
| 問33 |
| 問34 |
| 問35 |
| 問36 |
| 問37 |
| 問38 |
| 問39 |
| 問40 |
問1
reモジュールについて説明している以下の文章のうち、正しいものを選べ
デバッグ機能を利用するためのモジュールである
機械学習アルゴリズムを用いたモデルを構築する際に使用するモジュールである
微分や積分などの高度な数式演算を行うためのモジュールである
正規表現を扱うためのモジュールである
問2
ポアソン分布について述べている以下の文章のうち、正しいものを選べ
ポアソン分布におけるパラメーターは、平均値と標準偏差である。
交通事故の発生回数の予測、機械部品の故障予測など、稀に生じる事象についてモデル化したい場合に用いられる、離散型の確率分布である。
二項分布における試行回数と平均値が∞に発散する場合の極限を計算することで、ポアソン分布の確率密度関数は得られる
確率変数の実現値が連続変数である連続型確率分布である。
問3
決定木の不純度の指標として使用される「ジニ不純度」の説明している以下の文章のXXXとYYYに当てはまる組みとして正しいものを選べ
ある2つのカテゴリー(ラベル0とラベル1)を持つ特徴量を分割する場合のジニ不純度は、ラベル0なのにラベル1と割り振られる確率とラベル1なのにラベル0と割り振られる確率のXXXを考える必要がある。クラス0である確率をP(0)、クラス1である確率をP(1)とすると、求めるジニ不純度は
となる
XXX = 和, YYY = 2
XXX = 積, YYY = 2
XXX = 積, YYY = 1/2
XXX = 和, YYY = 1/2
解説
ジニ不純度を求める考え方は説明文の通りです。適切な単語については公式の観点で説明をします。ジニ不純度を求める公式は下記のようになります。
「ラベル0なのにラベル1と割り振られる確率とラベル1なのにラベル0と割り振られる確率」とはつまり間違える確率です。発生する確率の反対が間違える確率ですので1から発生する確率を減算しています。2乗は式変換すると発生するものとなります。
問4
シグモイド関数について説明している以下の文章のうち、正しいものを選べ
ニューラルネットワークの活性化関数として使われる関数であり、この関数の出力は0より大きく1より小さい
ニューラルネットワークの活性化関数として使われる関数であり、入力に対して線形変換を施す
線形回帰を使用する際の仮定関数であり、これにより誤差が小さくなるように学習することができる
以下の数式で表される関数であり、この関数の出力は0以上1以下である
問5
Matplotlibの記述について間違っているものを選べ
1つの描画オブジェクトの中に、複数のグラフを表示させることはできない
グラフの判例を描画するだけでなく、その表示位置やフォント、文字サイズも変更することができる。
描画したグラフをpngファイルなどで保存することができる。
Matplotlibのコードには2種類あり、MATLABのように書くスタイルとオブジェクト指向に則ったスタイルがあるM
問6
以下のコードのXXXXの部分に当てはまるものとして正しいものを選べ
try:
with open('sample.txt', encoding='utf-8') as f:
txt = f.read()
f.close()
print(txt)
XXXX FileNotFoundError as err:
print("ファイルが存在しないため、読み込めませんでした。")
XXXX Exception as other:
print("ファイルが読み込めませんでした。")
exception
exceptional
except
reject
問7
A = (1,2,3) B = (4,5,6)の2つの座標がある。座標AB間のユークリッド距離として正しいものを選べ
27
9
3
問8
ブートストラップデータの説明として正しいものを以下の中から選べ
ランダムに復元抽出されたサンプルと特徴量のデータのこと
勾配ブースティング法の内部で保持している、誤差がもっとも大きかったサンプルのこと
予測への影響度がもっとも少ないサンプルのこと
サンプルからランダムに非復元抽出したデータのこと
問9
以下の不定積分の答えとして正しいものを選べ。Cは積分定数とする。
問10
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームにその日の株価の増減値(終値-始値)に応じて、ランクを付与するコードの実装として正しいものを選べ
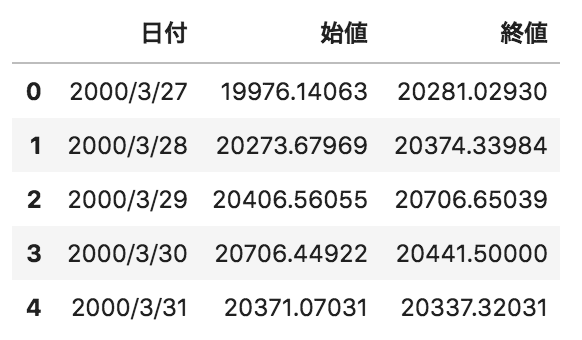
①
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df["増減値"].apply(add_rank)
②
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["増減値"] = df["終値"] - df["始値"]
df["ランク"] = df.add_rank(df["増減値"])
③
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply(add_rank(df["終値"] - df["始値"]))
④
def add_rank(value):
if value >= 1000:
return "High"
elif 0 <= value < 1000:
return "Normal"
else:
return "Low"
df["ランク"] = df.apply().add_rank(df["終値"] - df["始値"])
①
②
③
④
問11
datetimeモジュールについて説明している以下の文章のうち、誤っているものを選べ
取得する日付や日時のタイムゾーンを指定することができる
now()を使用することで、今日の日付を取得することができる
日数の差分を算出するなど、日付同士の演算をすることができない。
日時(datatime型)→文字列の変換はできるが、文字列→日時(datatime型)の変換はできない
問12
以下のコードの出力として正しいものを選べ
A = [x for x in range(10)]
B = {x for x in range(20)}
if len(A)==10:
print("A")
elif len(A)==10&len(B)==20:
print("A,B")
else:
print("None")
A
A, B
None
A A, B
問13
データエンジニアの役割について説明している以下の文章のうち、正しいものを選べ
データエンジニアはモデリングのみを担当することが多く、データの概要把握のためのデータ集計やデータ可視化を行うことはない。
データエンジニアが使用するツールはwindowsOSでしか動作しないものが多く、windowsOSを使わなければならない
データエンジニアはデータサイエンティストと連携して、予測モデルを構築するためのデータの前処理や抽出作業を行うことがある
データエンジニアはモデリングのみを担当することが多く、データの前処理を行うことはない
問14
以下のコードを実行した場合のBとCに格納されているデータの組み合わせとして、正しいものを選べ。選択肢は(B, C)の順に記載されている。
import numpy as np
A = np.eye(3)
B = np.count_nonzero(A)
C = np.sum(A)
(array([3]), array([3]))
(3, 3)
(True, 6)
(True, 3)
問15
pandasデータフレームdfをNumPy配列に変換する処理として正しいものを選べ
np.convert(df)
df.values
np.ndarray(df)
df.array
問16
scikit-learnのmetricsモジュールのclassification_report関数で出力されないものとして正しいものを選べ
AUC
適合率
再現率
F値
問17
matplotlibのhist()メソッドの引数に関する説明として間違っているものを選べ
最適なビンの数を決める手法を指定することができる
ビンの数を変更することができる
積み上げヒストグラムを描画することができる
相対度数分布を表示することができる
問18
以下のコードを実行した場合の出力として、正しいものを選べ。
import numpy as np
np.log(np.exp(np.eye(2)))
array([[ 0., -inf], [-inf, 0.]])
array([[2.71828183, 1. ], [1. , 2.71828183]])
array([[1., 0.], [0., 1.]])
array([[1., 1.], [1., 1.]])
問19
数値データが格納されたpandasデータフレームに対して、describeメソッドを用いて算出することができない統計量として正しいものを選べ
最大値
外れ値
平均値
データ件数
問20
以下のような出力をするコードとして正しいものを選べ
DatetimeIndex(['2020-01-01', '2020-01-02', '2020-01-03', '2020-01-04',
'2020-01-05', '2020-01-06', '2020-01-07', '2020-01-08',
'2020-01-09', '2020-01-10', '2020-01-11', '2020-01-12',
'2020-01-13', '2020-01-14', '2020-01-15', '2020-01-16',
'2020-01-17', '2020-01-18', '2020-01-19', '2020-01-20',
'2020-01-21', '2020-01-22', '2020-01-23', '2020-01-24',
'2020-01-25', '2020-01-26', '2020-01-27', '2020-01-28',
'2020-01-29', '2020-01-30', '2020-01-31'],
dtype='datetime64[ns]', freq='D')
pd.date(start=”2020-01-01”, end=”2020-1-31”)
pd.date_range(start=”2020-01-01”, end=”2020-1-31”)
pd.date_range([“2020-01-01”, “2020-1-31”])
pd.range(start=”2020-01-01”, end=”2020-1-31”)
問21
Matplotlibを用いて、1つの描画オブジェクト中に2つのグラフを表示するコードとして正しいものを選べ
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2)
plt.show()
①
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.show()
②
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
plt.show()
③
import matplotlib.pyplot as plt
plt.plot()
plt.show()
④
①
②
③
④
問22
サポートベクターマシンについて説明している以下の文章のうち正しいものを選べ
分類問題にのみ使えるアルゴリズムである
カーネルをrbfカーネルなどにすることで非線形構造を有するデータに対しても使用することができる
scikit-learnで実装されているサポートベクトルマシンを使う場合、サポートベクトルの数はハイパーパラメーターであり、任意に調整できる
教師なし学習のアルゴリズムである
問23
csvファイルをpandasで読み込む場合に、読み込むカラムを指定する方法として正しいものを選べ
※選択肢中の’data.csv’ は読み込む元データが格納されたcsvファイルとする
pd.read_csv(‘data.csv’, usecols=[カラム名])
pd.read_csv(‘data.csv’, index_col=[カラム名])
pd.read_csv(‘data.csv’, use_cols=[カラム名])
pd.read_csv(‘data.csv’, cols=[カラム名])
問24
Jupyter Notebookについて説明している以下の文章のうち、正しいものを選べ
単一行でセルを実行できることもあり、セル内で関数を作成することは良くない
単一のコードを実行できることもあり、後から見直した時のために、セルとセルの間には適度に、コメントを残すべきである
ノートブックが複数に別れていると面倒なので、ノートブックは長くても1つに納める方が良い
使っていないノートブックは自動でシャットダウンされるので、いくつでもノートブックを開くことは問題ない
問25
ファイルの入出力の際に使用する、open関数について説明している以下の文章のうち、間違っているものを選べ
ファイルの入出力の際に使用する文字列のエンコーディングを指定できる
open関数が扱えるファイルの拡張子は、txtのみである
open関数を用いる際には、ファイルの閉じ忘れを防ぐために、with文を併用するとよい
書き込み用でファイルを開く場合には、modeの引数に’w’を指定するとよい
問26
enjoyという出力を返すように、XXXXに当てはまるものとして正しいものを選べ
import re
pattern = r"enjoy"
text = "enjoy data science"
matchOB = re.match(pattern , text)
if matchOB:
print(matchOB.XXXX)
output()
group()
match()
search()
問27
scikit-learnのLogisticRegressionクラスを用いてモデルを構築した場合のラベルの予測確率を取得する関数として正しいものを以下の中から選べ
predict_proba()
predict()
get_params()
predict_log_proba()
問28
set型のデータに関して説明している以下の文章のうち、正しいものを選べ
標準のデータ型にはなく、使う場合はモジュールをインポートする必要がある
重複しない要素を含み、集合演算をする場合に用いられる
イミュータブルなデータ型であり、要素の追加や削除はできない
データの各要素が、keyとvalueという2組みのデータから成り立ち、それぞれ取り出すことができる
問29
A = (1,2,3) B = (4,5,6)の2つの座標がある。座標AB間のマンハッタン距離として正しいものを選べ
9
3
27
問30
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
問31
機械学習モデルについて説明している以下の文章のうち間違っているものを選べ
機械学習モデルでは、何かを分類するタスクしか解くことができない
ラベルではなく数値そのものを予測する問題を回帰問題という
データが大量に存在する場合にモデルを構築する際は、学習データ、検証データ、テストデータの3つに分割するのが理想である
異なる検証データで結果を比較するために、交差検証を実施することもある
問32
以下の行列の掛け算の答えとして正しいものを選べ
算出不可能(掛け算はできない)
問33
以下のような日付、日経平均株価の始値、終値が格納されたpandasデータフレームdfがある。このデータフレームを始値の降順に並び替えるコードとして正しいものを選べ
df.sort(“始値”, ascending=False)
df.sort(“始値”)
df.sort_values(“始値”)
df.sort_values(“始値”, ascending=False)
問34
scikit-learnのサポートベクターマシンのハイパーパラメーターのCについて説明している以下の文章のうち正しいものを選べ
Cの値が小さいほど、マージンは大きくなる
Cの値が大きいほど、マージンは大きくなる
C=Trueにすると、非線形の分類問題も境界線を求めることができるようになる
特徴量の数が大きいほど、Cの値も大きくする必要がある
問35
三角関数でないものを以下の選択肢から選べ
cosx
sinhx
tanx
sinx
問36
pandasのデータフレームの上から5行目までを表示させるメソッドとして、正しいものを選べ。
tail()
head()
view()
show()
問37
以下のような、pandasデータフレームAとpandasデータフレームBがある。この2つのデータフレームの日付が一致する部分のみを列方向に結合したデータフレームを作成するコードとして正しいものを選べ
A
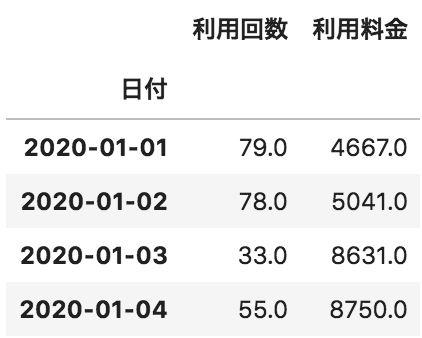
B
pd.merge(A, B, how=”left”, on=”日付”)
pd.join(A, B, how=”inner”, on=”日付”)
pd.merge(A, B, how=”inner”, on=”日付”)
pd.merge([A, B], how=”inner”, on=”日付”)
問38
決定木について説明している以下の文章のうち、正しいものを選べ
情報利得の大きい順に特徴量が使用され、木が作られる
木が下に行けば行くほど、特徴量の情報利得は大きい
各葉においてデータを分割する際の閾値はあらかじめモデル作成者が決める必要がある
欠損値は除外するか、何かしらの値で埋めておく必要がある
問39
Jupyter Notebookについて説明している以下の文章のうち、正しいものを選べ
セル上で、シェルコマンドを実行する際には’#’を行頭に入力する
セル上で、シェルコマンドを実行する際には’!’を行頭に入力する
セル上で、シェルコマンドを実行する際には’%’を行頭に入力する
セル上で、シェルコマンドを実行する際には’’を行頭に入力する
問40
以下のような日付ごとの利用回数と利用料金が格納されたpandasデータフレームdfがある。各利用回数が何日存在するかをカウントしたものをデータフレームとして出力するコードとして正しいものを選べ
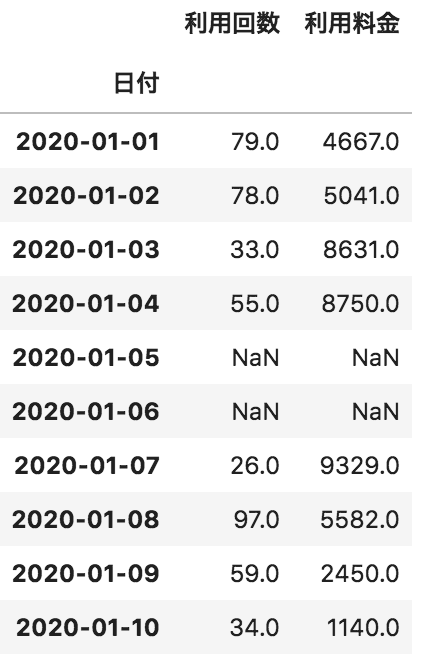
df[“利用回数”].value_counts()
df[“利用回数”].value_counts().to_frame()
df[“利用回数”].value_count().to_frame()
df[“利用回数”].count()